Great interview with Fields medalist Terrence Tao.
We've spent a lot of resources driving the cost of idea generation to near zero. But knowing which ideas are good/correct is still human work and it's now the main bottleneck.
This is where @OlenaProtocol comes in. It can scale human judgement to meet this avalanche of ideas because it's not closed and credential based.
It's open, outputs on truth-telling and reputational incentives, and can handle any type of question.
@0xCramJam In the end the same as everyone else. We had a number of bugs and spec drifts and were having to implement fixes that were shifting the leaderboard a lot. We thought it fairest to just give every participant the same amount in the end. This applies to comp 1 only.
Rewards for Olena’s 1st competition are live.
You can now claim your rewards here:
https://t.co/zF6YbYcz2c
Just log in and tap the 🎁 icon to view your rewards.
Select “Claim Rewards” to receive your Olena Reward Tokens (ORT) in your wallet.
The first Olena forecasting competition has ended. Thanks and well done to everyone that participated.
We're very happy with how the aggregator has performed. Despite relatively small sample sizes of approx 50 per question, Olena consistently produced sharp forecasts on uncertain topics.
On the individual scoring side of the ledger, we had to fix an info score bug midway through the competition. We've also noticed the crowd-fit z-scores can blow up on certain condensed distribution questions - something we need to rectify to maintain the info score/crowd-fit score balance that is essential for honesty incentives. Finally there was an implementation vs spec drift on the monthly leaderboard that caused negative scores to not be counted.
Given all of this, and given the fixes to the two last issues mentioned would cause a lot of movement on the leaderboard after the completion of the competition, we've decided the fairest thing to do here is reward all first competition participants equally while reorganising the overall leaderboard according to intended mechanism behaviour.
We will settle the competition and pay out the reward tokens soon. Over the next two weeks we're going to attend to the mechanism issues and make the UI *a lot* more intuitive before we launch competition 2.
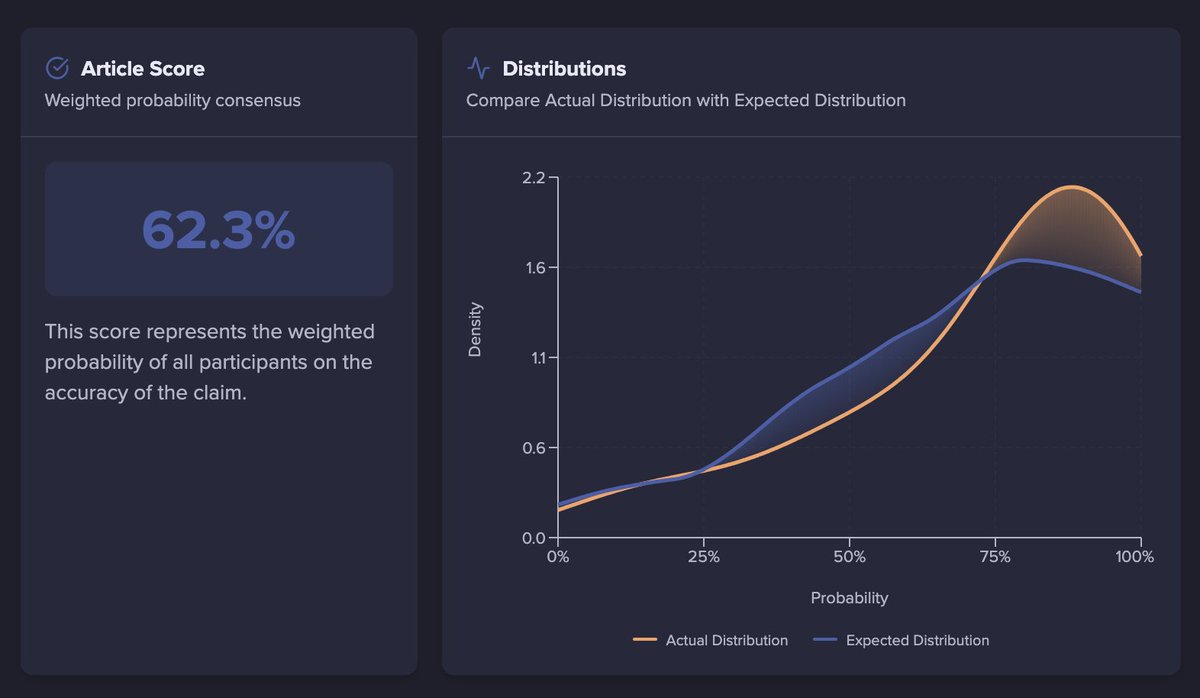
Exhibit A: Polymarket. $13.3m dollar traded. Odds of 61% for eventual winner.
Exhibit B: Olena. Tiny fractions of that dollar number spent. Odds for eventual winner 62%.
What's more interesting is look at the surprisingly popular hump. The sharps on Olena had the odds at about 90%. When track records develop more, these sharps will drag the aggregate towards them a lot more.
But even now, in beta, with comparatively few users, Olena beat Polymarket.
Our product is our forecasts. If VP isn't scarce, and anyone can answer any question without cost, we won't have good forecasts.
There was enough VP to anwer 1-2 questions per day and we communicated to users to allocate it wisely. That wasn't enough for many so we need to improve those comms but we are sure we need to grow users within certain constraints if we're to be successful.
Pleased to report this bug is patched. We've replayed the first 11 markets with the patch in place and are now in the process of beginning to settle all outstanding markets.
Expect a lot of leaderboard movement!
We found a scoring bug in our information score leg.
In plain English: we cap how much “surprise credit” anyone can earn from landing in an under-predicted region to stop tiny samples creating crazy spikes.
But a calculation issue made the expected mass look too small across the board. That meant almost everyone has been hitting this cap, and after normalisation everyone’s info score was zero (because you can’t rank people when they’re all identical).
The fix is relatively straightforward and already in progress. We'll defer all pending market settlements until the fix is in place.
It has come to our attention that a lot of users have run out of VP.
We warned you!
Anyway lessons learned for all of us. We're going to reduce conviction range to 1-3 VP and add a banner reminding everyone every day to pick their battles rather than trying to have a say on everything.
If VP isn't scare we won't get good forecasts but we don't want people to run out before competition end either. So we'll try find a happy medium.
Good to learn these things before we ramp up distribution.
Users that do well in our peer prediction competitions will be ones that not only focus on topics they know something about in the first place, but also spend time modelling how the crowd will respond.
Guard your VP *preciously* and the reward tokens will come.
Olena Asks: How likely is this claim?
By 2028, a major economy other than the US will decide to keep fossil power online longer because AI is arriving faster than clean power can replace it.
https://t.co/GEsu2o5uW3