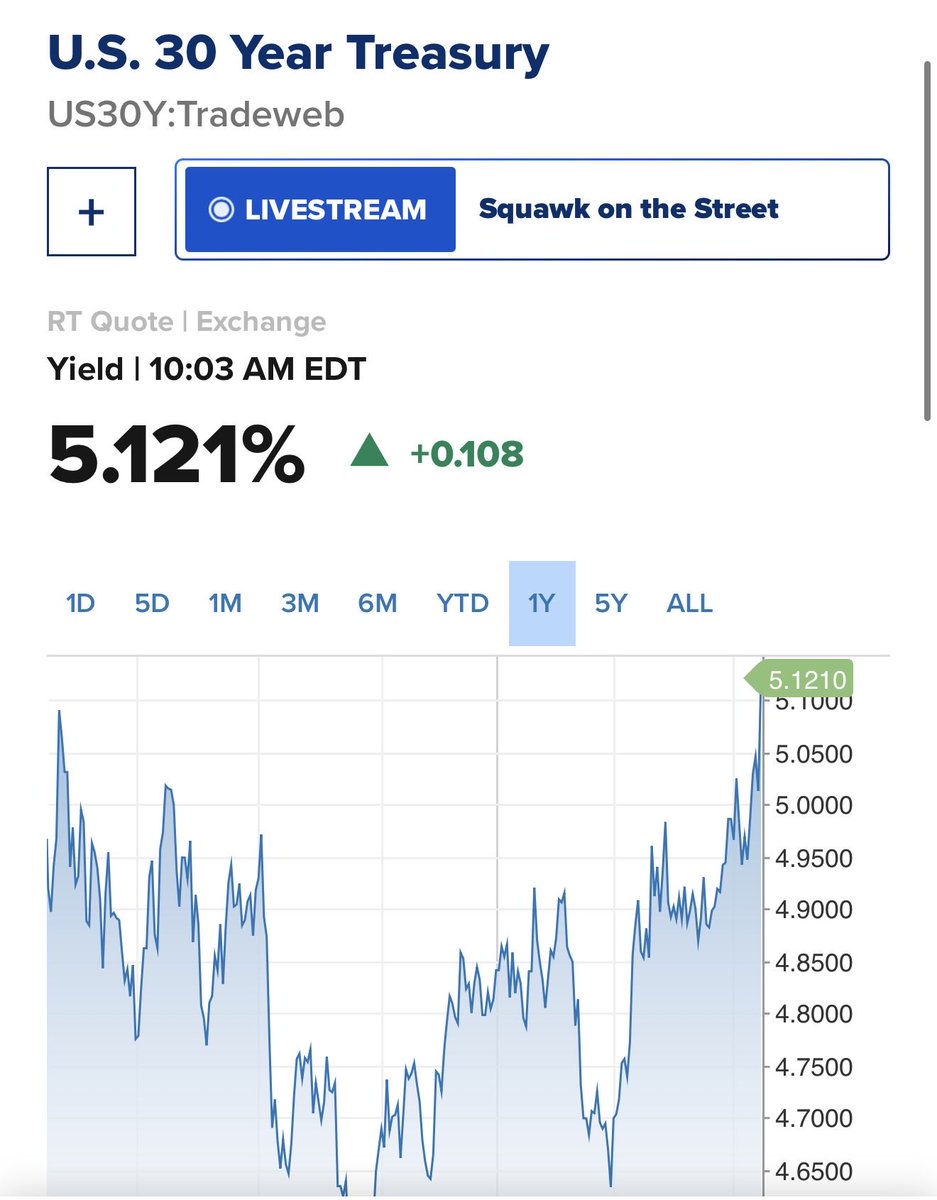
been running openhuman for a week and i don't think people understand what just shipped
1B token memory. ingests your gmail, slack, github, notion in a single sync. runs local. no "give it a few weeks to learn you"
8.5k stars and almost nobody is talking about it yet. open source under GPL3, zero token, zero noise. just a desktop app that quietly becomes the smartest thing on your machine
He's right. Stop trying to lock people in. If you just made Claude code a better product, people wouldn't go to other places and try to wrap your stuff. Not a lot of people mind using codex.. it's because it's actually good software /goal
We’re partnering with the Gates Foundation, committing $200 million in grants, Claude credits, and technical support to programs in global health, life sciences, education, agriculture, and economic mobility.
Read more: https://t.co/eqCrLKtNCq
this is one of the most peak web3 art i've seen
swiss artist @Dario_Desiena, a cryptopunk holder and creator behind some of the most interesting drops in recent years
he spent over 6 months in silence building @R3ORDR , a generic collection made from fragmented, corrupted financial identities turned into raw collage art
>> bold silhouettes, torn paper textures, xerox grit, and heavy overlays of trading charts, liquidation maps, and market noise
the system is glitching and reforming right in front of you
Dairo built it to break his own patterns. the result is genuinely distinct
website is live btw
>> https://t.co/s32ZyjCjEX
Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights.
So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA.
Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models).
I think this idea of learning both fast-slow weights would be a good foundation for continual learning.
PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea.
See more details here:
https://t.co/FACsHx7IpK
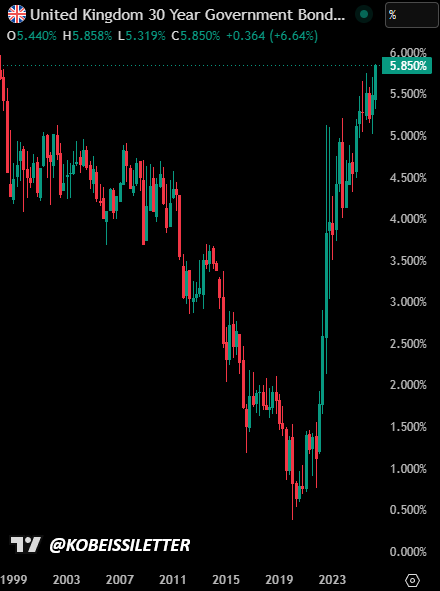
BREAKING: The UK's 30Y Government Bond Yield surges to 5.85%, its highest level since March 1998.
Global bond markets are bracing for severe inflation.
You've been asking for this one...
Now in preview: Codex in the ChatGPT mobile app.
Start new work, review outputs, steer execution, and approve next steps, all from the ChatGPT mobile app. Codex will keep running on your laptop, Mac mini, or devbox.
The 11 cheapest punks listed are all femmes.
This reflects most punk buyers being male, but with only 3,840 femmes in a 10k collection I find this dynamic interesting. There are some stunning femmes here.
My pick: black lippy, mohawk thin and earring for her pure punk vibe.
Cheapest male listed is now a PNKSTR listing.
New blackboard lecture w @ericjang11
He walks through how to build AlphaGo from scratch, but with modern AI tools.
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k+ tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Timestamps:
0:00:00 – Basics of Go
0:08:06 – Monte Carlo Tree Search
0:31:53 – What the neural network does
1:00:22 – Self-play
1:25:27 – Alternative RL approaches
1:45:36 – Why doesn’t MCTS work for LLMs
2:00:58 – Off-policy training
2:11:51 – RL is even more information inefficient than you thought
2:22:05 – Automated AI researchers
Critique of the 𝕏 algorithm is welcome.
There will be monthly updates of the latest algorithm to GitHub with release notes.
As reminder, you can always choose no algorithm via the Following tab.
I'm building a new team at @databricks AI Research and we're hiring.
We're focused on one of the hardest open problems in AI right now: how do you measure and continuously improve agents that operate on enterprise data at scale. We're looking for founding engineers to build the flywheel that turns evaluation results directly into better agents — from development and training all the way to production.
If you want to work on problems that actually matter at the frontier of AI research, I'd love to talk.
Link in comments 👇