New preprint 💥
Can a general-purpose model achieve results comparable to medically pre-trained models? 🤔
We show that lightweight fine-tuning of a general-purpose LVLM and an LVLM-aware retriever can. 🚀
🔗 GitHub: https://t.co/vbHBIyoNgj
📄 Paper: https://t.co/Q8tKLk8J1P
🎉 Happy to share that CHIMERA has been accepted to #ACL2026NLP (main conference)!
📄 Paper - https://t.co/11tMhA07P2
🤗 Data - https://t.co/g8GgYsfj9E
🌐 Project Page - https://t.co/c4j8gEm6V5
💻 Git - https://t.co/lVC8UAzOti
Joint work with @Hoper_Tom
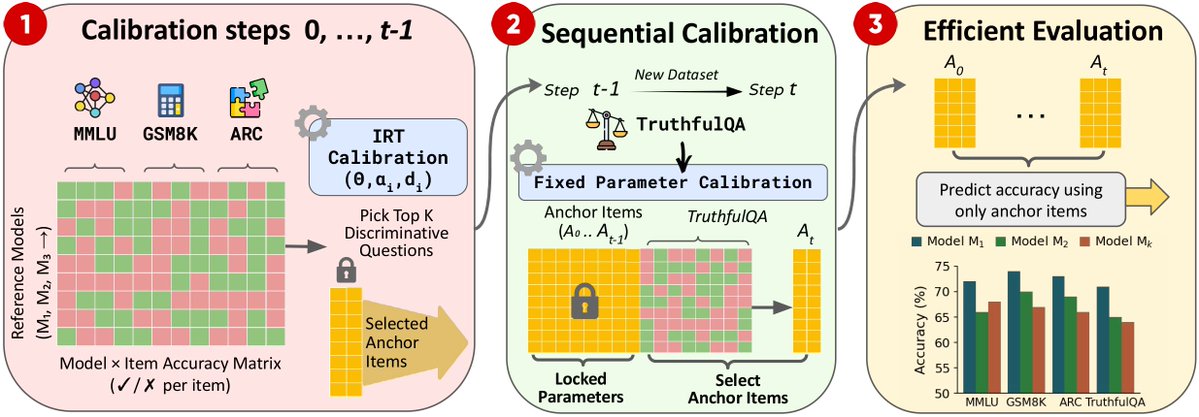
New datasets keep coming,
New models keep coming.
Frustrating!
How can we evaluate everything on everything?
How do we keep scores comparable over time?
We propose a way to grow benchmark suites without losing comparability.
Details:👇🧵
Have LLMs become supervised learners (once again)?!
In our new paper, we argue that current LLMs’ post-training methods have effectively reverted to the "pre-train then fine-tune" era, explicitly tailoring models to desired behaviors.
1/n
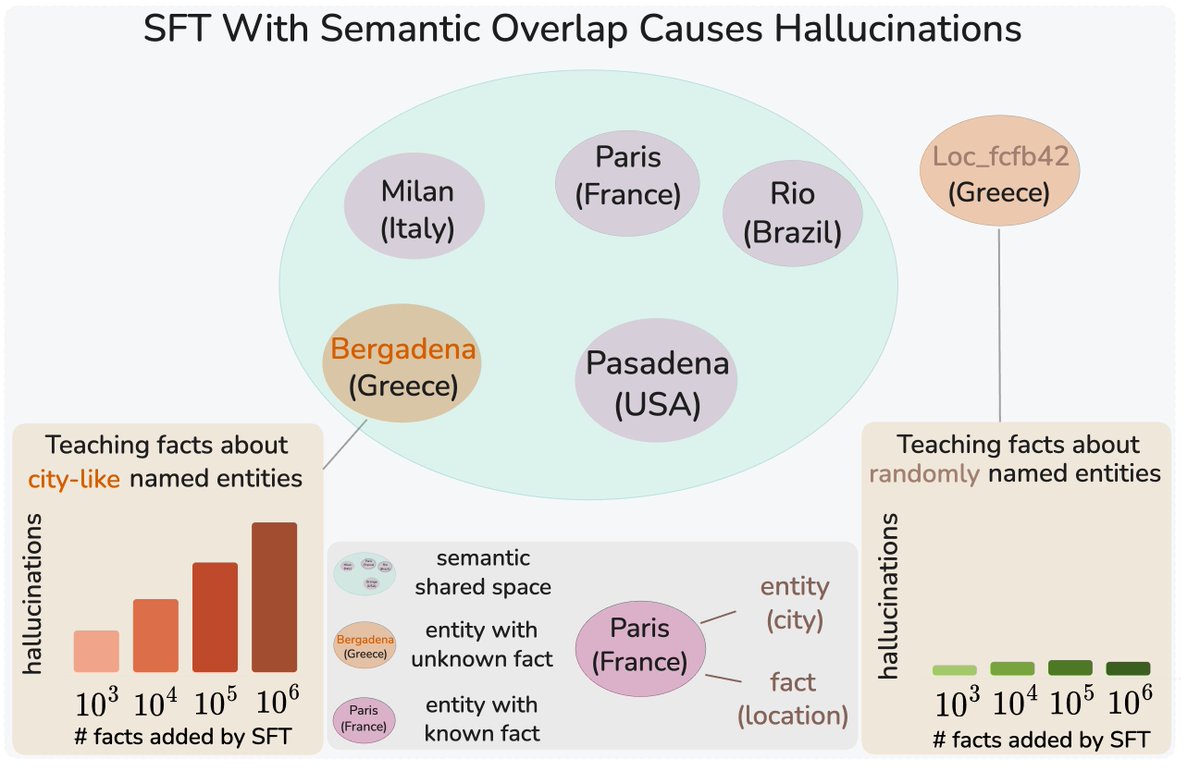
Fine-Tuning LLMs on New Knowledge Encourages Hallucinations. (@zorikgekhman)
But why? We found something unexpected:
1M facts about city-like names →hallucinations explode.
1M facts about random identifiers →near zero!
Same model. Same number of facts. Only the names change.🧵
Ever used a top-ranked LLM that just... felt wrong for you?
You’re not alone. Instead of leaderboards, many of us turn to "vibe-testing" - manually comparing models to our own needs. But can we turn these feelings into a structured evaluation?
New paper: "From Feelings to Metrics" 🧵
We introduce 🌍GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens.🌍
Most feed-forward 3DGS methods still start from pixel, voxel, or dense view-aligned primitives.
We take a different route: align first, decode later. 🧵👇
We are excited to share our new preprint! 🚨
https://t.co/mRKThbiSbH
In this work, we investigate the neural mechanisms by which speakers generate information-rich linguistic content during spontaneous natural conversation.
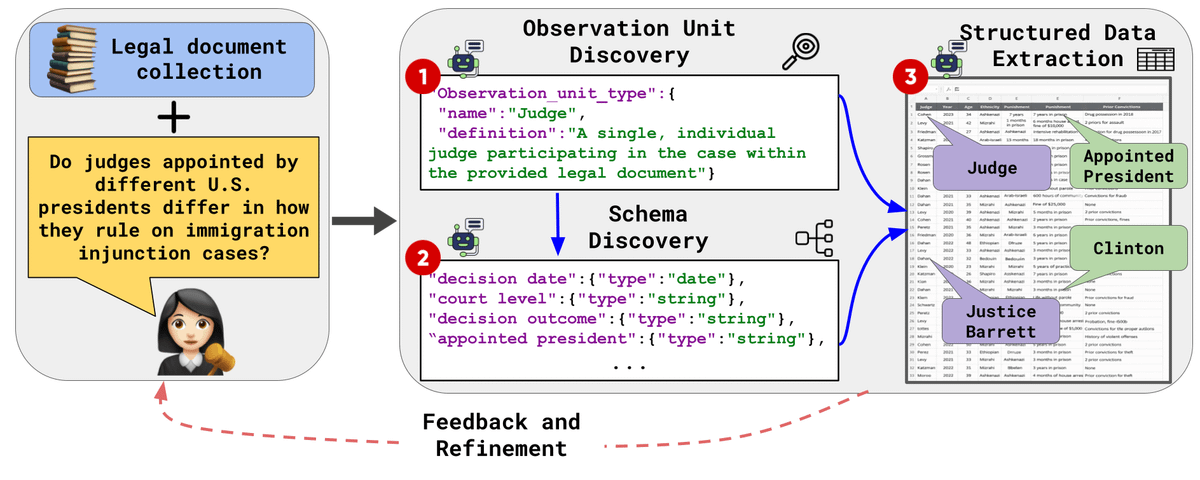
What if you could automatically turn a large collection of documents into structured databases, tailored for your own research needs?📄
We introduce ScheMatiQ!
From question ➝ schema ➝ structured data 🔍
@ShaharLevy19@MintzReshef@RKeydar@BarakRaveh@GabiStanovsky
🧵
👇1/5
Happy to share three papers accepted to the #ACL2026@aclmeeting conference: on AI ideation, multimodal medical AI, and literature understanding.
If you want to read about them, check out the following posts from @NoySternlicht , @NirMMazor and @UKPLab . More updates on each to come separately.
In the hypothesis generation / ideation space : cross-domain inspirations. Led by @NoySternlicht .
https://t.co/d91iDkZ4B2
In the multimodal medical AI domain: medical image diagnosis with literature retrieval. Led by @NirMMazor .
https://t.co/hVRGITKfwM
In literature understanding space: summarizing thousands of citations to understand a paper's impact. Led by Hiba Arnaout from @IGurevych's lab, with major contributions from @NoySternlicht .
https://t.co/ZTWZhbEWZX
Today at #EACL2026 we present our work exploring PRINTED newspapers as a data source for summarization in low-resource languages.
Join the virtual session at 18:00!
🧵👇
Do you run pairwise evaluation?
Do you test your models on the Arena-Hard and AlpacaEval benchmarks?
You probably want to read this 🧵👇
https://t.co/z5gxRdXHHb
With @LChoshen@AbendOmri
New preprint, evaluation framework & leaderboard!🚨
General-purpose AI agents are everywhere. 🤖
From ReAct to @claudeai Code and @OpenAI SDK.
But how do we actually evaluate them — as general agents?
Currently, benchmarks are deeply tied to domain-specific setups, making it impossible to evaluate true cross-domain agents.
We’re changing that!
We’re introducing Exgentic and the Open General Agent Leaderboard. 🧵👇
New preprint 💥
Can a general-purpose model achieve results comparable to medically pre-trained models? 🤔
We show that lightweight fine-tuning of a general-purpose LVLM and an LVLM-aware retriever can. 🚀
🔗 GitHub: https://t.co/vbHBIyoNgj
📄 Paper: https://t.co/Q8tKLk8J1P
🚀 Excited to share that my paper from my internship at @IBMResearch has been accepted to #ICASSP2026!
We train Speech-Aware LLMs (SALLMs) with Group Relative Policy Optimization (GRPO) on open-ended tasks (Spoken QA & Speech Translation). We find that GRPO beats SFT!