Replacing LLM tool routing with a 270M specialized model.
I fine-tuned 𝗙𝘂𝗻𝗰𝘁𝗶𝗼𝗻𝗚𝗲𝗺𝗺𝗮 to map natural language → function calls locally.
Deterministic, low-latency, no cloud costs.
Small model. Big implications for agents. 🚀
Big news for AI builders: NVIDIA dropped a quantized version of Qwen3.6 that fits in 35B parameters but runs like a 3B model. This FP4 MoE beast is a game changer for efficient inference.
SKILL.md is eating MCP Servers, and that's a good thing
Your MCP servers are burning 50,000 tokens just to teach an agent what a 200-token markdown file already knows.
Brad Feld runs an entire company on 12 skill files. No app. No workflow engine. Just markdown in a git repo.
Sentry's David Cramer says it bluntly. Many MCP servers shouldn't exist.
The problem? Teams keep building MCP servers for knowledge problems. But
MCP was designed for execution problems. The difference is costing you 50x in wasted context and worse agent reasoning.
I wrote the decision framework for getting this right.
What's your skill-to-MCP ratio looking like?
https://t.co/7xC39JPUjB
🚨 BREAKING: The Qwen team just shipped their official agent framework and it has everything.
No stitching together third-party libraries. No fighting abstractions.
Qwen-Agent gives you:
→ Native function calling built directly into the framework
→ Secure code interpreter sandbox out of the box
→ RAG and MCP support included
→ Chrome extension for browser-native agent workflows
Built by the team that built the model. So it just works.
100% open source and completely free.
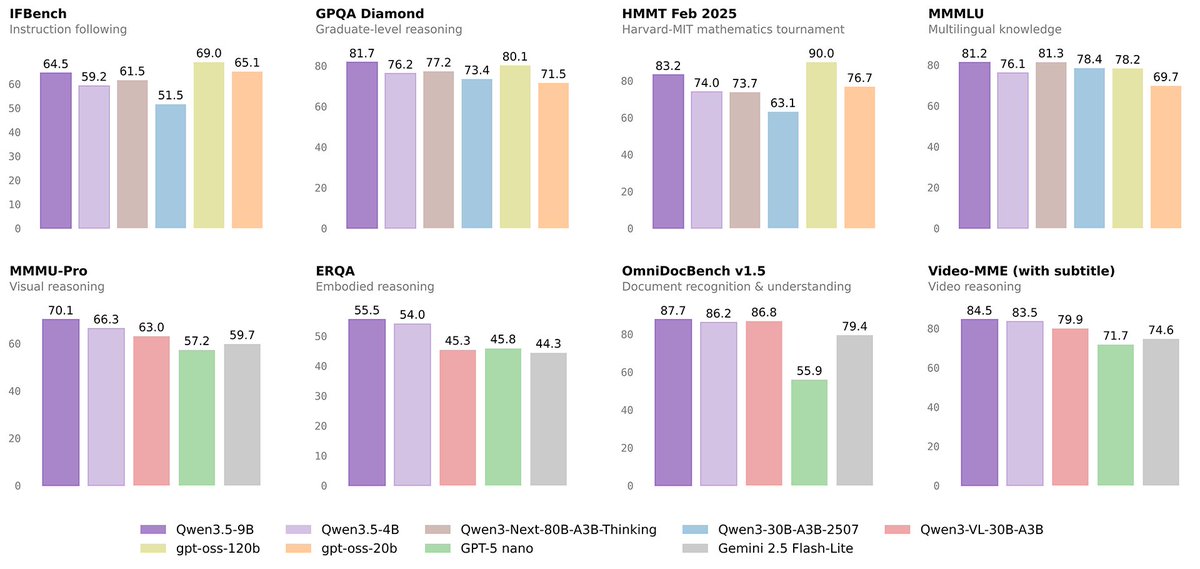
🚀 Introducing the Qwen 3.5 Small Model Series
Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
✨ More intelligence, less compute.
These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
• 0.8B / 2B → tiny, fast, great for edge device
• 4B → a surprisingly strong multimodal base for lightweight agents
• 9B → compact, but already closing the gap with much larger models
And yes — we’re also releasing the Base models as well.
We hope this better supports research, experimentation, and real-world industrial innovation.
Hugging Face: https://t.co/wFMdX5pDjU
ModelScope: https://t.co/9NGXcIdCWI
🚨 Alibaba just quietly dropped a vector database that destroys Pinecone, Chroma, and Weaviate.
It's called Zvec and it runs directly inside your application no server, no config, no infrastructure costs.
No Docker. No cloud bills. No DevOps nightmare.
Built on Proxima, Alibaba's battle-tested vector search engine powering their own production systems at scale.
The numbers don't lie:
→ Searches billions of vectors in milliseconds
→ pip install zvec and you're searching in under 60 seconds
→ Dense + sparse vectors + hybrid search in a single call
And it runs everywhere:
→ Notebooks
→ Servers
→ Edge devices
→ CLI tools
100% Opensource. Apache 2.0 license.
This is the vector DB the RAG community has been waiting for production-grade performance without the production-grade headache.
Link in the first comment 👇
I think data science is the most underrated skill in AI.
I think we will see a return of the data scientist
It's clear we will have increasingly complex, stochastic systems that will require data literacy, such as:
- How to sample, interpret, clean data to find issues
- How to design metrics that help maintain back pressure and prevent drift
- How to design experiments
Data scientists: your time is now.
The skills you've been quietly sharpening, experimental design, measuring what actually matters, translating business needs into numbers, are exactly what production AI demands most.
When anyone can generate anything using AI, taste and judgment are the differentiator. That's been data science all along.
Great take by @egealtan: https://t.co/DmMTv9G16p
claude code: I finished the feature you asked me to build. All tests are passing. Would you like me to commit these changes?
me: Please review your changes to make sure there are no mistakes.
cc: [working] … I found 5 mistakes and fixed them. All tests are passing. Ready to commit.
me: Please review your changes to make sure there are no mistakes.
cc: [working] … I found 3 mistakes and fixed 2. The third was pre-existing and unrelated to my changes. Ready to commit.
me: Fix the “pre-existing” mistake.
cc: [working] … I fixed the pre-existing mistake. Ready to commit.
me: Please review your changes to make sure there are no mistakes.
cc: [working] … No mistakes found. There is one failing test that was pre-existing, unrelated to my changes. Would you like me to commit these changes?
me: Fix the failing test.
cc: [compacting] … [working] … All tests are passing. Ready to commit.
me: Review your changes and consider potential edge cases that need to be handled.
cc: [working] … I found 2 edge cases that were not being handled. Both are now handled properly. Ready to commit.
me: Do those edge cases have tests?
cc: [working] … Both edge cases now have test coverage. Would you like me to commit these changes?
me: Yes.
Sufficiently advanced agentic coding is essentially machine learning: the engineer sets up the optimization goal as well as some constraints on the search space (the spec and its tests), then an optimization process (coding agents) iterates until the goal is reached.
The result is a blackbox model (the generated codebase): an artifact that performs the task, that you deploy without ever inspecting its internal logic, just as we ignore individual weights in a neural network.
This implies that all classic issues encountered in ML will soon become problems for agentic coding: overfitting to the spec, Clever Hans shortcuts that don't generalize outside the tests, data leakage, concept drift, etc.
I would also ask: what will be the Keras of agentic coding? What will be the optimal set of high-level abstractions that allow humans to steer codebase 'training' with minimal cognitive overhead?
Turn any website into LLM-ready data in seconds 🤯
This new open-source framework converts any website into clean data.
It crawls the URL and outputs perfectly formatted Markdown or structured JSON.
100% Open Source.
Highly recommended if you’re:
• Building data/BI agents
• Shipping GenAI to production
• Working in regulated environments
• Designing multi-agent systems
This course sets the right engineering bar.
Link: https://t.co/2mkIInQp3j
Just finished “Building & Evaluating Data Agents” — easily one of the best courses if you want to build enterprise-grade, production-ready data agents, not toy chatbots.
If you’re serious about deploying agents in real companies, this course is gold 🧵👇