Here comes the big announcement I've been holding inside for months! 👾
For those building AI agents, we've been seeing more and more how everyone eventually hits a wall where the computational price of ensuring reliability gets too high.
Then comes the inevitable and yet impossible choice between reliability and manageable costs.
But I'm excited to announce that this state of affairs changes today!!!
After **so much** community demand in the Parlant scene, for a solution to the accuracy/cost trade-off, we're excited to launch Emcie!
Emcie is our long-awaited, automatic SLM (Small Language Model) distillation platform for Parlant.
It makes it possible run the famously reliable Parlant agents with high accuracy, at minimal costs.
For those who've been struggling to balance agent reliability with operational costs, combining Parlant with Emcie could be your solution.
To try out our new models, sign up in the link (first comment)
🚀 Launching Parlant 3.1
[TLDR Speed, Accuracy, & Control]
@ParlantIO has seen incredible adoption in the past few months.
It's live in production with a few large financial institutions, and it also helps many small-to-medium businesses in use cases from healthcare, through legal, all the way to education and - get this - live troubleshooting of wind turbines.
There are more use cases that our open-source Conversational AI framework seems to excel at than we first had in mind.
Today - I'm excited to launch Parlant 3.1!
Since releasing 3.0 a few months back, we've listened to our community and collected an enormous amount of feedback and feature requests.
The additional feature list in this version is extraordinary. In terms of the experience, expect improvements in speed, accuracy, and — the real keyword of this release — CONTROL.
We've added multiple new control mechanisms in this new version that leverage and really show the power of Parlant's granular behavior control philosophy.
Be sure to check out the expanded announcement in the first comment.
One of the most common questions we get from teams using @ParlantIO is how to reduce costs while maintaining Parlant's exceptional instruction-following reliability.
It's always been a fair question. Historically, we've always prioritized accuracy and reliability over costs... and we didn't make any money from it, either, because you can use any LLM you want. It's just always been a challenge to optimize.
Parlant's guideline matching engine is thorough - and it has to be to get agents to actually follow your instructions consistently. But that thoroughness always had to come with compute overhead.
But recently we've finally been able to do something that we've talked about for a long time - in fact, for the past 18 months. It's based on the following realization: 💡 Not every instruction actually needs that level of rigor and conformance. And it turns out that this seemingly small fact opens the way for serious engine optimizations.
I wrote up our thinking on this - the problem, the research we looked at, how we've arrived at a really nice solution - which will be released *very* soon with Parlant 3.1. https://t.co/yELcML5kTD
Would love to hear if this matches what you're dealing with, whatever framework you're currently using. We're still iterating on this before 3.1 ships.
There's a specific gravity that hits when you realize 15+ million people are about to interact with the software your team just put into production.
Especially when this software is an LLM agent directly interacting with a large company's customers.
We all know how AI agents look awesome in demos. But when you move from 100 testers to millions of users, the math of instruction-following and compliance changes completely.
A 1% error rate is a minor bug in a small use case. But in a major bank, there are thousands of potential compliance and other business-critical violations.
I’m incredibly proud to share that a large bank in Asia has officially placed the @ParlantIO framework into production. As far as I know, they might be the first bank in the world with a true LLM agent that does more than answer the most trivial of queries.
They chose Parlant because of the control it offers on top of existing models. By moving away from black-box prompting ("prompt and pray") and toward Behavioral Alignment Modeling with journeys, guidelines, and canned responses, the bank was able to ensure their agents follow business protocols as strictly as a tier 1 human service representative would, if not more so.
It’s a big milestone for the team, but more importantly, it's proof of our core thesis: conversational AI is finally ready for the most regulated, high-volume environments in the world.
What does it mean to create an async conversational API where users can send multiple messages in a row, and things just work smoothly, as expected?
In @ParlantIO , when a user sends 2 messages in a row, the first one's processing is cancelled, and the new one starts.
But sometimes you reach a stage of processing where it's not right to cancel anymore. This could be because the response is already out and you want to do some out-of-the-hot-path analysis on what happened. Or because of other edge cases that could arise.
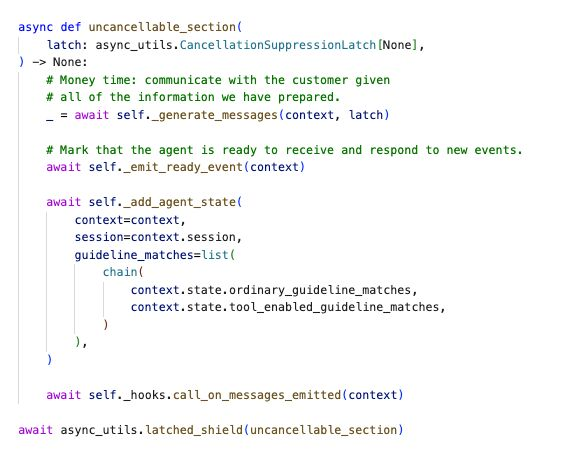
There's a section of Parlant's code designed to prevent cancellation of ongoing-response processing, when the stage of processing is "late" and should no longer be cancellable (else it might result in poor UX, agent stupidity, or even session corruption).
We discovered a critical bug today in this "cancellation prevention" which caused session corruption.
Below you see my fix. A new kind of "cancellation suppression latch" which the engine can utilize whenever it needs to. This is not a simple piece of code, but it works, the API is elegant, it's testable (and tested!), and it was a lot of fun to write.
How the latched shield works:
- It doesn't actually protect your task (unlike asyncio.shield())...
- Until you call latch.enable(), which you can do at any point within the task.
- We enable the cancellation suppression somewhere inside message generation - at some critical juncture.
GPT 6 will end 99.9% of hallucinations and model misalignments.
If you're not one of those who believe that, this webinar might be for you.
We're having a webinar on compliant agentic architecture, where we'll share some of our experience and best practices on how to achieve it.
In the webinar, we'll deep-dive into core architectural patterns for reliability and compliance, along with real-world lessons from enterprise environments.
Save your spot in the first comment
Small language models (SLMs) are definitely the way to go. But what many are missing is that SLMs can't handle *nearly* the diversity and complexity that larger models can.
Our 2 full-time NLP researchers are currently working day and night on getting SLMs aligned with larger models. SFT, RLVR, hybrid approaches - what have you... (P.S. stay tuned for upcoming announcements).
Here's what we've found.
⚠️ Small models fail miserably at broad, fuzzy tasks - especially those with diverse inputs. They do quite well, however, at narrow, specific ones.
➡️ A 14b model can be great at one specific thing: "Tell me whether the following observation is true with respect to the current state of this conversation..."
➡️ A 7b model will need further breakdown - "Given ***this particular category*** of observations that you're trained on, does this observation hold in this conversation?"
➡️ A 3b model will need even more categories.
💡 The lower you go in terms of model size, the more SLMs you need to manage and route between, to replace your LLM setup.
Yet it's so worth it in terms of cost and latencies. If you play your cards right, you can get a 10-20x cost reduction and 2-10x latency improvements.
But here's the key point. What I'm saying here can *only be leveraged* if your agentic architecture lends itself to this type of task decomposition.
In Parlant, for example, we don't have one LLM request doing "aligned conversation" - unlike ~99% of CAI solutions.
We have six specialized categories just for guideline matching, different categories of tool calls, different ways to compose an aligned response message, and a separate stage of selecting a canned response (when they're used).
Each is a narrow task. Each often uses a different model. Most importantly, each can be fine-tuned independently.
Now, suppose your agentic architecture treats the LLM as a magic black box that handles everything (e.g., general "planning" and "responding").
In that case, you won't be able to train SLMs, and you won't enjoy the cost and latency slashes that they can deliver.
So build pedantically, obsessing about the intricacies of each sub-task in your system. If the task is sufficiently well-defined, you'll be able to train an SLM for it. Or stay locked into expensive models for years to come. ☹️
"Context Engineering" 🤖⚙️ is all the rage right now in agentic development. Is it just a fancy new name for prompting, or is there more to it?
In this post, I decided to go fully transparent and talk about what it took for us to create a high-quality implementation that enables developers and business stakeholders to work together on customer-facing agents that can achieve real business impact—and do so safely.
Dive into what production-grade context engineering really looks like in the real world, inside Parlant's guideline matching engine.
- The real challenges that had to be solved
- The naive solutions we tried and failed at
- The real solutions that started working, but didn't scale
- How we optimized them until things fell into place
- The consequent, emerging architecture of a production-grade agentic context-engineering engine
We look at all this as a community effort in getting customer-facing agents under control - we're just part of this community.
Would love to hear your feedback - feel free to DM me for deeper discussions.
https://t.co/VS8AsyXHvU
Here's a "LangChain vs LlamaIndex" comparison. Whose RAG is more accurate?
Guess what?
🔔 Ding-ding! RAG accuracy is not the main issue. Ding-ding again.
We're working with people who deploy agents handling hundreds of thousands to millions of customer interactions per month.
Retrieval accuracy alone doesn't create customer trust or engagement. It's a component. And here's the other component nobody talks about.
If the conversation isn't managed and steered confidently and authoritatively, in a way that creates trust for your customer:
1. They won't trust your answers even if they're accurate
2. They often won't even get to the point where they ask their important questions—not before they escalate the chat to a human rep
If you want great production metrics, sure, go ahead and spend half of your time getting your RAG accurate.
But to make a real difference, spend the other half optimizing domain-specific conversational steering and governance, focused on understanding your customers' needs and interaction patterns.
https://t.co/n1bHyqxX5k
Every LangGraph user I know is making the same mistake!
They all use the popular supervisor pattern to build conversational agents.
The pattern defines a supervisor agent that analyzes incoming queries and routes them to specialized sub-agents. Each sub-agent handles a specific domain (returns, billing, technical support) with its own system prompt.
This works beautifully when there's a clear separation of concerns.
The problem is that it always selects just one route.
For instance, if a customer asks: "I need to return this laptop. Also, what's your warranty on replacements?"
The supervisor routes this to the Returns Agent, which knows returns perfectly but has no idea about warranties.
So it either ignores the warranty question, admits it can't help, or even worse, hallucinates an answer. None of these options are desired.
This gets worse as conversations progress because real users don't think categorically. They mix topics, jump between contexts, and still expect the agent to keep up.
This isn't a bug you can fix since this is fundamentally how router patterns work.
Now, let's see how we can solve this problem.
Instead of routing between Agents, first, define some Guidelines.
Think of Guidelines as modular pieces of instructions like this:
```
agent.create_guideline(
condition="Customer asks about refunds",
action="Check order status first to see if eligible",
tools=[check_order_status],
)
```
Each guideline has two parts:
- Condition: When it gets activated?
- Action: What should the agent do?
Based on the user's query, relevant guidelines are dynamically loaded into the Agent's context.
For instance, when a customer asks about returns AND warranties, both guidelines get loaded into context simultaneously, enabling coherent responses across multiple topics without artificial separation.
This approach is actually implemented in Parlant - a recently trending open-source framework (15k+ stars).
Instead of routing between specialized agents, Parlant uses dynamic guideline matching. At each turn, it evaluates ALL your guidelines and loads only the relevant ones, maintaining coherent flow across different topics.
You can see the full implementation and try it yourself.
That said, LangGraph and Parlant are not competitors.
LangGraph is excellent for workflow automation where you need precise control over execution flow. Parlant is designed for free-form conversation where users don't follow scripts.
The best part? They work together beautifully. LangGraph can handle complex retrieval workflows inside Parlant tools, giving you conversational coherence from Parlant and powerful orchestration from LangGraph.
I have shared the repo in the replies!
After recent calls with large-scale users of Parlant (and some new leads who are exploring it after experiencing issues in their customer-facing agents), so much of that comes down to the Supervisor Pattern... This is why I'm writing about it so much.
But recently, an idea for a new agent architecture came up that shows a lot of promise.
The initial problem is this: when you genuinely have complex, distinct departments in your AI support system, trying to cram everything into one omni-agent becomes unmanageable. It pretends to be one agent while fragmenting the conversation and mixing up contexts.
Don't get me wrong... An omni-agent is a really cool moonshot concept. But it (unfortunately) fails due to hard technical limitations.
But there's another option: Just build it like real customer service.
You call support. A receptionist briefly clarifies what you need, then routes you *once* to the right department. Then an expert in that department handles your *entire* conversation.
I call it the "Receptionist Pattern" and it's how agentic architectures *should* handle complex support use cases.
The great thing about it is that it's so based on reality that:
1. Customers already understand it, so there's a natural alignment of expectation vs reality in their usage patterns. The friction is minimal.
2. Operators/developers already understand it, which makes it so much easier to model agentic flows (and even development teams) around it.
- Simple routing at the entry point (not mid-conversation)
- Each department is a separate expert agent with full context (using department-specific dynamic context assembly)
- One coherent conversation per department
- If you need a different department, you need an explicit transfer (just like real service)
The alignment between expectation (which is based on existing habits) and reality (your product's UX) is what makes your AI feel natural and usable.
Not the sci-fi features. Not sub-second latencies. Just providing better, quicker, and more manageable customer service.
@BenBoarer@icookandcode@ollama@BenBoarer not blaming you for being skeptic. Here's a blog post @ymarcov recently wrote that will help you understand how Parlant keeps agents compliant - https://t.co/Y0s3G1O6xt
I stumbled across the open-source project @EmcieCo last month.
It’s basically a framework for building AI agents, but with a major improvement: instead of adding prompts into a giant system message, you just model agent behavior.
Their core technology appears to be based on a research paper called Attentive Reasoning Queries (ARQs), which achieves significantly better performance compared to a chain of thought.
I tried setting up a simple support agent, added a few guidelines, and for once, it followed them consistently.
What struck me most is how predictable it feels. That shouldn’t be surprising, but in this space it is.
Most frameworks either force users through brittle flowcharts or let the LLM run wild, hoping for the best.
Not saying it solves every problem, but if you’ve wrestled with flaky AI agents, this is worth a look. Looks quite promising to me.
Worth a look if you’re dealing with similar headaches.
👉 https://t.co/3azePKzdDJ
I’ve been curious about AI chat agents for quite some time, watching the space evolve and wondering how far the tools have come.
When I saw the latest release of Parlant https://t.co/Cx6Rdo0pkh, I finally decided to give it a try.
What made it so exciting for me? Thread 🧵

















![ymarcov's tweet photo. 🚀 Launching Parlant 3.1
[TLDR Speed, Accuracy, & Control]
@ParlantIO has seen incredible adoption in the past few months.
It's live in production with a few large financial institutions, and it also helps many small-to-medium businesses in use cases from healthcare, through legal, all the way to education and - get this - live troubleshooting of wind turbines.
There are more use cases that our open-source Conversational AI framework seems to excel at than we first had in mind.
Today - I'm excited to launch Parlant 3.1!
Since releasing 3.0 a few months back, we've listened to our community and collected an enormous amount of feedback and feature requests.
The additional feature list in this version is extraordinary. In terms of the experience, expect improvements in speed, accuracy, and — the real keyword of this release — CONTROL.
We've added multiple new control mechanisms in this new version that leverage and really show the power of Parlant's granular behavior control philosophy.
Be sure to check out the expanded announcement in the first comment.](https://pbs.twimg.com/media/G953h9pW0AA8KTN.png)






















