أمازون (AWS) بالتعاون مع يوداستي فتحوا التقديم على منح شهادات نانو (Nanodegree) جديدة لتخصصات الذكاء الاصطناعي وهي:
- مبرمج ذكاء اصطناعي (AI Programmer)
- اخصائي أعمال الذكاء الاصطناعي الوكيلي (Agentic AI Business Professional)
- مهندس وكلاء ذكاء الاصطناعي (Agent Engineer)
البرنامج عن بعد ومدته 3 شهور، يبدأ في 4 أغسطس ويطلب التزام مرن. مناسب لحديثي التخرج أو المهتمين بتطوير مهاراتهم في الذكاء الاصطناعي والاطلاع على اخر التحديثات
آخر موعد للتقديم وتسليم المطلوب: 24 يونيو
فرصة رائعة وشهادة معترف بها، انصح بالتقديم
رابط التقديم:
https://t.co/xWW4NwMUbQ
تفاصيل أكثر في الرابط
في #عام_الذكاء_الاصطناعي 2026.. اطلع على مفهوم توسيع النماذج اللغوية الكبيرة الذي يُعد مساراً واعداً نحو الذكاء العام الاصطناعي.
للمزيد: https://t.co/Y8lfhclFTS
#سدايا
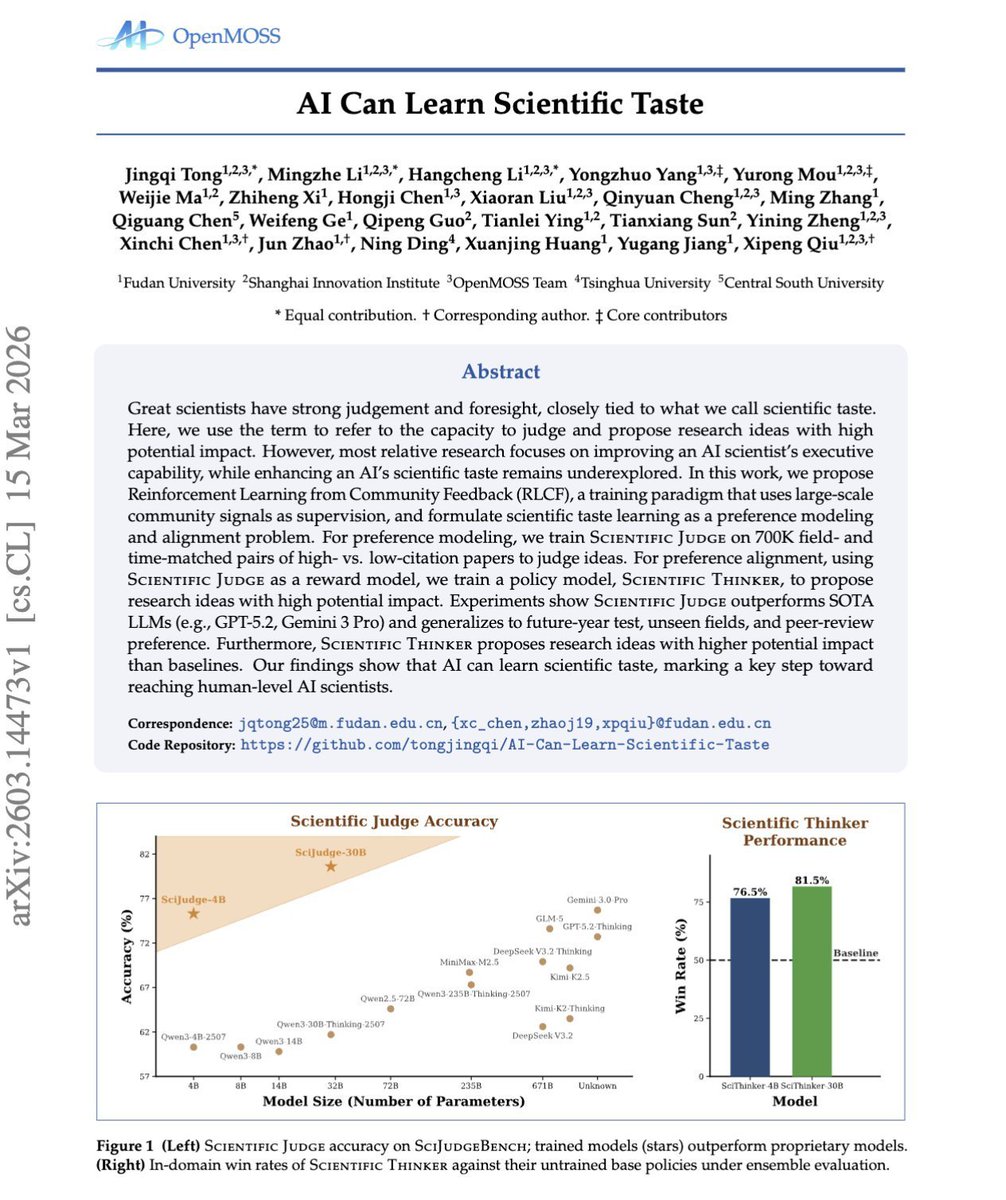
من أكثر الأوراق البحثية الرهيبة انتشارًا وحازت على تفاعل في مجتمع الذكاء الاصطناعي خلال الأيام الماضية ورقة من فريق OpenMOSS وباحثين من جهات مثل Tsinghua University
بعنوان:
AI Can Learn Scientific Taste
فكرة الورقة بسيطة لكنها ذكية: كثير من محاولات بالماضي عن عالم او باحث الذكاء الاصطناعي “AI Scientist” ركزت على التنفيذ والبحث والتجارب، لكن بقي جزء مهم ناقص وهو “الذوق العلمي” وهي قدرة النموذج على الحكم على الأفكار وتمييز ما لديه أثر حقيقي، ثم اقتراح فكرة بحثية لها قابلية عالية للانتشار والتأثير الحقيقي
الورقة تقترح طريقة تدريب جديدة لنماذج الذكاء الاصطناعي اسمها RLCF
Reinforcement Learning from Community Feedback
وهنا يظهر دور التعلم المعزز (RL) كأحد أهم مراحل التدريب الحديثة. في السنوات الأخيرة، مرحلة ما بعد التدريب (Post-training) صارت تعتمد أكثر على RL لأن الهدف لم يعد فقط “إجابة جيدة”، بل “سلوك أفضل” وتفضيلات أو معايير جودة واضحة.
بدل الاعتماد على تقييم بشري لكل حالة، تستفيد من إشارات المجتمع العلمي نفسه مثل الاستشهادات (citations) كإشارة تفضيل واعجاب واسعة النطاق من واقع سلوك الباحثين حول الأوراق المنشورة من منصات مثل arxiv
منهجية التدريب في الورقة (RLCF) تعتمد على نموذجين:
- نموذج “حكم” (Judge) يتعلم تفضيلات المجتمع عبر مقارنة ورقتين متشابهتين وتحديد أيهما أفضل بناء على إشارة الاستشهادات
- نموذج “مفكر” (Thinker) يولد أفكارًا بحثية متعددة، ثم يتم ترتيبها عبر مقارنات داخلية باستخدام الـ Judge المدرب وتحديث النموذج تدريجيًا
الورقة تقارن بين 3 طرق منتشرة اليوم لتعليم النموذج في ال RL “من أين يأتي معيار الإعجاب/التفضيل” الذي نُدرّب عليه النموذج: ، والفرق بينها ببساطة هو مصدر الإشارة التي نقيس بها:
- تدريب RLHF: المعيار يأتي من تقييم بشري مباشر (إعجاب/تفضيل الإنسان لنتيجة على أخرى)، ثم يتم تحسين النموذج بناءً عليه.
- تدريب RLCF: نفس الفكرة، لكن المعيار يأتي من إشارات المجتمع بدل أفراد، مثل الاستشهادات citations، فيعكس “إعجاب/تفضيل المجتمع” على نطاق أوسع.
- تدريب GRPO: هذه ليست “مصدر المعيار”، بل طريقة تدريب RL تعتمد على مقارنة عدة مخرجات داخل نفس الدفعة وتحديث النموذج بناءً على المقارنات، وتُستخدم هنا لتدريب الـ Judge ثم تحسين الـ Thinker.
أمثلة سريعة أين يمكن تطبيق نفس الفكرة خارج الأوراق العلمية:
- تدريب نماذج المحتوى من “إشارات المجتمع” مثل أكثر المنشورات مشاركة وحفظًا وتفاعلًا على منصات التواصل. (X / LinkedIn / TikTok)
- تدريب نماذج التوصية/الترتيب من “إشارات المجتمع” مثل أعلى تقييمات المنتجات أو أكثر الإجابات اعتمادًا وفائدة في منصات المطورين
إذا كنت تخطط لفكرة بحثية في مجال Agents و RL أو تبني وكيل ذكي داخليًا داخل جهة عملك أو فريقك فهذه الورقة مرجع ممتاز وتستحق القراءة
هذا ملخص مختصر جدًا للفكرة، والورقة نفسها فيها تفاصيل وتجارب وأفكار إضافية تستحق القراءة:
https://t.co/d8R6ik3o1s
في دراسة "مشتريات الذكاء الاصطناعي في القطاع الحكومي"، تستعرض #سدايا مبادرات المملكة المساندة لمشتريات الذكاء الاصطناعي.
#عام_الذكاء_الاصطناعي
https://t.co/4URmBteozv
مع كثرة التطورات السريعة وانتشار الأبحاث في الذكاء الاصطناعي خصوصًا في التعلم المعزز (RL) وعالم الوكلاء (Agents) وانتشارهم بشكل سريع هذه السنة ووضوح قيمتهم المضافة في أدوات بدأت تدخل الاستخدام اليومي مثل Claude Code و Codex و Cursor صار من الصعب تتبّع كل شيء أو فهم وش قاعد يصير فعلاً هل نحن ما زلنا نطوّر نماذج تُجيب فقط أم أننا ننتقل إلى أنظمة تتصرّف وتتعلم عبر الزمن
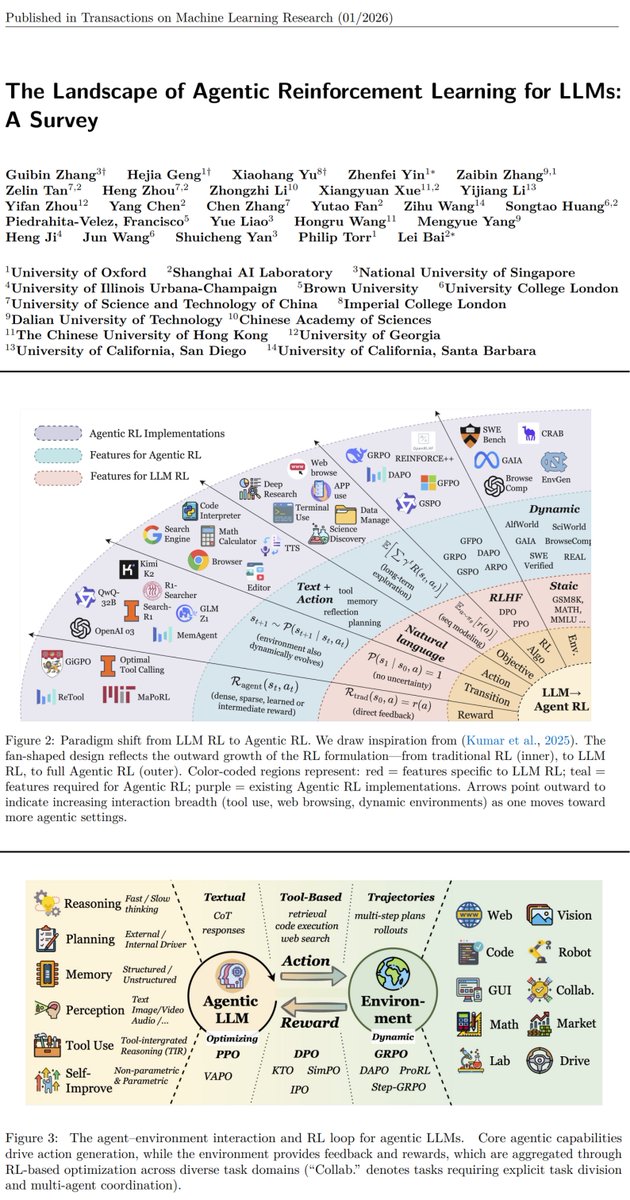
وجاءت ورقة مرجعية رهيبة أقرب إلى كتاب تعليمي من باحثين في جهات مثل University of Oxford و Shanghai AI Laboratory و National University of Singapore وتجمع الصورة بشكل واضح حول التحوّل من نماذج تُجيب إلى وكلاء ذكيين Agents يخطّطون ويتفاعلون ويتعلّمون عبر الزمن باستخدام التعلم المعزز(RL) لتدريب نماذج وكيلية (Agentic)
اسم الورقة:
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
مراجعة مرتّبة أكثر من 40 صفحة تلخص الاتجاه الحالي بشكل عملي وتركّز على:
- الفرق بين تحسين إجابة واحدة وبين تحسين سلوك كامل عبر سلسلة خطوات وقرارات داخل بيئة
- أهم قدرات الوكيل التي يتم التركيز عليها اليوم مثل التخطيط واستخدام الأدوات والذاكرة والمراجعة الذاتية
- أهم البيئات والاختبارات والأطر المستخدمة لتقييم الوكلاء بشكل قابل للمقارنة
- كيف يتم تدريب الوكلاء عمليًا باستخدام RL على سيناريوهات حقيقية بدل الاعتماد على Prompts ثابتة فقط
- وتغطي نطاقًا واسعًا جدًا من الأعمال الحديثة في المجال أكثر من 500 عمل
العمل هذا يختصر وقت وجهد كبير لكل مهتم ويساعد في ربط بين المفاهيم والاتجاهات بدل متابعة كل ورقة بشكل منفصل
إذا كنت تخطط لفكرة بحثية في مجال ال Agents او ال RL أو تبني وكيل ذكي داخليًا داخل شركتك أو فريقك فهذه الورقة مرجع ممتاز وبصراحة تستحق القراءة كاملة لأنها تختصر عليك وقت كبير وتوضح لك الصورة من البداية للنهاية
رابط البحث:
:https://t.co/k8HccuerJa
عسير التي أعتبر نفسي جزءًا منها.. أراها اليوم تزداد بهاءً تحت إدارة صاحب السمو الملكي الأمير تركي بن طلال بن عبدالعزيز، أمير المنطقة، الذي لا يتوانى عن خدمة عسير وأبنائها، وبناء مستقبلها الواعد بتوجيهات قيادتنا الرشيدة -حفظها الله-.
وضمن جهود هيئة تطوير منطقة عسير @asda_aseer برئاسة سموه، وباستراتيجيتها ومشاريعها المباركة، تأتي المبادرات المشتركة مع مختلف قطاعات الفروسية، بالتباحث لدراسة مستقبل تأسيس رياضات الفروسية في المنطقة، بما يليق بتاريخ «المقر»، الدليل الأقدم لاستئناس الخيول في العالم.
الرئيس التنفيذي لـ Linear يصف ما يحدث بأنه أكبر تحوّل في بنية فرق المنتج منذ Agile.
لعقود، كان عمل المنتج يسير بهذا الشكل:
مدير المنتج يكتب المتطلبات → المصمّم يحوّلها لمواصفات → المهندس يترجمها إلى كود.
خطوة “الترجمة” في المنتصف كانت تستهلك ~70٪ من الوقت، وهي مصدر أغلب التأخير.
ولأن خطوة الترجمة ستتقلص بشكل كبير بسبب الذكاء الاصطناعي ، سينتقل الضغط إلى مرحلتين:
1. في البداية: كتابة المتطلبات وتحويلها إلى intent تفهمها الـ coding agents
2. •في النهاية: مراجعة مخرجات ال agents، الاختبار، والإطلاق
كتابة الكود لم تعد مركز الحرفة..الحرفة الجديدة هي صياغة النية intent ، توفير السياق، وتوجيه التنفيذ.
مقابلة عظيمة جداً انصح اي مهتم بالإقتصاد او الذكاء الإصطناعي بمتابعتها، Gavin Baker طرحه جميل و تسلسله الفكري يشدك طول فترة المقابلة، عدة مواضيع تم تناولها و من ضمنها:
- كلما انخفضت تكلفة الذكاء الاصطناعي، سيزداد الطلب عليه بشكل كبير، مما يفتح استخدامات جديدة بدلاً من تقليصها
- الذكاء الاصطناعي تجاوز مرحلة تطوير النماذج إلى مرحلة التوسع و التطبيق العملي
- حرب البنية التحتية و الحوسبة بين العمالقة و الصين
https://t.co/o78MbR4aVQ
علي بن أبي طالب -رضي اللّهُ عنه - يقول:
"نصف العافية بالتغافل"
وكان البدو يقولون قديمًا:
"دام تمشي، مشها."
التغافل أنضج مراحل الحياة،
فهو أن تدري عن الزلة وتسكت عن الرد.
ويُقال أيضًا:
"لولا التغافل عن أشياء نعرفها، ما طاب عيش ولا دامت مودات."
You are a safe haven for everyone around you:
Despite your constant anxiety, the storms raging within you, and your continuous attempts to escape, you were always a refuge for others. As if you take revenge on your anxiety by granting them reassurance.
مقالة مهمّة رائعة نُشرت بعنوان
The Roadmap of Mathematics for Machine Learning
تقدّم خريطة واضحة لفهم وتعلّم اساس الرياضيات خلف تعلّم الآلة والذكاء الاصطناعي، بدون الدخول في تعقيد أكاديمي أو تشتيت بين مصادر كثيرة
المقال يربط بشكل مباشر بين الرياضيات والتطبيق العملي، ويوضّح كيف أن:
الجبر الخطي يصف النماذج،
التفاضل والتكامل يساهم في تدريبها،
ونظرية الاحتمالات تربط كل شيء ببعضه.
المميز فيه أنه لا يحاول تغطية كل شيء، لكن يركز على الاتجاه الصحيح والاهم:
ماذا تتعلّم، ولماذا، وكيف تبني وتطور فهم تراكمي يخدمك سواء كنت مبتدئًا أو تعمل بالفعل في المجال فانها ممتازة كمراجعة وإعادة ترتيب الأساسيات
المقال مناسب لأي شخص يريد فهم أعمق لما يحدث “خلف الكواليس” في نماذج تعلّم الآلة والنماذج اللغوية، ويصلح كمرجع طويل المدى أثناء التعلّم
رابط المقال:
https://t.co/NdDLxO5Pjv











![KirkDBorne's tweet photo. #DeepLearning with PyTorch...
1) Cheat sheet [PDF]: https://t.co/TcRqfgrdEi
2) Learn fundamentals with hands-on coding [PDF]: https://t.co/IsXFjwW86S
3) #GenerativeAI with Python and PyTorch: https://t.co/hfbERRkGZ2 book v/ @PacktDataML https://t.co/DTQNkIqh0F](https://pbs.twimg.com/media/G72IJ3bX0AA5HrV.jpg)
![KirkDBorne's tweet photo. #DeepLearning with PyTorch...
1) Cheat sheet [PDF]: https://t.co/TcRqfgrdEi
2) Learn fundamentals with hands-on coding [PDF]: https://t.co/IsXFjwW86S
3) #GenerativeAI with Python and PyTorch: https://t.co/hfbERRkGZ2 book v/ @PacktDataML https://t.co/DTQNkIqh0F](https://pbs.twimg.com/media/G72EF3iXcAActoC.jpg)














![KirkDBorne's tweet photo. #DeepLearning with PyTorch...
1) Cheat sheet [PDF]: https://t.co/TcRqfgrdEi
2) Learn fundamentals with hands-on coding [PDF]: https://t.co/IsXFjwW86S
3) #GenerativeAI with Python and PyTorch: https://t.co/hfbERRkGZ2 book v/ @PacktDataML https://t.co/DTQNkIqh0F](https://pbs.twimg.com/media/G72INSIXMAItI00.jpg)






























