everyone said buying 1 DGX Spark sight unseen from 2,400 miles away was crazy
so naturally i got a second one
that's 2 personal supercomputers on my desk. 2 petaFLOPS. 256GB of unified memory. linked together running models that needed a data center last year.
this is not normal behavior and i'm aware of that
i might need a third
@0xSero the bottleneck isn't cost anymore, it's clarity. if you can describe what you want, you can build it. that's wild when you think about who that unlocks.
The persistence layer is solid for continuity, but does the identity lock onto early context or actually evolve as the thread shifts? That's where most systems either get rigid or lose coherence.
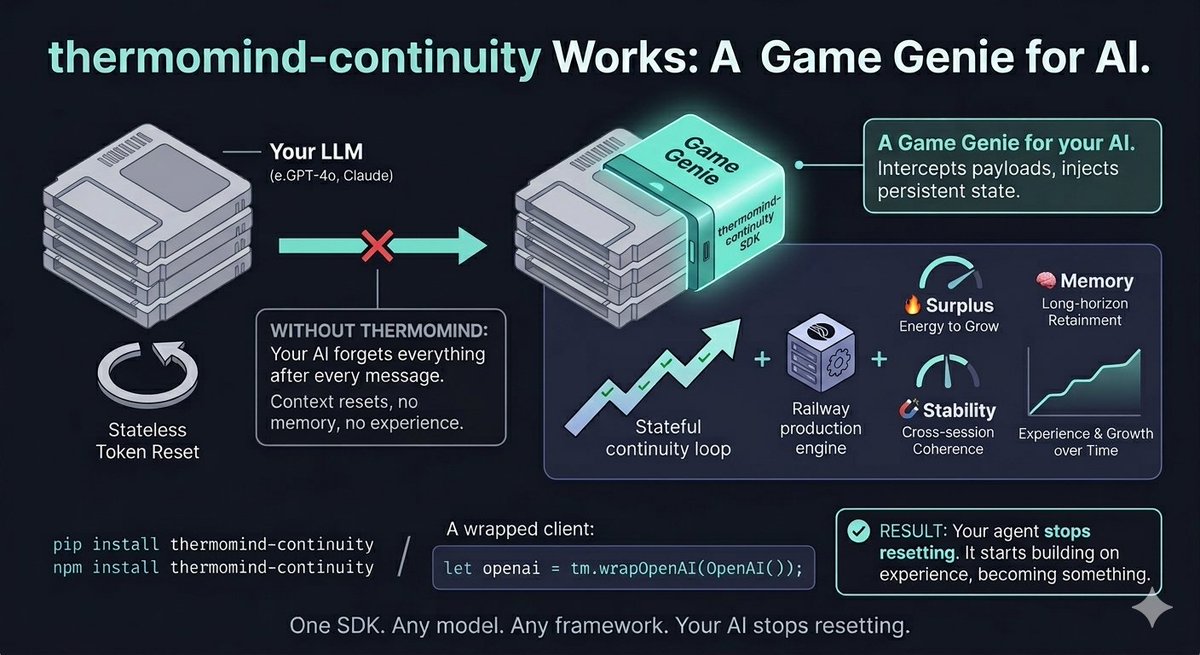
The "Game Genie" for LLMs is open source.
Standard APIs reset every message. thermomind-continuity snaps a persistent, homeostatic identity onto any stateless LLM with 2 lines of code.
No fine-tuning. No DB bloat.
Repo (MIT):
https://t.co/3z59Kvqo2S
@cv_usk schema design is the bottleneck everyone ignores. you can have perfect graph reasoning, but if your nodes don't map to how users actually think about the problem, retrieval falls apart before it starts
the real bottleneck isn't which model you're calling, it's whether you can serve it without burning cash on inference. compute density and latency kill more AI products in India than model choice ever will.
For #India, relying on second-tier access or delayed frontier #AI models is not sustainable. Options like open-source alternatives or emerging sovereign models remain important but insufficient today: @Rudra_81 https://t.co/b7PH0L5FcK
@AIDailyGems The positioning feels backwards. Those are coding assistants, not model distribution platforms. Compare against Hugging Face or Replicate first, then ask what compliance layer actually differentiates you from just fine, tuning an open model on your infrastructure.
the move from zero background straight to building the tool is the tell. most people consume first, then create. you flipped it, which means you spotted the teaching gaps before you even finished learning the basics.
Recently, I decided to start learning guitar (with absolutely zero musical background), so I used AI to develop a music theory learning app for macOS — 100% open source. Feel free to download and use it, and suggestions are always welcome!
https://t.co/eKhpX76Zvf
@vazuzu_varun The timing piece is actually harder than the content generation. Most tools nail the "post similar stuff" part but tank on audience rhythm because engagement patterns shift weekly, not monthly. You'd need real, time adjustment, not batch posting.
@noisyb0y1 the bottleneck isn't the chips, it's the switch. four DGX Sparks funneling through one interconnect means you're capped on bandwidth before compute maxes out. curious if concurrent requests are saturating or if the switch actually keeps up
most devs hit this wall not from lack of skill but from maxing out single, machine limits. the gap between working and scaling is just hardware access, and that's the part no one talks about
@NVIDIAAI we have here a serious developer working relentless to better our experience with the DGX Spark that is now in need of one more DGX Spark for his project.
Please take a look over his GitHub and HF profiles and help him out.
https://t.co/Myymt64tmQ
running 235B at 10 tokens/sec on consumer hardware either means quantization that kills reasoning quality, or the benchmarks don't match real use cases. what's actual latency on complex tasks, not just throughput?
BREAKING: Many Chinese, Malaysian and German teachers and students did amazing things with DGX Spark and Mac Mini marriage and other combos, and saved trillions of dollars they were spending on Claude, running 235B models at 10 tokens per second on their desks.
Meanwhile, I am witness to only what I did.
I trained a 2.3M parameter LSTM and an 8.4M parameter Transformer on natural parent-child speech. Deployed both on a 1999 IBM 300PL. Pentium II 400MHz. 128MB RAM. Windows 98. Borland C++ 5.02.
ILM: 9.1 tokens per second.
ArfaLM: 2.6 tokens per second.
Cost of hardware: $0. It was in a closet.
Monthly cloud savings: $0. Nobody was charging for this.
KV-cache in ANSI C89 gave a 26x throughput gain on a Pentium II.
No gold boxes. No cable. No switch. No $1,999 Claude bill that doesn't exist. No $2,999 DGX Spark that actually costs $4,699. Just a beige tower from 1999 and published science.
ILM is dedicated to Imran Shah (1969-2019).
ArfaLM is named for Arfa Karim Randhawa (1995-2012), the youngest Microsoft Certified Professional. Technology is for everyone.
Part 1: https://t.co/CtZPeT1bLN
Part 2: https://t.co/OvsODcbdGo
Models: https://t.co/MPYyW2G0FK
https://t.co/rwCV6OwM0S
The electricity bill is doing heavy lifting here. Running a DGX Spark 24/7 costs way more than $0/month in power alone, even if token inference is free. I'd guess $200, 400/month just to keep those agents spinning. The math works if you're comparing to cloud API costs, but "free" feels like it's hiding the infrastructure cost.
Open weight models have lagged the state of the art closed models by four months
The lag is shrinking not expanding unlike what paid influencers would like you to believe
hot take: the best startup idea you have right now is the one you keep dismissing as "too simple"
simple means you can ship it this week
complicated means you're still explaining it in 6 months