ShinyProxy is the solution to deploy data science apps (#Shiny, #Dash, #Streamlit, #Jupyter and more).
v3.2.1 sees improvements to the ECS backend. Also, it contains multiple fixes for XSS vulnerabilities.
Check out the release notes at https://t.co/65kNyX4TsX
#opensource
#opensource#rstats pipeline and #shiny app to build high-quality molecular databases and lay the data foundation for #ai models in medicinal chemistry.
🔗 Explore the article here: https://t.co/CZjpHycwi3
💻 Try out the prototype of the customized app: https://t.co/dkT3JB4n93
RDepot is enterprise-grade #opensource software to manage #rstats and #Python repositories. In v2.5.1 packages built for a specific Linux distribution, architecture and R series can now be stored for blazingly fast installation. More goodies at https://t.co/N8ptccJoul
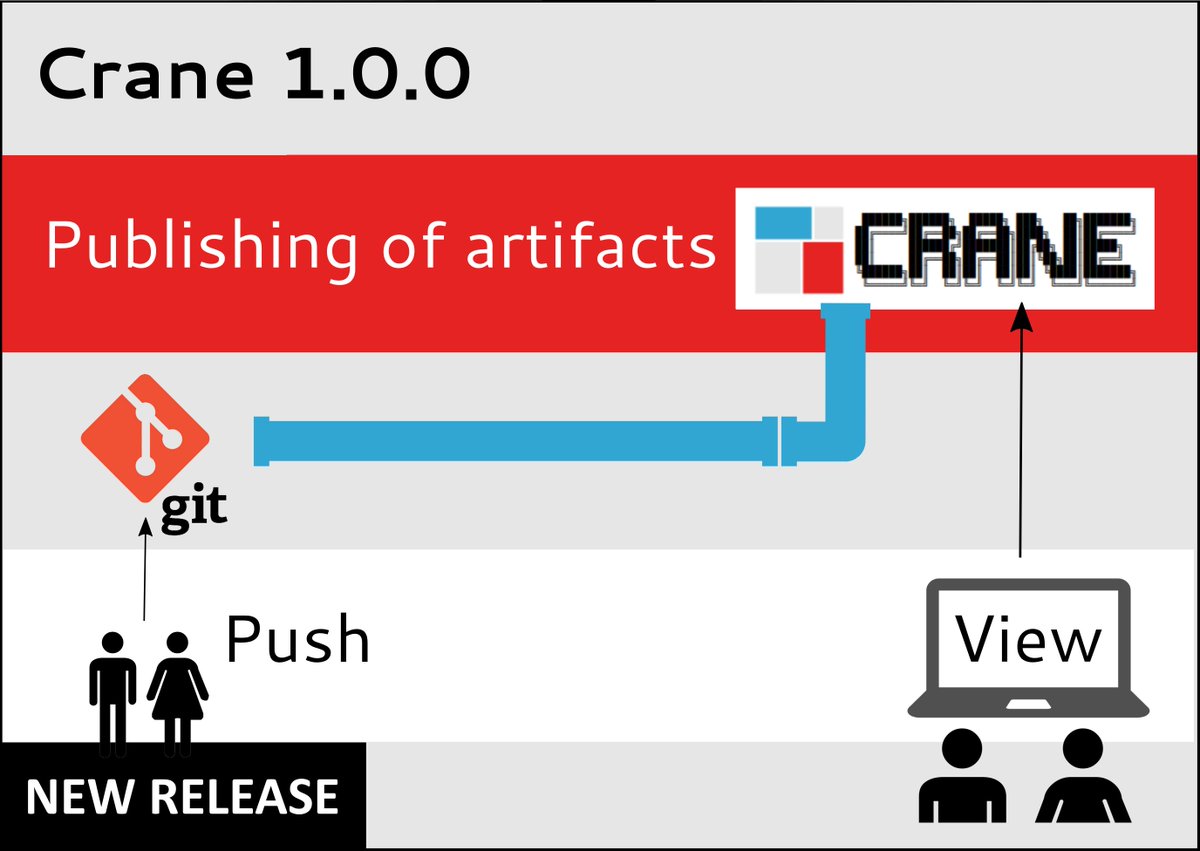
Crane is a new #opensource product to host #datascience artifacts: reports, documentation sites, or packages and libraries. Part of our FOSS suite to build data science platforms and playing well with ShinyProxy and RDepot. Read more at https://t.co/95Nh0DnjJb #rstats#python
@jhngrant@swardley The 'tiny subset' I mention does not refer to the harmful content (to be addressed through a data commons with contributor agreements), but rather to a subset of the data types that are used in ML. If you predict response to drugs based on omics, you use omics data (not a corpus)
@swardley@jhngrant Indeed. Collective and intentional management as a shared resource is possible for this type of data: no need to scrape the ocean floor to catch fish (and throw all else away). Also, this type of data is a tiny subset of all data types one can train ML models on; AI > ML > LLMs.
@jhngrant@swardley Many thanks for the interesting reference. Illegal content should not be in anyone's possession and therefore should not end up in a training dataset. This seems a problem to be solved upstream of Open Source AI. It does mean you cannot take shortcuts by using unguided crawling.
@jhngrant@swardley We mentioned being practitioners of open source data science (navigating the challenges of both open source and ML) since you mentioned being an open source advocate ('trust me, I am an open source expert'), but happy to go over these challenges 1 by 1.
@jhngrant@swardley We are a #DataScience consultancy specialized in #OpenSource data science and are knee-deep into the practical realities of #AI development (since 15+ years). Based on that experience, we do not see any valid arguments to dilute the meaning of open source in an AI context.
@jhngrant@swardley There is nothing ideological about it. There is a clear definition of open source that refers to 4 freedoms. If you apply these 4 freedoms to AI, then you need the training data to be able to meaningfully understand and modify (2 of the 4 freedoms) the resulting models.
@jhngrant@swardley We agree, of course, but not having access to the training data severely reduces the freedom to understand and to modify. You can not reasonably call something 'open source AI' if it does not respect the basic four freedoms that define the idea of open source.
@jhngrant@swardley Start from the four freedoms (a.o. freedom to study and to modify) and you can only end up with needing the training data. Otherwise both of these (modify and study) are severely limited. 1/2
Shinyproxy 3.1.0 release: https://t.co/dhJaHlEoVl
many new features, my highlights are container pre-initialization and support for IPC. Container sharing may also be interesting, but I need to test it. @OpenAnalytics
ShinyProxy 3.1.0. Instant access to your apps through container pre-initialization. Container sharing for massive deployments. #AWS ECS backend and more. Blog post at https://t.co/lqPcrZyg8Z and release notes at https://t.co/0wV055jBEr. #opensource#datascience#python#rstats
A selection of our athletes running for #UNICHIR.
BENISUR - UNICHIR provides high-quality surgical and obstetric care to almost two million people in Beni, Eastern #Congo.
If you want to learn more or make a donation: https://t.co/Dgq4kgeClV
The expiry dates on pharmaceutical products are the result of extensive research. We just published a Bayesian methodology to predict shelf life in a more robust and interpretable way. Here's the paper: https://t.co/zMFTpExTHC #Bayesian#Statistics#Pharmaceutical