We just launched Canada’s new AI Strategy: AI For All.
We’re taking control of our future — with AI that’s governed by Canadian values, AI that’s accountable to Canadians, and AI that serves all Canadians.
📝 Unlocking the Working Memory of Large Language Models for Latent Reasoning
We have different methods for adding reasoning to LLMs right now. Chain-of-thought makes a model write its thinking in words. Coconut keeps the thinking hidden as vectors instead of text. But Coconut still builds those hidden thoughts one step at a time. This new approach changes the game by giving the model memory slots to think in directly.
RiM adds extra tokens that acts as fixed memory blocks to the input. The block is just a sequence of special tokens. A block looks like:
<b> <m> <m> </b>
The paper usually uses 2 <m> tokens per block, plus the boundary tokens <b> and </b>. So the input might look like:
Question tokens
<b> <m> <m> </b>
<b> <m> <m> </b>
<b> <m> <m> </b>
Answer prefix
The model processes this whole sequence with the transformer. Each token gets a hidden representation at every layer. The hidden representations of the <m> tokens are what act as the “memory.”
I see RiM a bit like using a [CLS] token (in BERT-like models), where the token captures information from the whole text and can be used for classification. Instead of using one token, RiM uses several memory tokens as thinking slots. These memory tokens capture useful hidden information before the model gives the final answer.
RiM is trained in two broad stages. First, the model learns to use memory tokens by predicting hidden reasoning steps from them. Then, it stops focusing on reasoning steps and learns to use those memory tokens to predict the final answer directly.
RiM showed strong results while keeping inference fast. On GSM8K, it improved over Coconut from 31.1% to 33.6% with GPT-2, 36.9% to 42.1% with Llama-3.2-1B, and 41.3% to 48.8% with Llama-3.2-3B. On GSM-Hard, it also improved over Coconut from 7.1% to 7.8%, 8.5% to 10.5%, and 10.2% to 12.0% across the same models. The biggest advantage is speed: RiM had almost the same latency as direct answering, while Coconut was about 7× slower and full chain-of-thought was about 27× slower.
Got the Pro, just because it would've take 1.5 months for them to make the air with 32GB RAM... Happy with the decision though, Pro's screen is amazing!
📝 MeMo: Memory as a Model
RAG systems help LLMs find grounding information, but they can struggle when the answer is spread across many documents. They can also be confused by irrelevant or noisy retrieved text. This paper proposes MEMO, which trains a separate memory model to store and connect knowledge so the main LLM can answer more accurately.
The authors say MEMO has several benefits. It can connect information across different documents, handle noisy or unrelated retrieved text, and avoid forgetting old knowledge. It can also work with closed-source LLMs because it does not need access to their weights or logits, and its retrieval cost does not grow with the corpus size because the MEMORY model stays fixed in size.
It uses two models. The MEMORY model is a smaller model that learns and stores information from the documents. The EXECUTIVE model is the main LLM, which stays frozen and asks the MEMORY model for useful information before making the final answer.
How does it work?
The novelty is that MEMO turns the document corpus into “reflections,” which are synthetic question-answer pairs about facts, entities, and links across documents. These reflections are used to train a MEMORY model, which the paper builds with Qwen2.5-14B-Instruct. At inference time, the EXECUTIVE model does not ask the MEMORY model only one question. Instead, it breaks the user’s question into smaller parts, checks facts, finds important entities, asks follow-up questions, and then writes the final answer.
The approach was tested with both open-source models, like Qwen2.5, and a closed-source model, Gemini-3-Flash, as the EXECUTIVE model, showing that it can work in both settings.
Focusing on Gemini-3-Flash, MEMO gets 53.58% on NarrativeQA, much higher than HippoRAG2 at 23.21% and NV-Embed-V2 at 26.62%. On MuSiQue, MEMO gets 60.20%, beating HippoRAG2 at 57.00% and NV-Embed-V2 at 46.60%.
You mean the workload? I am kinda curious because Pro supposed to be the better option, but a maxed-out Air, is basically the same as base Pro… The only difference is the fan! The way I see it, Air is a more portable option with slightly higher RAM… Unless there is something I am missing!
📝 Autogenesis: A Self-Evolving Agent Protocol
AI agents usually use fixed prompts, fixed tools, and manual updates. This made them hard to improve, fragile in new situations, and dependent on human engineers for changes. Autogenesis is interesting because it lets agents safely improve themselves over time by learning from mistakes and updating their own resources automatically.
The system uses multiple specialized agents to solve tasks while continuously tracking their performance, decisions, and failures. A self-evolution loop then reflects on mistakes, improves prompts/tools/agent logic, tests the updates, and safely keeps only the better versions.
This approach is like building a DevOps engineer, QA system, and prompt engineer directly into the agent framework itself. Specialized agents handle tasks, while the self-evolution system monitors failures, tests improvements, and updates prompts, tools, or code automatically. This allows the entire agent system to continuously improve itself safely instead of relying on humans to manually fix problems.
I won’t go into the full technical details, but the paper shows strong improvements across major benchmarks. For example, it reports up to 71% gains on AIME24 math tasks, 12.6% higher GAIA agent performance overall, and coding pass-rate improvements of 10–27% across multiple programming languages.
This could help future AI systems become more independent, adaptable, and reliable by allowing them to continuously improve their own prompts, tools, and behaviors over time without needing constant human engineers to manually update them.
📝 LLMs Corrupt Your Documents When You Delegate
People now use AI to help with work like writing, coding, and editing files. Many users trust AI to make changes without checking every detail. This creates a new way of working where AI acts like a delegate.
This paper by Microsoft researchers studies whether AI can safely handle long editing jobs without damaging documents. The authors test if models can keep files correct after many repeated tasks. They want to measure trust in real professional workflows.
They built DELEGATE-52, a benchmark with 52 work domains and many real documents. The models complete forward and reverse editing tasks over many rounds. The researchers compare the final files to the originals to measure damage.
The benchmark includes realistic professional tasks like editing code, spreadsheets, accounting records, scientific files, creative documents, and many other complex domain-specific files.
After 20 interactions, Gemini 3.1 Pro performed best with an 80.9% reconstruction score, meaning it still lost about 19% of document integrity. Claude 4.6 Opus scored 73.1%, while GPT-5.4 reached 71.5%, showing even top frontier models corrupted roughly 20–30% of content. Across all tested models, average document quality dropped by about 50%, and weaker models like GPT-4o fell to just 14.7%, revealing severe long-term reliability problems.
Paper: https://t.co/0Vkg8MPRRw
Code: https://t.co/CtDXjOFFQK
It seems that an older version of this paper was released under the "LightMem" title... (https://t.co/pAtel4vU7g) Didn't get a chance to read and see the improvements/differences.
📝 StructMem: Structured Memory for Long-Horizon Behavior in LLMs
Memory is important in chatbots because it helps them remember past conversations and respond better over time. This paper offers a new way to store memory by organizing events and their relationships instead of just saving separate facts.
Flat memory stores facts separately, which makes it fast but loses connections between events, while graph-based memory keeps structure but is complex, slow, and can introduce errors.
This paper proposes a new approach that stores conversations as events and then combines related events over time to build useful summaries.
First, Event-level binding turns each message into a small “event” by extracting what happened and how people relate in that moment. It then links all this information together with a timestamp so it can be retrieved as one coherent unit later.
Then, Cross-event consolidation collects recent events in a buffer instead of processing them one by one. When the buffer fills up, it looks for related past events and combines them to find connections across time. It then creates and stores a summarized version of these connections so future questions are easier to answer.
StructMem combines both the summarized knowledge and the original events during retrieval so the model can use high-level insights together with detailed evidence.
This approach improves accuracy by achieving about 76.8% overall performance (~2% increase compared to baseline), with clear gains in temporal and multi-hop reasoning.
At the same time, it greatly reduces cost, using around 1.9M tokens compared to systems like Mem0g that use over 35M tokens, and requiring far fewer API calls. Overall, it gives better reasoning while being much more efficient, making it faster and cheaper to run.
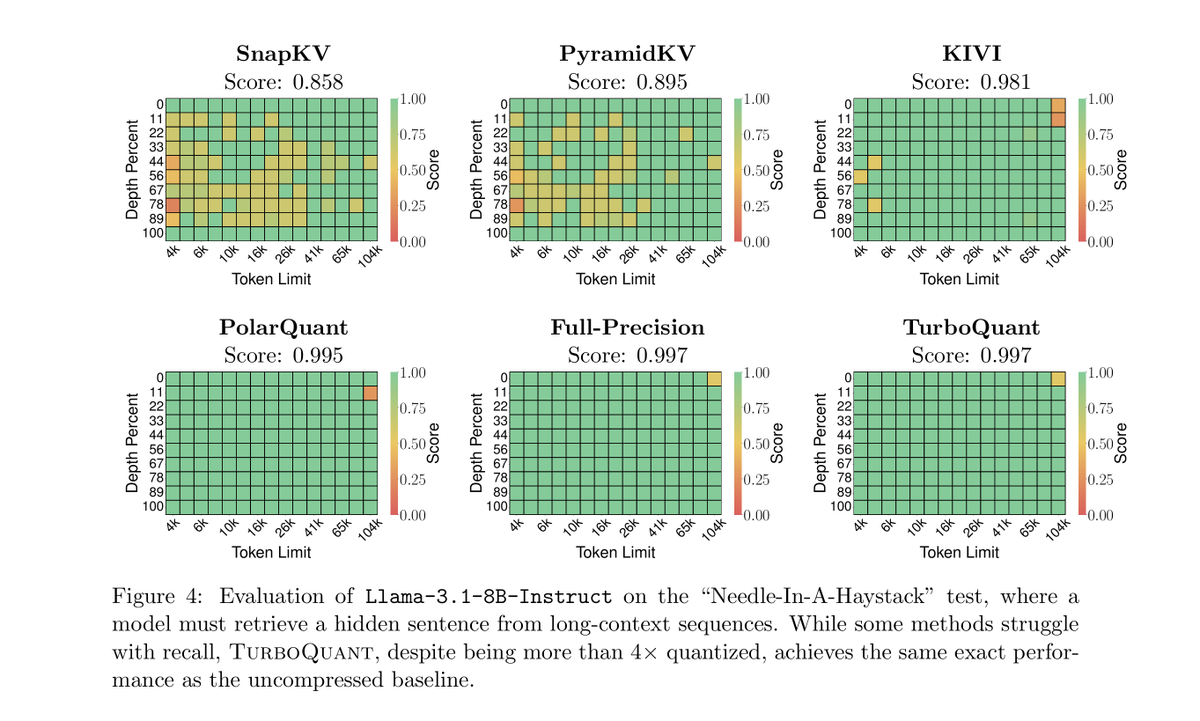
📝 TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
As we know, the attention memory grows with context length, creating a significant memory bottleneck. TurboQuant introduces a vector quantization compression technique for embeddings (such as those used in attention), while preserving their key properties like distances and inner products.
This has a significant impact!
How did they achieve it? I won’t pretend to understand all the math, but here’s a simple overview.
They first randomly rotate the vectors to spread information evenly across all dimensions. Then they quantize each coordinate separately using simple, efficient rules.
It means they turn a complex high-dimensional problem into many small, simple ones that are easier to handle. As a result, they can compress data a lot while still keeping the important relationships between vectors accurate.
In LLMs, this means you can shrink the KV cache significantly, enabling longer context windows and faster inference without hurting quality. In RAG systems, it allows storing and searching embeddings much more efficiently, improving scalability while keeping retrieval accuracy high.
TurboQuant achieves near-optimal compression, staying very close to the theoretical best possible error. It can compress KV cache by more than 4–5× while maintaining almost no loss in model quality.
In long-context tests (Needle in a Haystack), it matches full-precision models even under heavy compression. It also improves nearest neighbor search accuracy while making indexing extremely fast.
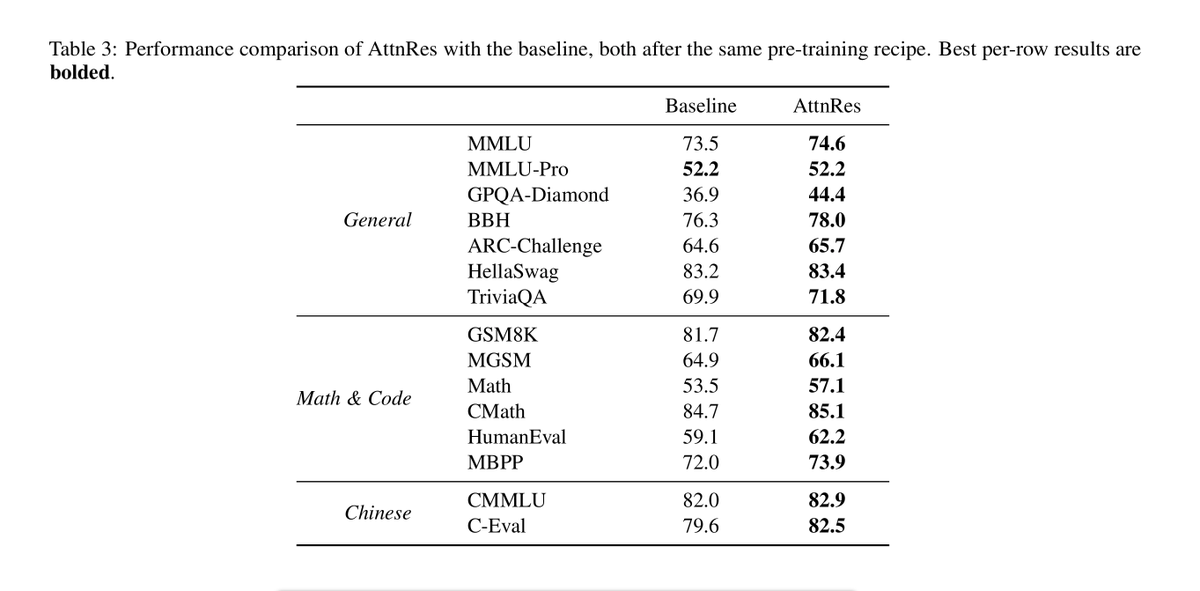
📝 Attention Residuals
In Transformer residual connections, all previous layer outputs are summed up with equal weight, and this simple accumulation can cause issues. This paper proposes applying attention over layers, just like attention over tokens, so each layer can selectively use past representations.
The issues with the current method are that hidden states grow with depth, causing values to become increasingly large and unstable. Earlier layer information also gets diluted, and the model cannot selectively focus on the most useful layers.
The new approach replaces residual addition with attention over layers, allowing each layer to weigh previous layers based on relevance. This lets the model selectively aggregate useful information instead of treating all layers equally.
However, attending to all previous layers introduces significant memory and communication overhead at scale. This makes it inefficient for large models and distributed training.
"Block attention" addresses this by grouping layers into blocks, where standard residual connections are still used within each block. The model then applies attention over these blocks, reducing cost while preserving most of the benefits.
The method enhances training stability by maintaining bounded hidden-state magnitudes and distributing gradients more evenly across layers. It is also more compute-efficient, with Block AttnRes matching the performance of a baseline trained with about 1.25× more compute.
Across model sizes, it consistently achieves lower validation loss (e.g., ~1.870 vs. 1.891 at similar compute). Overall, it yields better scaling behaviour with improved loss curves at every compute budget.


![NLPiation's tweet photo. 📝 Unlocking the Working Memory of Large Language Models for Latent Reasoning
We have different methods for adding reasoning to LLMs right now. Chain-of-thought makes a model write its thinking in words. Coconut keeps the thinking hidden as vectors instead of text. But Coconut still builds those hidden thoughts one step at a time. This new approach changes the game by giving the model memory slots to think in directly.
RiM adds extra tokens that acts as fixed memory blocks to the input. The block is just a sequence of special tokens. A block looks like:
<b> <m> <m> </b>
The paper usually uses 2 <m> tokens per block, plus the boundary tokens <b> and </b>. So the input might look like:
Question tokens
<b> <m> <m> </b>
<b> <m> <m> </b>
<b> <m> <m> </b>
Answer prefix
The model processes this whole sequence with the transformer. Each token gets a hidden representation at every layer. The hidden representations of the <m> tokens are what act as the “memory.”
I see RiM a bit like using a [CLS] token (in BERT-like models), where the token captures information from the whole text and can be used for classification. Instead of using one token, RiM uses several memory tokens as thinking slots. These memory tokens capture useful hidden information before the model gives the final answer.
RiM is trained in two broad stages. First, the model learns to use memory tokens by predicting hidden reasoning steps from them. Then, it stops focusing on reasoning steps and learns to use those memory tokens to predict the final answer directly.
RiM showed strong results while keeping inference fast. On GSM8K, it improved over Coconut from 31.1% to 33.6% with GPT-2, 36.9% to 42.1% with Llama-3.2-1B, and 41.3% to 48.8% with Llama-3.2-3B. On GSM-Hard, it also improved over Coconut from 7.1% to 7.8%, 8.5% to 10.5%, and 10.2% to 12.0% across the same models. The biggest advantage is speed: RiM had almost the same latency as direct answering, while Coconut was about 7× slower and full chain-of-thought was about 27× slower.](https://pbs.twimg.com/media/HJnGXS8WsAooXb3.jpg)
















![NLPiation's tweet photo. 📝 Unlocking the Working Memory of Large Language Models for Latent Reasoning
We have different methods for adding reasoning to LLMs right now. Chain-of-thought makes a model write its thinking in words. Coconut keeps the thinking hidden as vectors instead of text. But Coconut still builds those hidden thoughts one step at a time. This new approach changes the game by giving the model memory slots to think in directly.
RiM adds extra tokens that acts as fixed memory blocks to the input. The block is just a sequence of special tokens. A block looks like:
<b> <m> <m> </b>
The paper usually uses 2 <m> tokens per block, plus the boundary tokens <b> and </b>. So the input might look like:
Question tokens
<b> <m> <m> </b>
<b> <m> <m> </b>
<b> <m> <m> </b>
Answer prefix
The model processes this whole sequence with the transformer. Each token gets a hidden representation at every layer. The hidden representations of the <m> tokens are what act as the “memory.”
I see RiM a bit like using a [CLS] token (in BERT-like models), where the token captures information from the whole text and can be used for classification. Instead of using one token, RiM uses several memory tokens as thinking slots. These memory tokens capture useful hidden information before the model gives the final answer.
RiM is trained in two broad stages. First, the model learns to use memory tokens by predicting hidden reasoning steps from them. Then, it stops focusing on reasoning steps and learns to use those memory tokens to predict the final answer directly.
RiM showed strong results while keeping inference fast. On GSM8K, it improved over Coconut from 31.1% to 33.6% with GPT-2, 36.9% to 42.1% with Llama-3.2-1B, and 41.3% to 48.8% with Llama-3.2-3B. On GSM-Hard, it also improved over Coconut from 7.1% to 7.8%, 8.5% to 10.5%, and 10.2% to 12.0% across the same models. The biggest advantage is speed: RiM had almost the same latency as direct answering, while Coconut was about 7× slower and full chain-of-thought was about 27× slower.](https://pbs.twimg.com/media/HJnHInwWAAQ3hJZ.jpg)