What's in a neuron? 💫 (an atypically long, almost personal post)
Neurons in LMs have always been a fascinating object to study. I've been studying them since 2020, viewing them as key-value memory cells, analyzing what they capture in vocabulary space, and how they compose together to form features.
https://t.co/jHiZ7wLmrH
https://t.co/tYgtR6vxNi
https://t.co/eZfHTnVrgp
https://t.co/kukRY6RsDU
But many neurons still remain opaque! They do many things.
Our recent work led by @AsafAvrahamy tackles this challenge by decomposing neuron weights in vocabulary space. We do this by taking the neuron weight vector and learning different ways to rotate it (just a bit) to reveal monosemantic vocabulary channels that it captures. The nice thing about our method ROTATE is that it's data-free and super efficient, relying only on vocabulary kurtosis as a search signal.
I've been thinking about this idea since 2024, proposed it to multiple students, but only Asaf was brave enough to take this ;)
Very happy with the final outcome. Check out the paper! 👇
https://t.co/oHLMAtY1F0
Can we tell when LLMs are being unfaithful in their chains of thought?
We evaluated 8 methods claiming to do this, and found that most perform near chance!
But evaluating this requires us to have ground-truth labels for CoT faithfulness. How can we obtain these?
1/ New preprint!
Linear directions are everywhere in mech interp. But a bag of linear directions fails to capture meaningful structure! Could there be more going on?
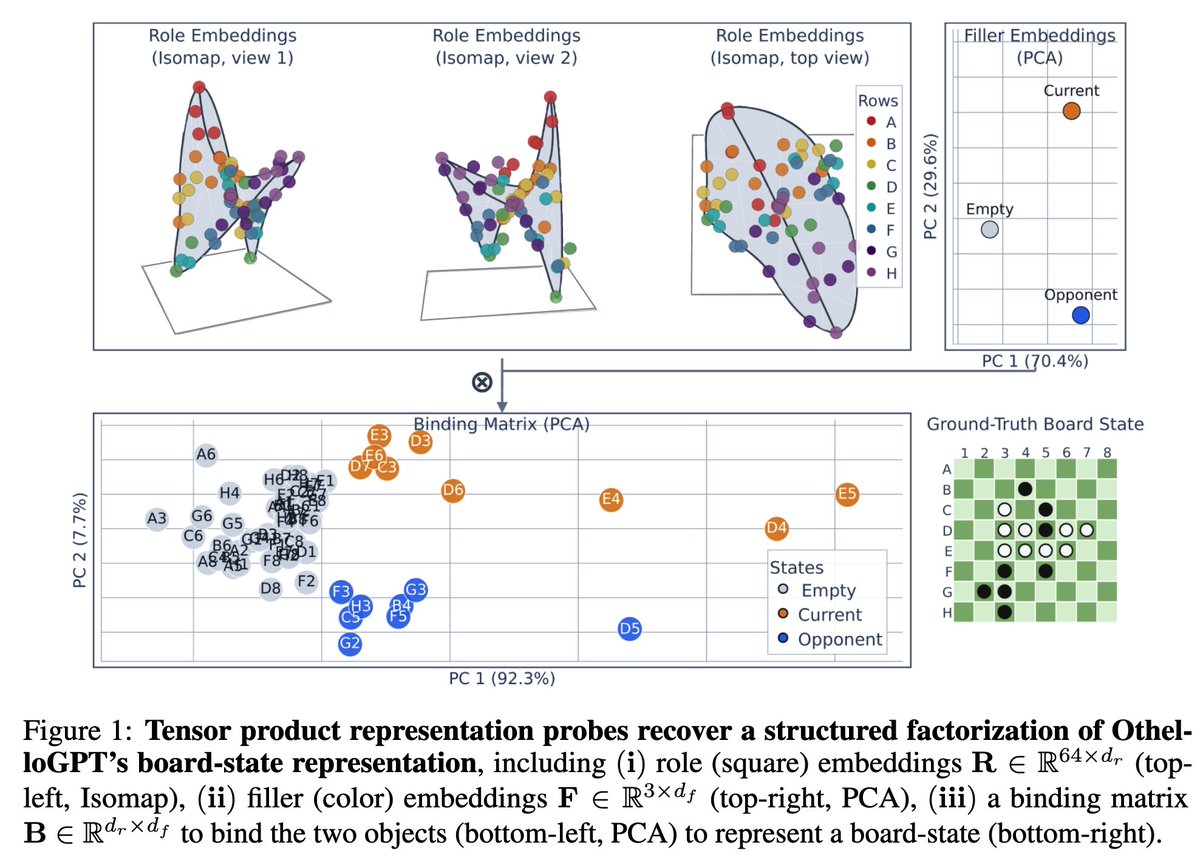
We revisit OthelloGPT, which is known to have linear representations but is trained in a highly structural domain of the board game Othello.
Originally, @NeelNanda5 and I found 192 linear directions (64 squares x 3 colors) that can decode the entire board-state.
In this work we use tensor product representation probes (TPRs) to decompose these linear directions into role (board) embeddings, filler (color) embeddings, and a binding matrix that compose the two to reconstruct board-state (see last tweet for technical details).
(Note that this does NOT mean the model has a separate board / color subspace. This is not our claim - rather, a set of linear directions can be factorized into structurally meaningful components.)
@junsik_yoo@megamor2 That’s a really interesting way to look at it. I’d be happy to chat more. Feel free to ping me after the 20th whenever works for you.
@nrol_ling@megamor2 Thanks! Great question, MFA still gives global coherence through the centroids, while the local geometry enables more fine-grained steering. I think a nice way to see it is adding local control on top of global structure, not replacing it.
MFA (Mixture of Factor Analyzers) is a new unsupervised approach to disentangle representations of LLMs at scale, using local geometry
MFAs outperform large-scale SAEs in localization and steering while providing interpretable decompositions
To be presented at #ICML2026 🇰🇷
Code and trained MFAs are available at:
https://t.co/5ycGU3bMXG
😻New preprint! As an interp researcher, I often ask “why did the model attend to this token?” We study this by decomposing the query-key (QK) space into interpretable low-rank subspaces. When these subspaces of Qs and Ks align, the model produces high attention scores.
1/N
@dana_arad4 It’s a good question, I agree feature selection matters a lot for SAE steering, but it also highlights the inherent differences in the units of analysis. It's an interesting point to keep in mind, thanks for flagging it.
It's time to look past dictionary learning for decomposing LM activations.
What happens when we instead leverage local geometry?
We find a natural region-based decomposition that yields better steering and localization 🧵 1/
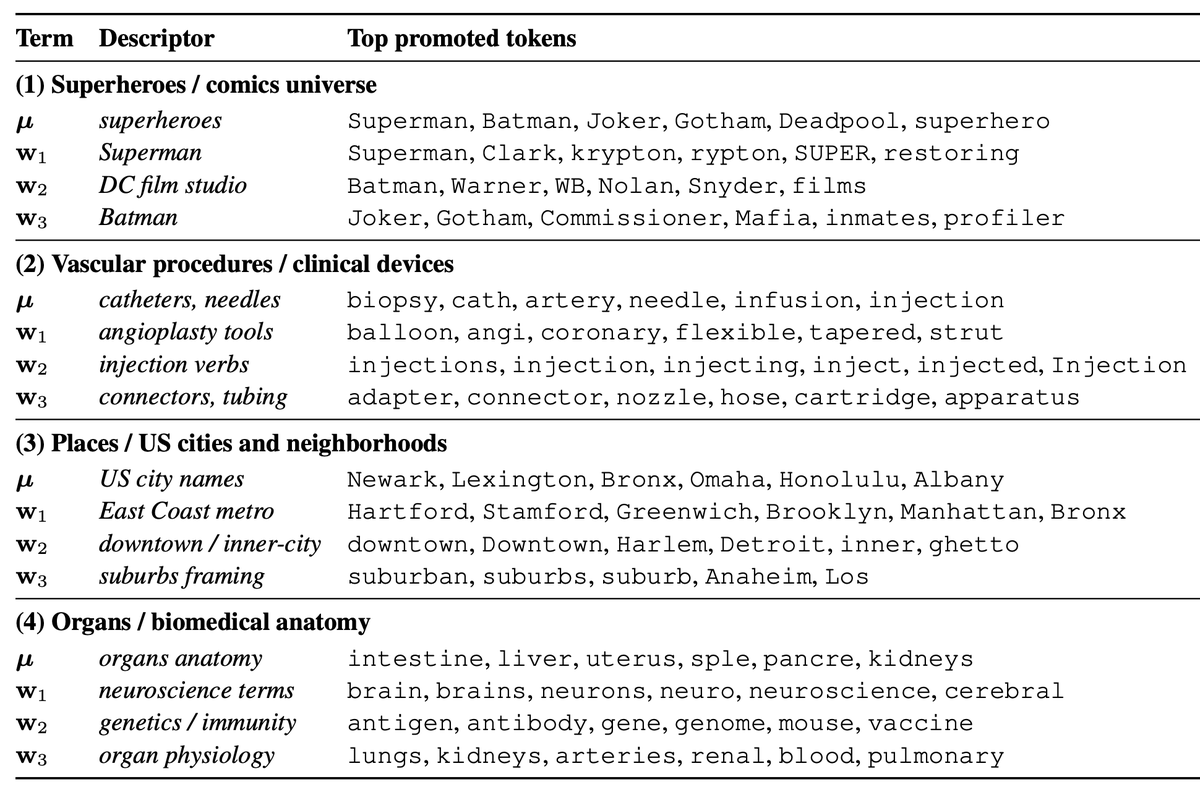
MFA offers a new lens on activation decomposition, shifting the focus from fitting global directions to uncovering the local geometry that actually organizes model behavior. 8/
🔗 Paper: https://t.co/bf2aYXU7G5
🔗 Code and MFA models: https://t.co/Pez2rSrPC5
Fine-grained Steering 🏎️
We often see a causal split: 1️⃣ Centroids promote broad topics (e.g., "Superheroes"). 2️⃣ Local variation captures specific sub-concepts (e.g., "Batman" vs. "Superman"). 7/
@YNikankin@megamor2 Thank you! In the paper we used 9k inputs, but for other experiments that we didn't include we factorized around 100k. In terms of time, we didn’t do include measurements, but from experience the algorithm converges on an H100 in a couple minutes.
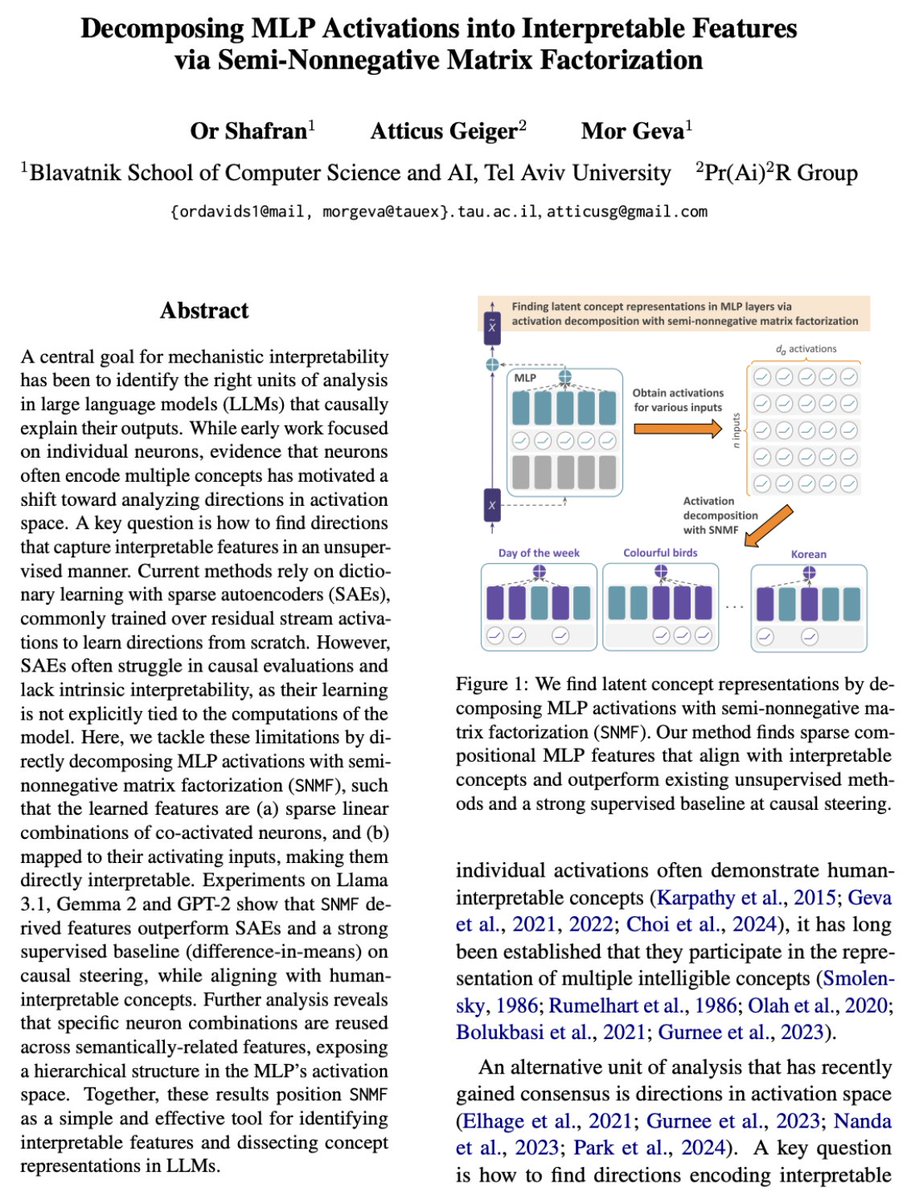
✨MLP layers have just become more interpretable than ever ✨
In a new paper:
* We show a simple method for decomposing MLP activations into interpretable features
* Our method uncovers hidden concept hierarchies, where sparse neuron combinations form increasingly abstract ideas