Rubin Ultra dropping HBM4E from 16-Hi to 12-Hi looks like a downgrade but makes wafer math worse. Each stack holds less capacity (36GB vs 48GB), so each GPU needs more stacks to hit the same 576GB, 16 units instead of 12. That’s 33% more HBM packages consuming roughly the same wafer area per unit. Net effect: more wafers eaten by HBM, less left for conventional DRAM. The reason , hybrid bonding yields are terrible, also means this isn’t getting fixed in 2027. Same SOCAMM playbook: spec goes down, total demand goes up, shortage deepens.
LMAO
Rubin Ultra's HBM literally got downgraded to 12 Hi, and they are not even using HB yet
They won't use 16 Hi in 2027
Hybrid Bonding is very expensive for HBM rn (yields are abysmal)
The big near-term upside for BESI is that TSMC's COUPE & Tower use Hybrid Bonding for EIC + PIC integration for CPO
Everyone’s debating whether AI has enough use cases beyond coding copilots to justify trillion-dollar capex. Meanwhile, China already answered the question , and nobody noticed.
55% of China’s token consumption is AI video generation. Not enterprise agents. Not AGI. Short dramas, e-commerce ads, marketing content. Seedance 2.0 produces video at $0.14/second. 400+ AI dramas go live daily. Sora died because it priced for perfection. Chinese models survived because they priced for production.
This is the second inference demand curve the market hasn’t modeled yet. Same GPUs, same HBM, same power infrastructure, completely different buyer.
The capex bull case just got a second engine. Wall Street just hasn’t translated the Chinese data yet.
Most AI analysis stops at “are tokens profitable?” That’s only layer 1. There are four layers to AI profitability, and right now only the first one and a half have been proven.
Layer 1: Inference gross margin. GPU runs tokens, tokens generate revenue. Chip iteration is driving compute cost down 60-70% annually while frontier API pricing holds or rises. This scissors effect crossed in H1 2026 — Anthropic posted its first-ever operating profit. This layer is real, quantifiable, and being validated in real time.
Layer 2: Lab-level profitability. Gross profit minus training costs, R&D, and opex. Here’s the part the market doesn’t want to talk about: each generation of frontier models costs exponentially more to train, and each model depreciates in 6-12 months. Whether inference profits can cover next-gen training capex determines if labs ever reach positive free cash flow. The math barely works today. No margin of safety.
Layer 3: Customer ROI. Does $1 of AI spend save or generate more than $1? Today’s dominant path is headcount replacement — a coding agent costs $13/day vs. $300/day for a human engineer. Clear ROI. But it’s a one-time gain. Once you’ve cut the people you can cut, sustainable ROI requires productivity acceleration and new revenue creation — both harder to measure, slower to materialize, and tougher to sell to a CFO.
Layer 4: Macro productivity. All enterprise AI gains aggregating into GDP-level productivity growth. Most important layer, but most lagging — takes 12-24 months to show up in data, and attribution is nearly impossible.
Where we are now: Layer 1 is proven. Layer 2 just turned positive but fragile. Layer 3 is transitioning from wave one (cutting heads) to wave two (boosting output). Layer 4 is still a projection.
Trillion-dollar valuations and hundred-billion-dollar capex cycles are priced on all four layers holding simultaneously. Only the first one and a half have been confirmed. Each layer up, certainty decreases while capital commitment increases.
Whether this chain holds together comes down to one question: can AI capability unlock a new TAM tier every 12-18 months, or does the cycle stall once the first wave of layoff-driven savings is exhausted?
#MU#DRAM While everyone watches supply, the real variable is demand
For the past thirty years, the memory cycle has followed the same script: prices rise, all three manufacturers expand capacity together, new supply comes online, oversupply follows, prices collapse. In this script, demand was always the stable backdrop. PCs, smartphones, and servers fluctuated only modestly year to year. What actually drove the booms and busts was the collective overreaction on the supply side. So the entire industry was trained to watch supply: when do new fabs come online? When does capacity ramp?
That mental model used to be correct. But this cycle, demand has become the main character for the first time. The explosion in AI inference has driven an unprecedented jump in memory demand, while supply is physically constrained and simply cannot keep up. HBM is consuming disproportionate wafer capacity, process node efficiency gains are diminishing, and equipment delivery is bottlenecked. Supply is chasing, but it cannot catch up. Not because of a lack of effort, but because demand is moving too fast.
The bears almost never address demand directly. Everything they say is about supply: “capex has doubled,” “new fabs are coming,” “this is how it always plays out.” They avoid the demand side because there is currently no evidence there to support a bearish case. So they fall back on history: “2018 looked just like this, and then it crashed.”
But 2018 did not crash because capacity came online. It crashed because cloud investment peaked, demand decelerated, and supply kept arriving on the momentum of plans made years earlier. It was the collision of slowing demand and inertial supply that created the glut.
For this cycle to repeat that pattern, what is needed is not new fabs coming online. It is a turn in AI investment appetite. There is currently no sign pointing in that direction.
And this risk is not unique to memory. It is the shared premise underlying every AI infrastructure investment. GPUs, foundry, custom ASICs, networking equipment — everyone is betting on the same thing: that AI investment will continue. If AI capex truly turns, it will not just be memory that suffers. The entire AI supply chain will come under pressure simultaneously. Yet the market assigns 25 to 30 times earnings to GPUs, 20 to 25 times to foundry, 25 times to custom silicon, and only 6 to 9 times to memory. Same demand assumption, same supply chain, same uncertainty — but a three to four times difference in valuation.
That discount does not come from analysis. It comes from a label. The five words “memory is a cyclical stock” carry thirty years of muscle memory, causing the market to automatically assign memory a discount entirely different from every other AI asset. That label is slowly being peeled away by long-term agreements, by audited contract data, and by every passing quarter where earnings do not collapse. Peel away half of it and the stock doubles.
The remote control for this cycle is not in the hands of memory manufacturers. It is in the hands of their largest customers’ CFOs. Watching the right place matters more than watching the right numbers.
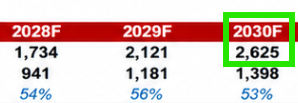
$MU $DRAM Rubin SOCAMM cut from 55TB to 28TB isn’t a demand cut, it’s a wafer allocation problem. LPDDR5X dies share the same wafer pool as DDR5 RDIMM (89%+ GM) and LTA-locked HBM (3-4x wafer per bit). Suppliers prioritize both over SOCAMM2. The missing 27TB/rack is deferred demand waiting for silicon, not cancelled demand.
$MU When the analyst starts getting rogue threats, that’s not the top, that’s the shorts telling you they’re still in pain and haven’t finished covering
UBS Desk:
"I can’t remember a
time when I have received so many inquiries from one our research reports than this $MU report did not to mention the level of controversy it
created (Tim actually received a few rogue threatening emails not cool…)"
$MU $DRAM Memory’s valuation framework is breaking in real time. The re-rating hasn’t even started.
Citi, MS, and JPM all published LTA-focused research in the same week, independently reaching the same conclusion: multi-year contracts with price floors, prepayments, and financial guarantees are shifting memory from Make-To-Stock to Make-To-Order. Citi switched $MU to 8x forward PE ($840). MS wrote “re-rating has yet to be priced in.” JPM mapped the path from P/B to P/E and modeled wafer shortage through 2030.
The sector trades at 6x forward — lowest in the AI stack. Below HDDs, equipment, networking. The old frameworks can’t produce a PT within 50% of where stocks trade. That’s not a stock problem. That’s a framework problem.
$MU $SNDK $DRAM JUST IN: LTA Expansion
Samsung and SK hynix are expanding Long-Term Agreements (LTAs) with major clients amid surging AI demand and tight memory supply. Buyers are willing to pay premiums and higher advance payments to secure supply, which could paradoxically drive overall memory prices higher in the near term.
Shift in Market Dynamics: LTAs, traditionally used to reduce price volatility, are now pushing prices up. Customers with LTAs accept higher fixed prices for supply security; those without may face even steeper spot-market prices due to shortages. The memory market is described as a "producer’s market," with the supply-demand imbalance likely persisting until at least 2028.
Samsung’s Moves:
-Major clients are seeking mid- to long-term volumes due to strong AI expectations. Samsung is signing multi-year contracts.
SK hynix’s Deals:
-Three-year DDR5 supply agreement with Microsoft (tens of billions of dollars).
-Up to five-year (plus possible two-year extension) general-purpose DRAM deal with Google, potentially linked to next-gen HBM.
Advance payments rising sharply from previous sub-5% levels to 10–30% of contract value. Suppliers can retain prepayments as penalties for volume shortfalls. Contracts often include minimum price floors.
Outlook: Move toward 3–5 year agreements reduces reliance on cyclical PC/smartphone demand and supports more stable AI-driven growth. Analysts note potential for DRAM prices to rise up to 50% QoQ in Q2, pushing margins above 80%
Structural Shift = Re-Rate
$MU $SNDK $DRAM Three things that matter more than this week’s price action:
1. The audit gap. SNDK’s 10-Q shows $511M contract liabilities and $41.6B in remaining performance obligations, audited, filed with the SEC. MU’s latest 10-Q? “Future performance obligations beyond one year were not material.” Same industry. Same cycle. When MU’s July filing closes that gap, one company is an anecdote, two is a pattern.
2. The framework is breaking. Most of Wall Street still uses through-cycle valuation for memory. GS normalized annual EPS estimate is $22, MU earned $19 last quarter alone. Another raised their through-cycle EPS on SNDK 60% in a single month. A smoothing metric that jumps 60% in 30 days isn’t smoothing anything.
3. Attention is NOT positioning. $DRAM ETF absorbed $5.6B in its first month. Media is discussing stock splits. But the largest sell-side holdout hasn’t upgraded, and the valuation methodology hasn’t switched. Retail arrived via ETFs. Institutional capital is still in the queue.
$MU $SNDK $DRAM Congrats to everyone long memory this week. Historic moves.
Two things happened simultaneously.
First, earnings calendar compressed buyer confirmation (hyperscaler Q1: $700B capex, “memory not enough, buying more”) and vendor confirmation (SNDK +97% QoQ revenue, STX record margins) into the same 5-day window.
For the first time, both sides of the transaction were publicly verified in the same week.
Second, none of this information was new. MU printed the strongest earnings in memory history six weeks ago. PMs knew. They were waiting for permission to act. SNDK’s print was that permission. Six weeks of pre-loaded conviction released in 72 hours.
This wasn’t FOMO. This was delayed recognition compressed into a single week.
$ARM The CPU supercycle is not investable through x86. Every new AI server socket is increasingly ARM, whether it is Graviton, Axion, Grace or Vera. ARM collects royalties on all of them regardless of whether the CPU bottleneck narrative is real or not. It wins both scenarios.
Meanwhile the narrative itself is built on shaky ground. Intel sold its fab tools last July, created its own shortage, then beat estimates partly by clearing written-down inventory from 2019. AMD’s Q4 datacenter beat was under 1% after stripping out a one-time China export license. Agents spend 90% of their time waiting on network I/O, not computing. The market is pricing wait as work.
$MU $DRAM Ignore the spot dip, it’s channel noise. What matters: TrendForce just revised April DRAM contract prices higher again, with DDR4 now priced at DDR5 levels as big 3 exit legacy supply.
Hey guys, Trendforce just revised April DRAM contract price forecasts even higher. They bumped DDR5/DDR4 up by +18% and +23% respectively vs. the March estimates lol.
The contract prices to be announced at the end of April are expected to hit $37.5 for both DDR5 and DDR4 — that's +27%/+21% MoM gains.
SK Hynix's Q2 is going to be way stronger than Q1.
@akramsrazor Right. The narrative assumes every agent needs a dedicated CPU churning away. Reality is it’s mostly idle, waiting on I/O. Async breaks the linear scaling story that the whole “CPU bottleneck” thesis depends on.
$AMD $INTC Wall Street is wrong about CPU being the next AI bottleneck. The thesis assumes synchronous execution in a world that runs on async I/O. An agentic workflow spends 90% of its time waiting on LLM calls, tool responses and database queries. With modern async primitives, a single core can hold tens of thousands of pending operations simultaneously. CPU demand scales sub-linearly with agent count, not linearly. The attach rate math analysts love is rooted in a mental model that hyperscaler infra teams abandoned a decade ago.
while I agree that CPU is strong and that goodness been the cornerstone of a few of my pitches in $ARM and $AMD in the past, I think we are ahead of our skis:
- CPU has not gunned price in the same way as memory, optics, etc because they can't. They are raising pricing LDD to make up for BOM cost inflation (memory, $TSM wafers)
- right way to think about CPU demand is % of hyperscaler spend not "attach" to GPU for many reasons. it is still a "share" loser. In a bluesky case, I think hard to see hyperscaler CPU revs grow faster than the capex base in CY26
- $AMD and $INTC actually didn't smoke their datacenter numbers. $AMD would have beaten Street DC revs by under 1% in Q4 had it not been for MI308X which sort of sucks for the first leg of a "supercycle"
@akramsrazor Fair Point. Even if server count doesn’t drop, CPU is just a passenger in a box bought for memory and network, and increasingly that passenger is Grace or Graviton, not x86.
Passengers don’t get pricing power, especially when they’re being replaced by cheaper ones.