Hey dinos 🦖 we’ve been cooking up something new in your library…
Now you can:
1. Quickly align any two sequences from your history or uploads
2. Search across everything you've sequenced with us
We'd love a few of you to try early access & help build this. Reply if you're in!
Hey dinos 🦖 we’ve been cooking up something new in your library…
Now you can:
1. Quickly align any two sequences from your history or uploads
2. Search across everything you've sequenced with us
We'd love a few of you to try early access & help build this. Reply if you're in!
🌎👩🔬 For 15+ years biology has accumulated petabytes (million gigabytes) of🧬DNA sequencing data🧬 from the far reaches of our planet.🦠🍄🌵
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
https://t.co/dDBtAjfdYL
@dr_alphalyrae Getting that initial "good" data on a novel hypothesis is what kicks off discovery, so someone that is better at that will have a higher likelihood of discovery.
@dr_alphalyrae Good lab hands means understanding the details of the process, including which parts are crucial to get exactly right vs which ones can tolerate some level of variance. Getting the balance right is what allows generating the necessary amount of "good" data.
We’re working hard to accelerate your research!
You can now view the predicted amino acid sequence of each coding region and per-base quality scores directly on your results page, giving you clearer insight into your sequence results at every position.
How can sequencing reveal how viruses spread through hospitals? 🦠
Join CHOP’s Dr. Robert Potter as he shares how he uses Plasmidsaurus long-read sequencing to investigate norovirus transmission within hospitals.
🗓️ Sept 5th, 10am PT
👉 Register: https://t.co/39E5SYYHCn
Interested in joining our growing interdisciplinary team studying viruses, RNA, and condensates? Looking for a postdoctoral position? Please consider joining us in Cambridge, UK, or drop us a line to discuss these opportunities: https://t.co/Vs4TBcx5O5
🧬Excited to share our new preprint! DMS chemical mapping, a key technique for studying RNA structure. It is assumed that low DMS reactivity=WC, high=non-WC. However, analyzing 7,500 RNA structures containing known 3D structures reveals it's not simple. https://t.co/qjjOSCRiz9
Congratulations to PoL postdoc Lukáš Pekárek @LukasPekarek1 from the Jahnel group @jjmajahn for being awarded the prestigious Peter and Traudl Engelhorn Scholarship! Lukáš researches long RNA structure and their changes during phase separation.
Read more: https://t.co/5mMUPPUmgG
Interested in multiplexing samples for nanopore dRNA sequencing with the new chemistry? Check out our newly released RNA4 model!
4 barcode model available here:
https://t.co/ol3Hfxclke
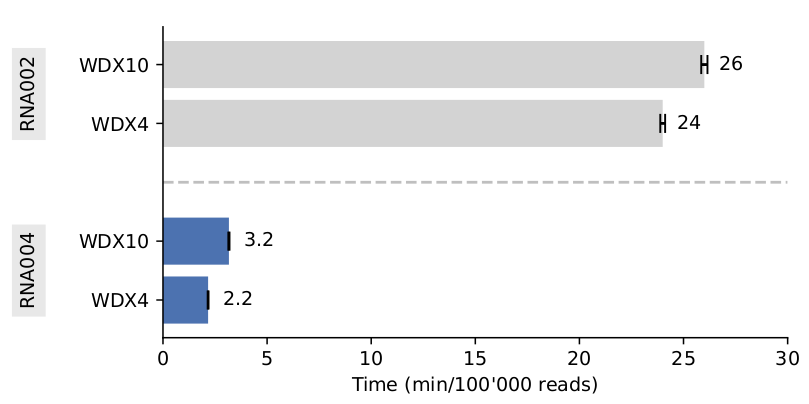
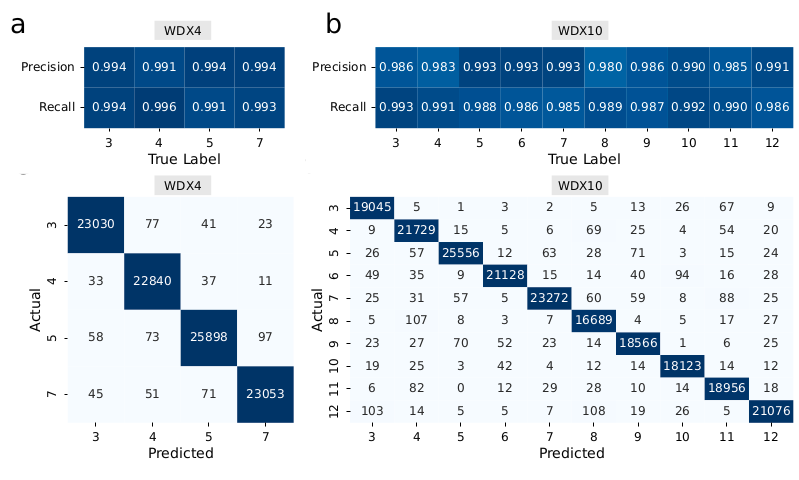
1/6 🎉 Excited to announce WarpDemuX v0.4.4 with RNA004 support! Our (@PatrickBohnPB ) WDX4 model achieves 99.5% target accuracy with 95% yield on the latest RNA sequencing kit from @nanopore. Release notes at: https://t.co/SiLrGdg2Yh
VERY excited to share SeqTagger with the world! If you want to learn more about our super-fast and accurate demultiplexing tool for direct RNA-sequencing (DRS), check out the thread below. https://t.co/eJFT76dwwI (1/15) 🧵
Very excited to announce our preprint on adapting the @nanopore Cas9 workflow for R10 flow cells. This is work from the amazing Veronika Scholz and Veronika Schoenrock and team @MGZMuenchen, and is also my very first senior author paper 🧵https://t.co/6PU8VaZUqs
@gringene_bio@razoralign@EvaMariaNovoa The code of SeqTagger isn't public yet, but it looks like it works very similar to WarpDemuX in that it detects the rising edge of the poly(A) signal as the end of the adapter.
Nano-tRNA signals still have a short (10 nt) poly(A) tail, which is enough for WDX to work too.
@salonium As you've highlighted there are some reasons to be skeptic about this data (especially the apparent duplication of Liver '16 in A and B).
However, as it is plotted on a log scale, the lengths of the standard deviation lines are not directly comparable.