CPO @ Funding Societies (SEA's largest SME digital lender) | ex-Lendingkart & PayU | Love being at the intersection of Fin. Services + Tech + Consumer Behavior
I keep coming back to Karpathy's line while building agents for my own knowledge workflows:
"you can outsource your thinking/execution, but you cannot outsource your understanding."
Most "AI for knowledge work" today is tools. They speed up tasks.
So the design question isn't "what can the agent do?"
It's "what should the human still do?"
Here's the primitive I keep coming back to.
Say I'm tracking a stance:
AI-native knowledge-work products won't win by producing better summaries. They'll win by helping humans maintain and update a point of view.
Now an article lands about an AI research tool used by investment teams.
The agent shouldn't just summarize it. It should ask: does this article strengthen the stance, challenge it, or expose a gap?
Strengthen: the product is making the same bet, workflow centered on tracking a thesis over time, not on reading faster.
Challenge: adoption looks strongest for first-pass research, not decision support. Teams still export output into docs and slides before the actual judgment call. Maybe the stance is wrong about how users behave.
Gap: no evidence anyone changed a decision because of the tool. No example of a thesis being revised after contradictory evidence. The stance hinges on decision-shift being the value; the article doesn't show it.
That's the useful agent output.
Not "here's the summary."
But "here's what this new piece of evidence does to a stance you already care about."
Now the human has a real job: hold the stance, weaken it, rewrite it, or go look for the missing evidence.
That's the human-in-the-loop inversion I'm working with. The agent pulls the human out of reading, sorting, tagging, comparing, remembering.
It keeps the human exactly where judgment lives:
1. What do I believe now?
2. What changed?
3. What evidence would make me update?
I've been running this on my own knowledge workflows. Might open source it one day, but not my priority right now. If you're designing your own tools to expand your thinking and not summarise, would love to chat.
If you really think you can do something special...
Then live like it.
Move in the world like you're on a mission.
Start doing things that support who you really are, instead of settling for the smaller life.
@prajitn There was a time when building strong org and delegation did well.
This advice has completely flipped on its head. Also, there's so much 'agency' with being hands-on which you get to experience only if you build.
The new BS in town is: “taste is the new moat.” Then people who say that go on to build a podcast summarizer.
The point of an information stream isn’t to get a cleaner summary. It’s to sharpen your point of view. And that point of view should feed a real decision.
But when you ask an LLM for help, you often get the opposite:
more surface area, less conviction. Especially when the task is “summarize this article” or “give me the takeaways.”
I’ve been thinking about how to turn what I’m reading and writing into better decisions, so I built a small tool for myself.
At any point, I have 3-4 active decisions.
For each one, I keep a working folder with my current stance and key questions I am grappling with.
The pipeline is, ingest what I’m reading, map each chunk against an active stance, retrieve related notes from my own writing, and synthesize where the real leverage point is.
So when a new article comes in, rather than asking "what is this about?”
It asks:
Does this strengthen my view, challenge it, or expose a gap in it?
Then it checks my own notes for where I’ve already been circling the same idea, but hadn’t connected it clearly.
The job isn't summarizing the content. It's testing my thinking against it.
I’ll share a walkthrough next week: how the mapping works, how it connects to prior notes, and what happens when the model gets it wrong.
The fundamentals of learning haven’t changed. We still need to read, process, and develop our own thinking.
What has changed is the amount of noise.
As we started building with LLMs at Yuuki, like any other product person, I brought in the workflow that worked for the last 15 years.
Spec it, build it, test it, ship it. The assumption was the same: you know what good looks like before you start testing.
So we built evals to do exactly that. Score the output, check the quality, move on.
However as LLM outputs are non-deterministic, 10 point evals created problems.
My nine turned out to be my co-founder's six. 😆
The LLM judge scored a seven that matched neither of us.
Two months of scoring and we couldn't tell if the product was improving or our standards were drifting.
You can't test for correctness when correctness isn't fixed. A coaching response that's empathetic but doesn't push the user to act, is that good? Depends on who you ask, depends on when you ask them.
Hamel Husain's work on LLM evaluation pointed us to the fix.
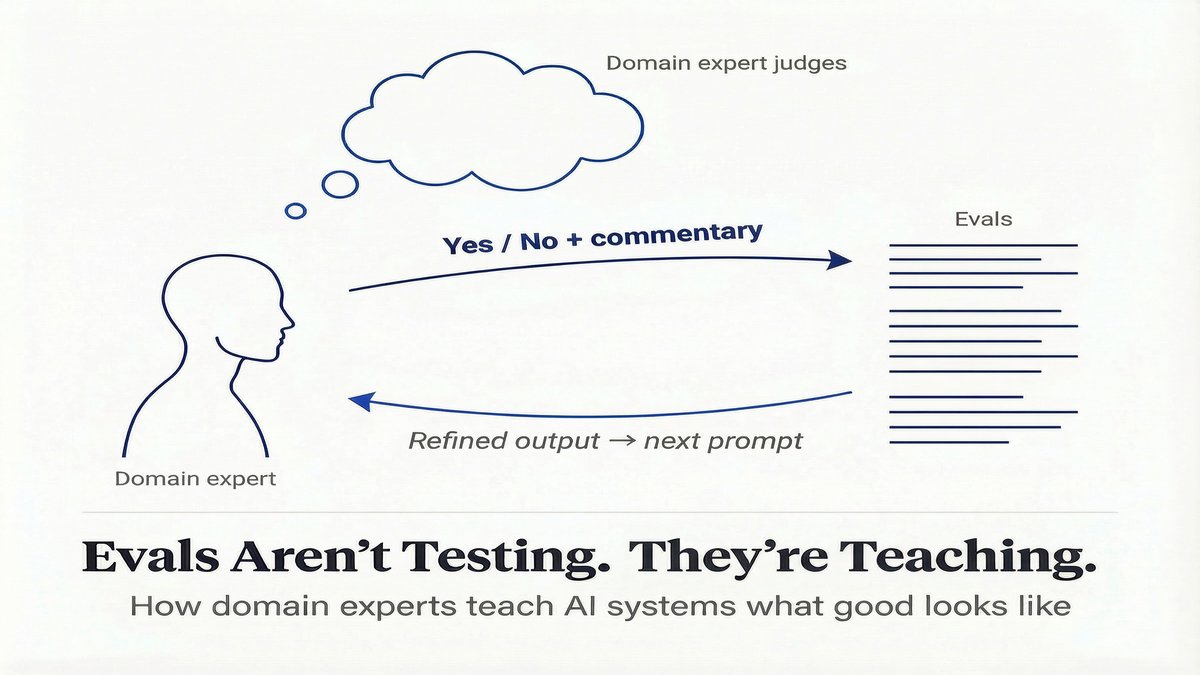
Binary. Yes or no.
Is this response empathetic? Yes or no. No more debates about sixes and sevens.
The feedback loop when building with LLMs is extremely tight. Every binary judgment came with a line of commentary. "Gave advice before asking a single question", that critique becomes a constraint. The next version follows it. Gets reviewed again, refined further. The evals aren't just a testing phase. They're the loop through which the product gets defined.
And now because everyone, product, engineering, domain experts, is judging the same outputs, the evals force alignment on what good actually means. That alignment didn't exist before. The process created it. More on this in the next post.
For now, wrote a detailed post on how we designed our evals, link in comments.
Funny episode of the day: I was chatting with Claude, which has a nice sense of humor. I was supposed to say “super helpful", and Claude's response was so on point, that I ended up replying to a non-required response.
@NirantK We were very early stage, just three of us. From start to finish, around 6 to 8 weeks, we used sprinto. Around 7ish k USD (first year) including one-time audit
Agentic Engineering: Technically Correct, Contextually Naive
Everywhere I look, teams are celebrating AI coding agents. Million lines generated. PRs flying. Shipping velocity through the roof. Having lived through this, let me share what it actually looks like on the other side.
After 24 months of building Yuuki and Rapida, there is a teeny tiny reality that changes how agentic engineering works. Agents are like engineers: they write a lot of code. But they are unlike engineers because they don't carry context. They start fresh every time. The code is technically correct but contextually naive.
For the first feature, that's manageable. By the tenth deploy, you're shipping code that ignores everything production taught you from the first nine. That's not speed. That's compounding tech debt at machine pace.
One of our agents at Rapida generated a webhook handler that passed every test. In production, the telephony provider retried on slow responses and the handler wasn't idempotent, which led to duplicate calls. An engineer who'd been bitten by that provider before would have built idempotency in from the start. The agent didn't have that scar tissue.
Because of our traces, we caught it within minutes and fixed it the same day. Then we encoded the lesson — idempotency constraints baked into the webhook contract. Now agents generating webhook handlers must follow that contract. The system carries the context so the agent doesn't have to.
That's the pattern: not more reviews before shipping, but a feedback loop where production teaches the system, and the system constrains the next generation.
The teams shipping reliably at AI speed aren't generating the most code.
They're the ones whose system learns from every deploy.
https://t.co/yTaOwuLEk6
From my personal experience with one of my relatives, what you get to know versus what's happening could be very different.
Sometimes the staff would mention that the flight is canceled, but it actually takes off. Would recommend, if possible, to go to the airport and check for yourself.
Can share more on DM if you want.
@AjeyGore Can confirm. Went all-in on Claude Code CLI + Wispr Flow, cancelled Akiflow, journaling app subscriptions.
I spend all day on/in/with CC and practically zero friction and insane customisation
@AjeyGore I use Obsidian and Claude Code extensively now.
For any research, I use Manus / Gemini and think bring those markdown files to Obsidian for all project work.
I hear your poetic phrase and raise you a Sahir Ludhianvi (Main pal do pal ka shayar hoon):
Woh bhi ek pal ka kissa they,
Main bhi ek pal ka kissa hoon.
Grateful our paths crossed in that one pal, Ajey.