How do you know if a parameterization (e.g., µP) or a fitted Hyperparameter (HP) scaling law actually gives reliable transfer?
@MBarkeshli and I propose a three-metric framework to quantify the quality of transfer and use it to show that µP’s advantage over SP in Transformers trained with AdamW comes from training the embedding layer fast enough.
Below: speeding up the embedding LR in SP (SP+Embd) recovers µP-like transfer, and slowing it down in µP (µP-Embd) wrecks training with severe instabilities.
A thread 🧵
1/n
Almost all animals sleep. Why don’t LMs?
Introducing our new work on language model sleep.
tl;dr : A periodic, recurrent “sleep” phase allows LMs to digest their context and transfer it into their weights, improving recall and reasoning on challenging tasks.
This work from my colleague Jeffrey is a great examination on the failure cases of model-based verifiers and guardrails. Long-horizon tasks continue to be a challenge worth tackling.
Excited to share work from my internship at MSL @AIatMeta! 🚀
We analyze Critical Sharpness: a scalable curvature measure requiring only ~6 forward passes to analyze LLM training dynamics at scale.
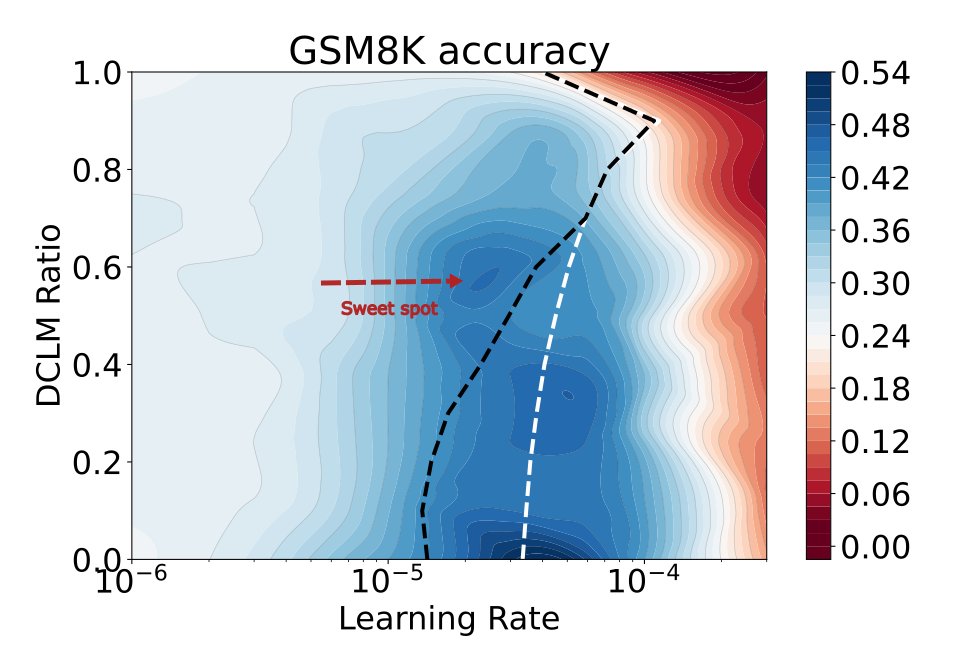
We extend this measure to introduce Relative Critical Sharpness, which measures the relative curvature between two landscapes. We use this to answer a major practical question: How much pre-training data should we mix during fine-tuning to avoid catastrophic forgetting?
🧵
(1/n)
Latent reasoning models show a lot of promise, but so far the research has explored training them from scratch.
My colleagues take the next step and explore how to turn pretrained language models into latent reasoning models:
Looped latent reasoning models like TRM, HRM, Ouro and Huginn are great for reasoning, but they’re inefficient to train at larger scales.
We fix this by post training regular language models into looped models, achieving higher accuracy on a per training FLOP basis.
📜1/7
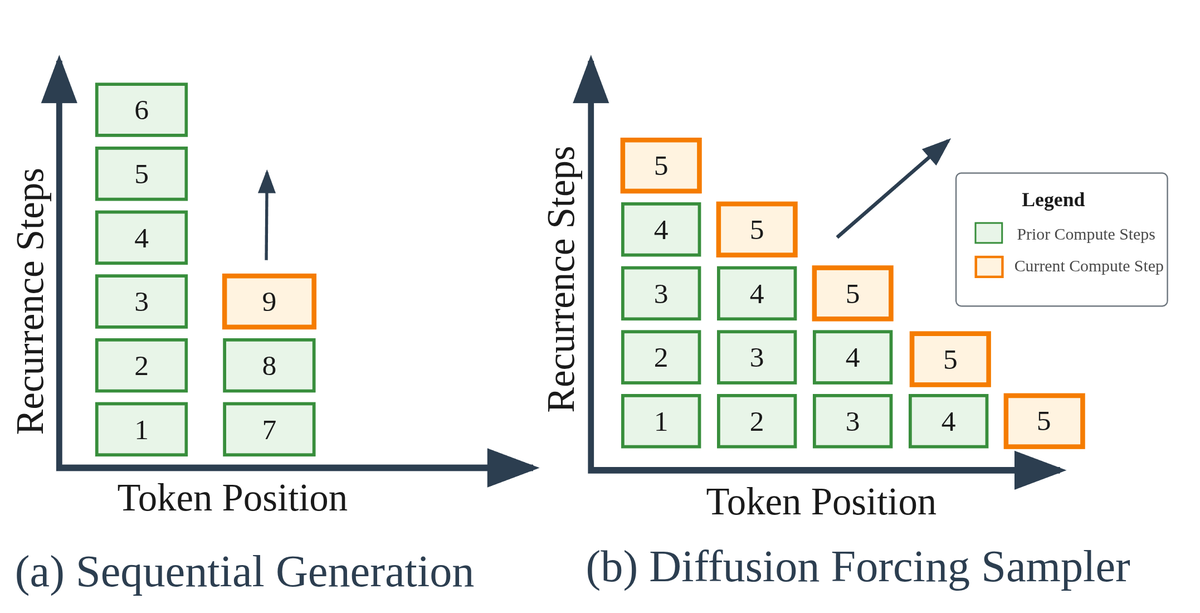
There's been a lot of discussion recently about parallel vs sequential reasoning.
The recurrent models we trained this year are sequential, which makes them good at math, but slow (see pic)
However, if you squint, models with recurrent-depth/loops are like diffusion models ...
In 2010, I came to the U.S. straight from undergrad for a PhD. Fifteen years later the map looks messy, but the line of best fit is clear. 🤍
2010 — PhD Year 1: my advisor said, “Take the ML course.” I had never heard of ML. With the most supportive, inspiring advisor, I pivoted from electronic communications and cognitive radio to MRFs, graphical models, and generative models—grounded by a solid foundation in signals and probability theory.
Year 3 – we moved into tensor methods. I went all in on unsupervised learning and spectral methods.
Before graduation – a year of internships across MSR Boston and Redmond on AI for healthcare. I was so lucky to work with the best researchers as mentors. But biology humbled me. Long nights, protein and cell-slice data, multithreaded pipelines. Progress crawled and the spark dimmed. I chose to keep a CS spine: applications are welcome when they sharpen the core.
Fresh out of grad school – I joined UMD faculty,then deferred a year to do a postdoc at MSR NYC. Online learning and RL paradise, ego check included. While others shipped papers, I went back to RL textbooks and rebuilt foundations in learning theory.
Back at UMD – I aimed for pure theory. Reality steered me to trustworthy AI, especially RL robustness. I also faced a truth: I missed the 2014 deep learning wave. That stung. It changed how I work.
2023 – LLMs arrived like a tide and I didn’t want to miss the wave again. I read restlessly, rallied my students, we pivoted and shipped.
2023 → now – we’re building toward foundation models for robotics: SMART, TACO, Premier-TACO, PRISE, Make-an-Agent, TraceVLA, FLARE, IVE, and more. The timing feels right. We’re going deep on robotics and physical intelligence. 🤖
What I’ve learned: careers have seasons. Adjust, ride the tide, and do not let the next wave leave you on the beach. If you’re mid-pivot too, I’m rooting for you — happy to swap notes. ✨
#Robotics #LLM #EmbodiedAI #PhysicalIntelligence #UMD #AcademicLife #ResearchJourney
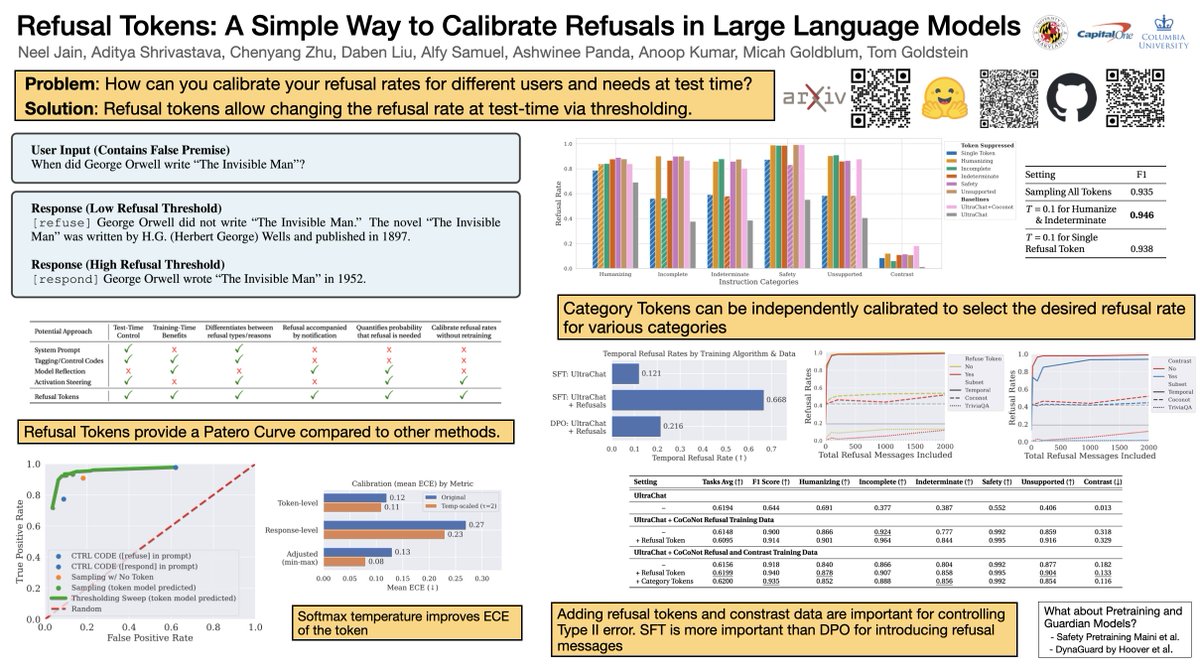
Excited to present Refusal Tokens at #COLM2025, Thursday morning at Poster #72, which explores managing refusal rates across different categories, as each category requires its own. Stop by to find out more!
Would LLMs ever *lie* to their users to prevent harm, instead of refusing harmful questions?
I hope you're not too tired of reading about LLM Deception this week, because here is our report on 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗰 𝗗𝗶𝘀𝗵𝗼𝗻𝗲𝘀𝘁𝘆 in LLMs, and how it complicates Safety Evals:
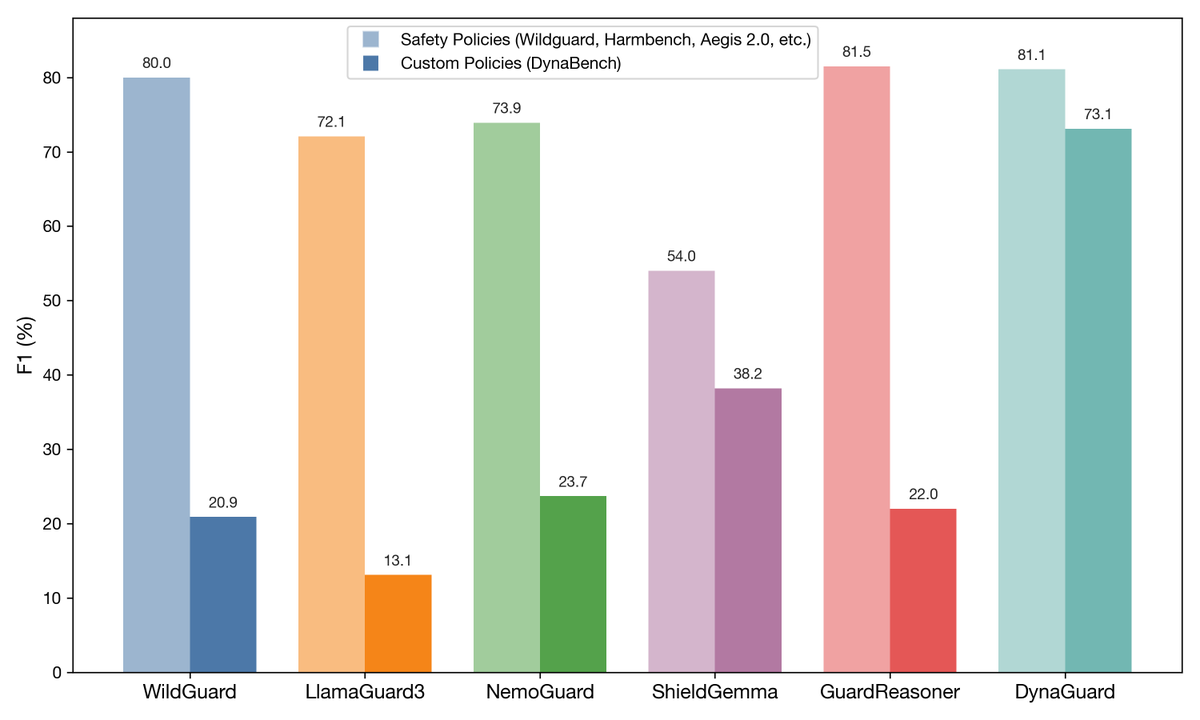
Our new guardian model lets you create LLM guardrails using natural text. This little 8B model efficiently checks in real time whether chatbots comply with bespoke moderation policies.
It's not often that academics beats industry models, but DynaGuard stacks up well!
Guardrails with custom polices are hard for models trained on safety and harm-related datasets. But what if you trained a guardian model on arbitrary rules?
Introducing DynaGuard, a guardian model for custom policies: https://t.co/oPWOZstRUQ
There is still a lot of brittleness in getting guardian models to incorporate custom policies, but we think this is a step in the right direction. Try out DynaGuard in this interactive demo (and give us feedback to improve it!): https://t.co/ZArEreMkpK
DynaGuard was trained on a dataset of 60k multiturn dialogue scenarios, each with a custom policy. These were generated with a deliberate process to encourage diversity in the scenarios. We release this dataset along with a benchmark for evaluating custom-policy performance.