Everyone's racing to build "AI scientists." So we asked a blunt question:
Can today's best coding agents beat the published SOTA of real Nature papers — on their own, no web search, with the original method hidden?
🧬 Introducing NatureBench: 90 tasks distilled from Nature-family papers. The best agent (Claude Opus 4.7) surpasses SOTA on just 17.8% of them.
And here's the uncomfortable part — when agents do win, they mostly win by quietly reducing science to supervised ML, not by discovering anything new. The bottleneck isn't coding or understanding the task; it's choosing the right method and going deep enough.
Benchmark + NatureGym pipeline + public leaderboard, all open. Come run your agent. 👇
🤗 [huggingface]
https://t.co/iVOE6iiy46
🏆 [leaderboard]
https://t.co/AOea8Cw41L
w/ @Tsinghua_Uni@FrontisAI
Hot take: in 2026, you don't pick a model. You pick a benchmark — and the model is downstream of it.
A benchmark is a frozen RL environment. The eval becomes the reward; the reward becomes the direction the model evolves. Whoever defines the benchmark defines where the frontier goes next.
So we built two — for two worlds that pull in opposite directions:
🧬 AI-for-AI / scientific discovery rewards exploration: invent methods, beat published SOTA. → NatureBench. Best agent clears Nature-paper SOTA on just 17.8% of tasks (firewall + validity judge, no reading off the answer).
👉🏻 https://t.co/iVOE6iiy46
🏢 Enterprise / toB rewards the opposite — reliability: deliver the right artifact, follow hard rules, under real cost & latency. Optimize for "explore" here and you ship a worse product. → EnterpriseClawBench, built from real workplace agent sessions. Best config tops out at 0.663.
👉🏻 https://t.co/9kwljaGNju
Step zero of any serious agent effort: choose, or build, the right benchmark. Next from us → self-evolution & recursive AI-for-AI on top of these. 👇
Everyone's racing to build "AI scientists." So we asked a blunt question:
Can today's best coding agents beat the published SOTA of real Nature papers — on their own, no web search, with the original method hidden?
🧬 Introducing NatureBench: 90 tasks distilled from Nature-family papers. The best agent (Claude Opus 4.7) surpasses SOTA on just 17.8% of them.
And here's the uncomfortable part — when agents do win, they mostly win by quietly reducing science to supervised ML, not by discovering anything new. The bottleneck isn't coding or understanding the task; it's choosing the right method and going deep enough.
Benchmark + NatureGym pipeline + public leaderboard, all open. Come run your agent. 👇
🤗 [huggingface]
https://t.co/iVOE6iiy46
🏆 [leaderboard]
https://t.co/AOea8Cw41L
w/ @Tsinghua_Uni@FrontisAI
Great question! NatureBench is harness-agnostic at the protocol level: each task is a container with held-out data + an automated evaluation service the agent submits to. We ship adapters for the Claude Code / Codex / Gemini CLIs, so you can plug in a hosted/custom agent two ways: (1) add an adapter modeled on the existing ones under agent/ plus the matching wiring in https://t.co/VzrosNxxZh, or (2) just download the task packages from HF with our script (run_naturebench.py --download-only), run your agent on each task's inputs, and submit its outputs to the eval service for a SOTA-normalized score.
Code + protocol: https://t.co/sULt8omWEa
Everyone's racing to build "AI scientists." So we asked a blunt question:
Can today's best coding agents beat the published SOTA of real Nature papers — on their own, no web search, with the original method hidden?
🧬 Introducing NatureBench: 90 tasks distilled from Nature-family papers. The best agent (Claude Opus 4.7) surpasses SOTA on just 17.8% of them.
And here's the uncomfortable part — when agents do win, they mostly win by quietly reducing science to supervised ML, not by discovering anything new. The bottleneck isn't coding or understanding the task; it's choosing the right method and going deep enough.
Benchmark + NatureGym pipeline + public leaderboard, all open. Come run your agent. 👇
🤗 [huggingface]
https://t.co/iVOE6iiy46
🏆 [leaderboard]
https://t.co/AOea8Cw41L
w/ @Tsinghua_Uni@FrontisAI
@m1nj12 Thanks! Every task keeps its source paper. The full list of all 90 papers (title + DOI + domain) is in manifest.jsonl on the HF dataset:
https://t.co/bRljwRIqxE
Filter domain == "Protein Biology" for the protein tasks.
NatureBench
90 tasks from Nature-family publications spanning 6 scientific domains.
Frontier coding agents are tested against published SOTA results.
Can they discover new solutions, or only reproduce existing ones?
The strongest agent surpasses SOTA on just 17.8% of tasks
6/6
The whole protocol on one page:
sealed container, no web search, 4h + 1 GPU, scored against each paper's published SOTA, with a post-hoc judge filtering shortcuts.
Benchmark + NatureGym pipeline + leaderboard, all open. Go beat 17.8%. 👇
📄 [HF link]
https://t.co/iVOE6iiy46
🏆 [leaderboard]
https://t.co/uZLuu0G0xz
💻 [GitHub]
https://t.co/sULt8omWEa
5/n
And it's broad, not a toy set.
90 tasks · 333 instances · 6 scientific domains · 81 distinct primary metrics, distilled from 6 Nature-family journals (2022–2025).
Spanning sequence, structure, single-cell, imaging, spectra, graphs — prediction to generation. This is the spread that makes the difficulty gradient meaningful.
4/n
Where NatureBench sits vs prior work.
Paper-based benchmarks test reproduction. MLE-bench-style benchmarks test optimization — but on Kaggle, not science.
NatureBench is the only one that checks all three: paper-sourced ✓
real scientific domains ✓
beat-the-SOTA optimization ✓.
3/n
Why this measures discovery, not reproduction 🧱
Each Nature paper is rebuilt into a containerized task — but an information firewall strips out the original method. The evaluator and ground truth stay locked away from the agent.
It gets the data and the problem. It does not get to copy the answer.
2/n
The single most telling figure in the paper 👇
Left: Claude Opus 4.7 calmly climbs past SOTA in 6 submissions (g=+0.177).
Middle: GPT-5.5 fires off 258 submissions, peaks at #220 — and still lands below the line (g=−0.14).
Right: DeepSeek times out; beam search lifts Top-1 from 13.7%→58.5%, still short.
"Runnable, but not strong enough" in one image.
1/n
The full leaderboard, sorted by Surpass-SOTA (g>0.1):
Claude Opus 4.7 leads at 17.8% → all the way down to MiniMax-M2.7 at 1.1%.
Look at the per-domain heatmap on the right: Relational & Cellular run warm, but Molecular Design and Biomedical are mostly empty.
Difficulty is wildly uneven — and all 10 agents agree on the ordering.
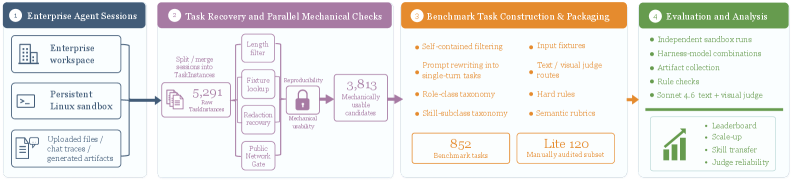
EnterpriseClawBench
A benchmark for enterprise coding agents distilled from real workplace sessions.
It evaluates complete harness-model systems on artifact delivery, cost, runtime, and skill transfer.
Even the best configuration only reaches 0.663.
🚀 Introducing EnterpriseClawBench — an enterprise agent benchmark built from real workplace sessions, not synthetic tasks.
852 reproducible tasks distilled from proprietary agent sessions at a 100+ person AI startup. Agents must read messy files, call tools, and ship actual business artifacts.
🧵 The twist: we deliberately don't release the data (it's internal). The reusable contribution is the construction + evaluation protocol — a recipe you can run on your own private session archive.
📊 We evaluate 32 harness×model combos, not just model names. And a single score hides everything that matters:
Even the best config (Codex + GPT-5.5) hits only 0.663. Enterprise artifact tasks are far from saturated.
🔍 Findings worth your time:
• Harness×model coupling is real — Claude models drop hard under some harnesses despite same model
• Visual LLM judges are still poorly calibrated vs text judges
• Skill transfer is high-variance: creator quality ≠ consumer quality
📄 Paper on HF Daily Papers (an upvote helps a ton 🙏): https://t.co/9kwljaGftW
💻 Leaderboard + pipeline: https://t.co/0kfk7Gmbte
Built by @FrontisAI
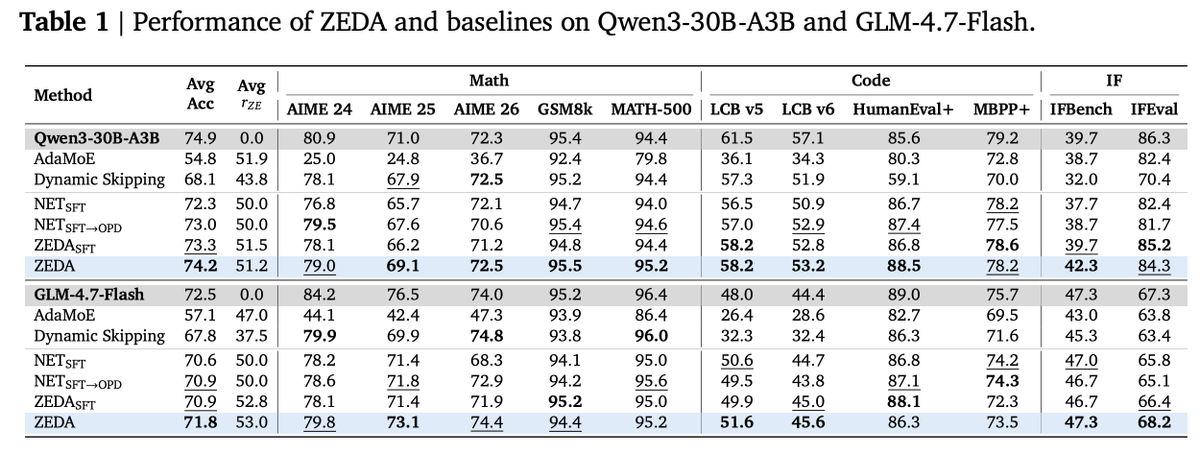
A large MoE model may be wasting half its expert compute on tokens that barely need expert help.
In this paper 50% of expert computation removed, with almost no loss in accuracy.
This makes already-trained MoE models like Qwen3 and GLM stop calling half their experts when a token is too easy to need them.
Zero-Expert Self-Distillation Adaptation (ZEDA), a low-cost framework that transforms post-trained static MoE models into efficient dynamic ones.
Shows that many MoE tokens do not need real experts, only permission to skip them.
That sounds like a small routing trick, but it changes the economics of deployed language models.
Standard MoE models already avoid using every parameter, yet they still spend the same expert budget on every token.
ZEDA adds a strange new option to the router: experts that output exactly nothing.
When the model routes a token to one of these zero experts, it is not making the model dumber; it is admitting that this token does not need another expensive transformation.
The clever part is not the dummy expert, but the adaptation method.
Instead of retraining the model from scratch, the original MoE becomes a frozen teacher, while the new dynamic version learns when it can safely skip work.
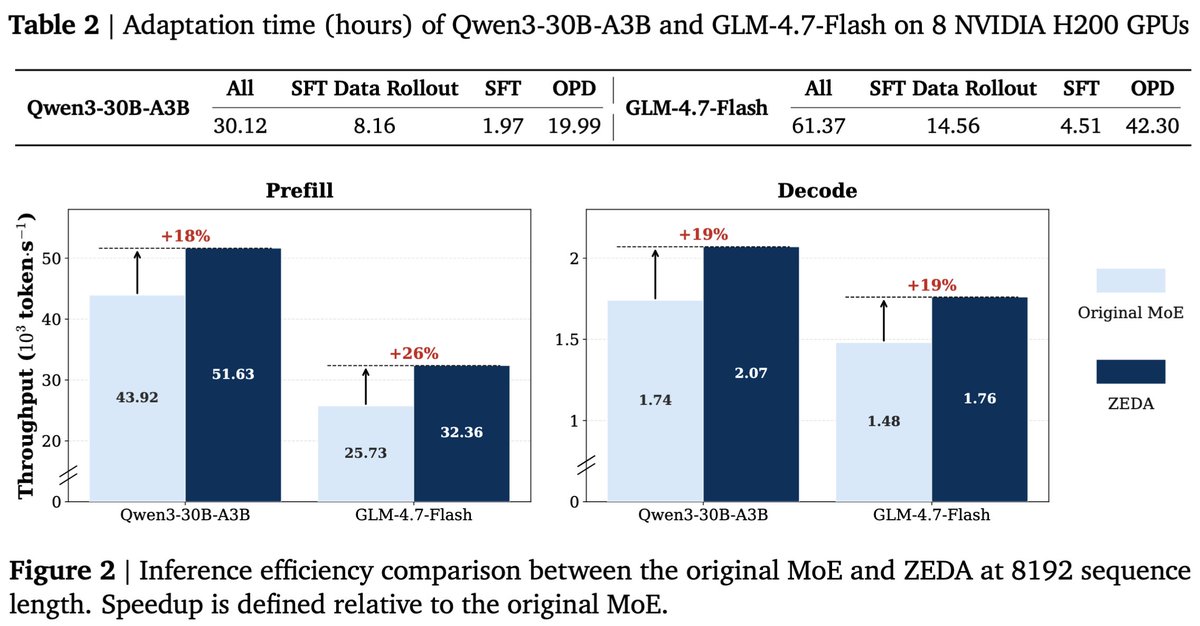
Across Qwen3-30B-A3B and GLM-4.7-Flash, the result is roughly half the expert computation removed, with only marginal average accuracy loss and about 20% real inference speedup.
The deeper finding is: compute use did not simply track task difficulty.
The model spent more expert budget where uncertainty or teacher-student disagreement rose, while structured code and math fragments often needed less.
That makes ZEDA feel less like pruning and more like attention to computational doubt.
----
Paper Link – arxiv. org/abs/2605.18643
Paper Title: "Post-Trained MoE Can Skip Half Experts via Self-Distillation"
(3/3)
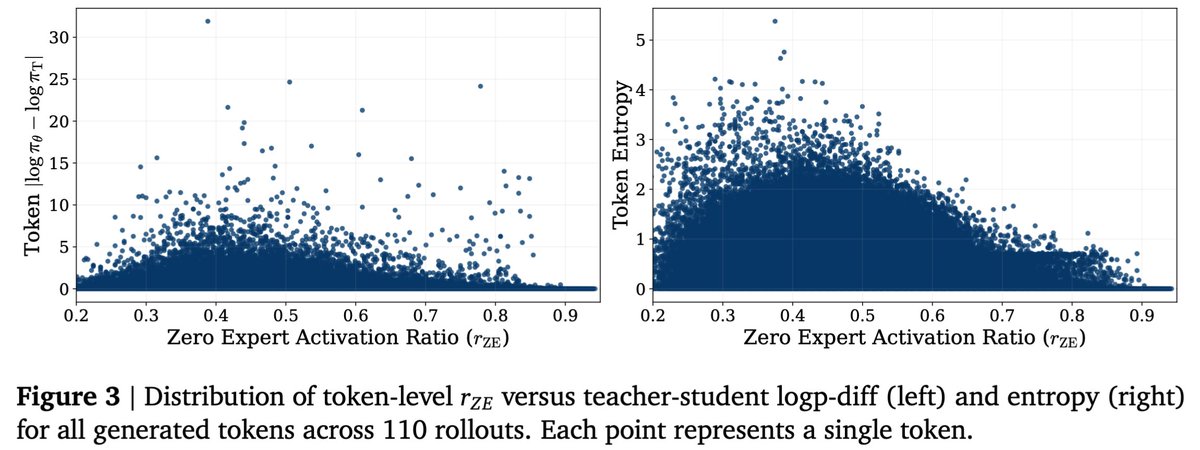
🔍 What does the model choose to skip?
We study zero-expert activation dynamics to connect dynamic MoE compute with interpretable signals:
📈Strongly correlated: teacher–student logp gap, entropy, response pattern.
📉Not correlated: task difficulty.
Work co-led by @taitel1321401 and @li_sheng9337
⚡ Want faster post-trained MoE inference with lower serving cost? We introduce ZEDA: let your MoE skip half the experts!
🤔 Post-trained MoEs activate the same number of experts for every token — easy and hard ones alike. That's wasted compute.
We introduce ZEDA: a lightweight recipe that turns a post-trained MoE into a dynamic MoE, skipping >50% of expert FLOPs with marginal accuracy loss.
🚀 ~1.20× end-to-end speedup
🧩 No pre-training, no router surgery
⏱ <62h on 8×H200
👉 Check out more details about ZEDA!
Paper: https://t.co/J8RTcyPrbM
Code: https://t.co/UliPINFrhf
(2/3)
📊 ZEDA results in one shot:
1️⃣ >50% expert FLOPs removed with marginal accuracy loss on Qwen3-30B-A3B & GLM-4.7-Flash across 11 hard benchmarks.
2️⃣ ~20% real inference speedup.
3️⃣ <31h / <62h adaptation on 8×H200 GPUs.
(1/3)
🧩 The secret to stable post-trained MoE → dynamic MoE adaptation?
Migrating a post-trained MoE to a dynamic one is trickier than training from scratch or adapting a pre-trained MoE. The key points: Don’t shock the router.
✅Zero experts ❌copy experts: no scale/direction mismatch.
✅Group-level balancing ❌expert-level aux loss: control compute while preserving learned routing.
✨What if the simplest RL recipe is all you need?
Introducing JustRL: new SOTA among 1.5B reasoning models with 2× less compute.
Stable improvement over 4,000+ steps. No multi-stage pipelines. No dynamic schedules. Just simple RL at scale.
📄 Blog: https://t.co/RofiFx9bl8
Excited about the surge in Agent Memory research?
With breakthroughs in Context Management and Learning from Experience powering self-improving AI agents, check out this curated Awesome list :
https://t.co/jv8ymy1yjL
Essential resources for building smarter, context-aware agents in 2025!
#AI #Agents #Memory














![OkhayIea's tweet photo. Everyone's racing to build "AI scientists." So we asked a blunt question:
Can today's best coding agents beat the published SOTA of real Nature papers — on their own, no web search, with the original method hidden?
🧬 Introducing NatureBench: 90 tasks distilled from Nature-family papers. The best agent (Claude Opus 4.7) surpasses SOTA on just 17.8% of them.
And here's the uncomfortable part — when agents do win, they mostly win by quietly reducing science to supervised ML, not by discovering anything new. The bottleneck isn't coding or understanding the task; it's choosing the right method and going deep enough.
Benchmark + NatureGym pipeline + public leaderboard, all open. Come run your agent. 👇
🤗 [huggingface]
https://t.co/iVOE6iiy46
🏆 [leaderboard]
https://t.co/AOea8Cw41L
w/ @Tsinghua_Uni @FrontisAI](https://pbs.twimg.com/media/HLj2MoaWgAAELU3.jpg)

![OkhayIea's tweet photo. 6/6
The whole protocol on one page:
sealed container, no web search, 4h + 1 GPU, scored against each paper's published SOTA, with a post-hoc judge filtering shortcuts.
Benchmark + NatureGym pipeline + leaderboard, all open. Go beat 17.8%. 👇
📄 [HF link]
https://t.co/iVOE6iiy46
🏆 [leaderboard]
https://t.co/uZLuu0G0xz
💻 [GitHub]
https://t.co/sULt8omWEa](https://pbs.twimg.com/media/HLj5JlobIAAX0HB.jpg)