Ph.D. student @berkeley_ai | Cur./ Prev. Intern @meta @amazon
Working on Transferable and Scalable RL for Robotics.
Do elegant research trivial in hindsight.
Real-time Chunking (RTC) is designed to enable smooth asynchronous execution of flow-matching policies. However, it has some critical limitations: its inpainting-based async execution capability comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning for better performance (e.g. training-time RTC), heuristic guidance, and extra computation that inflates the latency.
In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once, being simpler to implement, faster at inference, and better at execution.
Paper: https://t.co/SbpNCQMBF1
Code: https://t.co/fQyT6NR2eE
Website: https://t.co/jLiCogvxoa
RTC is a key ingredient for deploying high-latency VLA policies in real-time. We show that discrete diffusion is a more natural fit for asynchronous execution: with no extra implementation or specialized fine-tuning, it achieve strong performance on dynamic manipulation tasks!
Real-time Chunking (RTC) is designed to enable smooth asynchronous execution of flow-matching policies. However, it has some critical limitations: its inpainting-based async execution capability comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning for better performance (e.g. training-time RTC), heuristic guidance, and extra computation that inflates the latency.
In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once, being simpler to implement, faster at inference, and better at execution.
Paper: https://t.co/SbpNCQMBF1
Code: https://t.co/fQyT6NR2eE
Website: https://t.co/jLiCogvxoa
(5) In real-world dynamic manipulation tasks that Sync baselines completely fail , DiscreteRTC outperforms ContinuousRTC with a huge gap on the Hockey Defend and the Dynamic Pick where the reactiveness is critical for success. Moreover, ContinuousRTC inflates flow-matching cost with a near-1.7× overhead from the ΠGDM, whereas DiscreteRTC reduces discrete diffusion cost to around 0.7×. Even compared with training-time ContinuousRTC with extra fine-tuning efforts, DiscreteRTC can still outperform with higher action qualities and success rates.
(4) DiscreteRTC requires fewer iterative steps than ContinuousRTC with fewer tokens to unmask during inpainting. Moreover, DiscreteRTC can outperform Training-time ContinuousRTC , improves with more steps, and the backbone policy can be seamlessly combined with advanced inference-time methods like VLASH for further gains.
(3) Under different inference delays, DiscreteRTC consistently outperforms ContinuousRTC and other variants on both solve rates and throughputs, showing the advantage of the native inpainting capability in discrete diffusion policies.
(2) In contrast, we show that discrete diffusion policies can naturally resolve all the aforementioned limitations at once.
(a) Inpainting as Pre-training. Discrete diffusion policies are pre-trained to inpaint upon randomly masked sequences. Therefore, scaling pre-training directly improves asynchronous performance, and the native forward pass suits inference-time inpainting;
(b) Fine-tuning Free. As a consequence, inpainting-specific patterns are implicitly introduced during pre-training, making discrete diffusion a fine-tuning-free approach for high-quality, out-of-the-box asynchronous execution;
(c) Natural Guidance. Moreover, with discrete diffusion policies, we can early-exit inference once the necessary action tokens are unmasked, leaving the remaining masking pattern as an adaptive and natural guidance for the next inference;
(d) Lower Inference Cost. Finally, with committed tokens from previous chunks, the tokens to unmask per inference are reduced, leading to lower inference cost for inpainting.
(1) We identify 4 limitations to apply RTC with flow-matching policies:
(a) Pre-training w/o Inpainting. Flow-matching policies are not pre-trained with inconsistent noise for inpainting. Therefore, scaling pre-training does not directly improve asynchronous performance, and inference-time corrections are inevitable for inpainting;
(b) Fine-tuning Required. As a consequence, adequate inpainting quality demands a dedicated fine-tuning stage with techniques such as action-suffix conditioning to explicitly introduce the inpainting-specific noise pattern into training;
(c) Heuristic Guidance. Moreover, to better leverage the previous action chunks, ΠGDM requires a heuristic schedule fixed across different inference-time cases;
(d) Extra Inference Cost. Finally, the correction guidance term at every denoising step roughly doubles inference cost, ironically increasing the very latency RTC aims to hide.
Excited that our paper StreamdiffusionV2 received the Best Research Paper Award at #MLSys26!
🚀Video generation is quickly moving from demos to production-facing workloads. It is no longer a turn-based pipeline but should be a streaming pipeline to interact with users.
📖Our project page: https://t.co/ItuO5zc6hT and paper: https://t.co/fmz2irYIm1
👂Come join the talk if you are interested in streaming video generation. Our talk will be at the Research Track Oral Presentation: Best Paper Session on Tue 8:45AM at #MLSys26 , I will talk about how we attacked the efficiency and quality challenges. Hope to see you there!
❤️Huge thanks to all authors! This work would not have been possible without the incredible effort from the entire team. Big shout out to Tianrui Feng, Zhi Li, @Andy_ShuoYang , @HaochengXiUCB, @lmxyy1999 , @lvminzhang , @xiuyu_l , Keting Yang, @ZiqiPeng, @songhan_mit , @magrawala, @KurtKeutzer , and @cumulo_autumn
Excited to share that three of my papers — DADP, REAR, and Mind Your Entropy — have been accepted to ICML 2026! Especially happy that DADP received reviewer scores of 5/5/5/4😊, whose cute idea is also recongnized by the reviewers and the community.
Truly grateful to all my collaborators for the insightful discussions, hard work, and support. Looking forward to continuing to work on more fun and exciting projects together.
DADP: https://t.co/Q6ITqOEOtO
REAR: https://t.co/yOziuGzSxP
Mind your Entropy: https://t.co/Og91Lc4awR
🤔The more I studied diffusion language models, the more I came to appreciate the simplicity of autoregressive (AR) language models. AR models are trained to agree with what they generate, and their serving stacks are built to preserve that structure. DLMs often do neither: they lack introspective consistency, and high TPF does not necessarily translate into high real-world TPS.
We propose Introspective Diffusion Language Model (I-DLM), which unifies introspection and generation in a single pass:
1. 🧑🎓I-DLM brings introspective consistency to DLMs with only 5B training tokens, achieving AR-thinking-level quality.
2. 🚀 I-DLM carefully trades compute for higher TPF while converting that advantage into real TPS under high-concurrency serving.
📖Website: https://t.co/826V7d49mA
⌨️Code: https://t.co/MPuy6rAXbq
Back in Nov we developed Recap and trained π*-06 with RL. Now, we developed a fast *online* RL method that improves π-06 with as little as 15 min of robot data for precise tasks, using "RL tokens" exposed by our model that can be fed into a small actor-critic method.
Imagine a single policy adapting aggressively across multiple embodiments and different domains—varying friction, mass, limb lengths. Can this be done online and zero-shot, without privileged environment parameters or retraining for each new domain?
We take a step toward this goal with DADP, a diffusion-based policy for domain adaptation. DADP learns domain representations in a self-supervised manner from interaction context and integrates them into the diffusion generation process by biasing the prior distribution and re-formulating the diffusion target.
Paper: https://t.co/cSsPA1Jmfc
Website: DADP: https://t.co/T5AmbLRUGp
Code (w/ Dataset & Checkpoints): https://t.co/RgssL0QJrR
More details below.
Imagine a single policy adapting aggressively across multiple embodiments and different domains—varying friction, mass, limb lengths. Can this be done online and zero-shot, without privileged environment parameters or retraining for each new domain?
We take a step toward this goal with DADP, a diffusion-based policy for domain adaptation. DADP learns domain representations in a self-supervised manner from interaction context and integrates them into the diffusion generation process by biasing the prior distribution and re-formulating the diffusion target.
Paper: https://t.co/cSsPA1Jmfc
Website: DADP: https://t.co/T5AmbLRUGp
Code (w/ Dataset & Checkpoints): https://t.co/RgssL0QJrR
More details below.
7/ Future directions
DADP focuses on extracting static information and discarding transient cues. But in many settings, domain parameters may vary as well, where those varying signals are also important. An interesting next step is to learn representations that preserve both.
At a broader level, DADP centers on a fundamental question: what should a representation capture in next-state/frame/token predictive training?
We believe this perspective has implications well beyond domain-adaptive control. In particular, it may help inform the next generation of world model pretraining, where the goal is not only to model the world’s dynamical evolution, but also to recover the persistent structure that governs it.
6/ Representation Utilization Ablations
We also discuss how the learned representation is utilized in the policy. The conclusion is very consistent: the full DADP design performs best.
We visualize the representation trajectories of conditional policy and the DADP policy, which shows clearly that the modulated diffusion greatly enhances the domain locating and downstream policy performance.
5/ Representation Quality Ablations
We evaluate the DADP representations by reconstructing the domain index and information. The trend is very clear: as the temporal gap increases, the representations become much more separable and informative, eventually reaching the qualities of Supervised Learning results.
So the superior performance of DADP is not just a matter of architectural luck. It starts from a better domain representation.
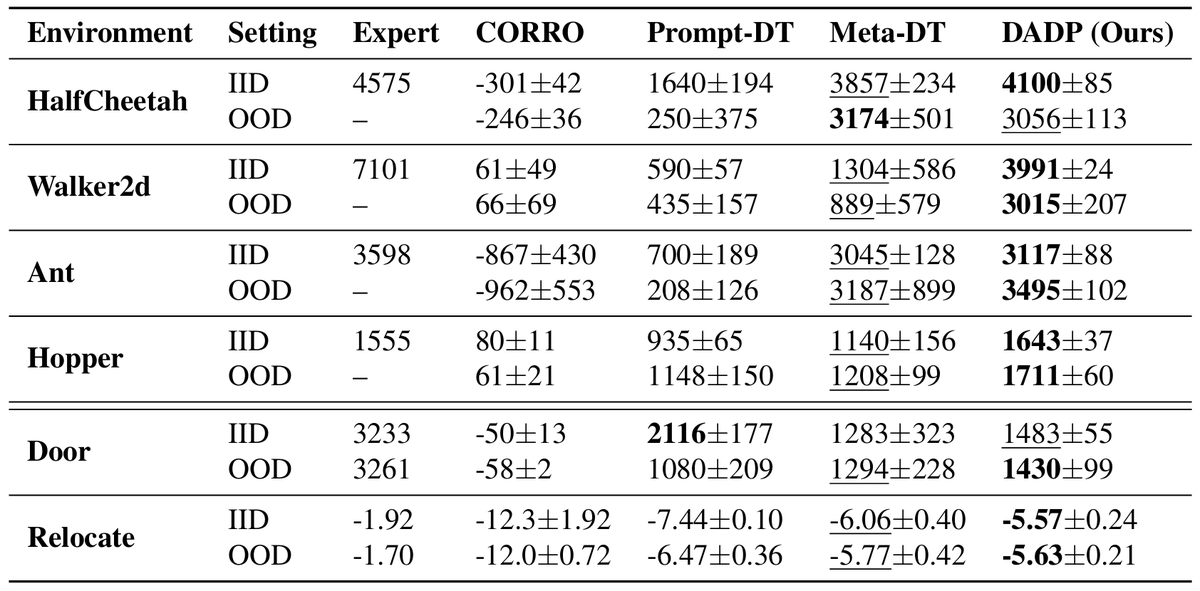
4/ Experimental Results
We evaluate DADP on MuJoCo locomotion and Adroit manipulation in the zero-shot setting, where test-time adaptation relies only on online-collected context. In this challenging setting, DADP consistently outperforms strong baselines, with stronger performance and greater stability across seeds.
Moreover, unlike prior work that often considers only minor domain randomization, our benchmarks include aggressive dynamics and morphological variations.
We also open-source the domain randomization and expert training pipeline to make these results reproducible and to support future research.