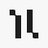⚡️ My PhD thesis is on arXiv! ⚡️
To quote my examiners it is "the textbook of neural differential equations" - across ordinary/controlled/stochastic diffeqs.
w/ unpublished material:
- generalised adjoint methods
- symbolic regression
- + more!
https://t.co/Pm5l6FhEED
v🧵 1/n
Introducing Strong Stochastic Flow Maps
TLDR: Stochastic Flow Maps where we learn the stochastic solution path.
Work led by Sam McCallum, @zwblasingame, with Timothy Herschelll, @AlexanderTong7, and @JamesFosterBath
Arxiv: https://t.co/Hy8WWZOnjE
Code: https://t.co/PMe6RoqyZA
Alright chaps, I am in Boston for PEGS, here to chat all things AI + antibody engineering. Send me a message if you're around! 🧬
(PS I'm hiring! Pharma x AI startup, come make drugs with us.)
@DdelAlamo +100 to this.
Every now and again I get pitched by someone looking to e.g. package RNAseq data and sell to pharma. This kind of stuff is... not very useful.
I'd much rather have a way to efficiently run targeted experiments (e.g. 96-well plate) than 10^n screening experiments.
Yeah. :( Our instincts are the same, but again, almost no-one else in biotech approaches things this way.
Some options we're thinking about:
1) bet on oneself – we'll be faster – release anyway!
2) release but with e.g. just a 1 year delay;
3) wait until later (patent, ...) but include all kinds of interesting intermediate details then;
4) ...just acknowledge that we're doing something unusual and that there aren't that many folks who'd really benefit from the data anyway.
FWIW techbio is coming from a totally different culture + change is being driven by drug timelines compressing across the industry. I might just be hopelessly naive, but I think things have the possibility to improve here. :)
We're growing the AI team at @ManifoldBio, starting with a role to train protein foundation models on our proprietary data.
I believe Manifold is the most interesting place to work on protein design. We're designing and testing millions of binders per month, including in vivo, and accelerating. No one else has data like this.
If you have deep experience pretraining or fine-tuning protein models and want to work somewhere the data actually lets you push beyond what public datasets can enable, please reach out.
Who's the most talented software engineer you know that should stop building SaaS products and instead join a company that builds in the physical world?
Refer them to me and get a 2000 USD referral bonus if we end up hiring them!
🚀 Exponax v0.2.0 — fast & differentiable PDE solvers in JAX
New: 3D Navier-Stokes on a single GPU, wave equation stepper, improved dealiasing & memory efficiency
4096² / 256³ on 24GB consumer GPUs
10k² / 512³ on A100/H100
📦 pip install exponax
https://t.co/aGWn08lZ6E
So I have mixed feelings about IsoDDE. It's an AF4, it's much better on hard problems, and I don't want to understate their technical achievement.
But also, it's been five years since founding, and success is measured in drugs, not models. Where are the drugs? 1/
Today we share a technical report demonstrating how our drug design engine achieves a step-change in accuracy for predicting biomolecular structures, more than doubling the performance of AlphaFold 3 on key benchmarks and unlocking rational drug design even for examples it has never seen before.
Head to the comments to read our blog.
@BiomedErs For a phase 1 then 5 years should now be pretty easy, at least in antibodies. For a famous reference then see China doing it in way less than that; the west is also still doing pretty well here.
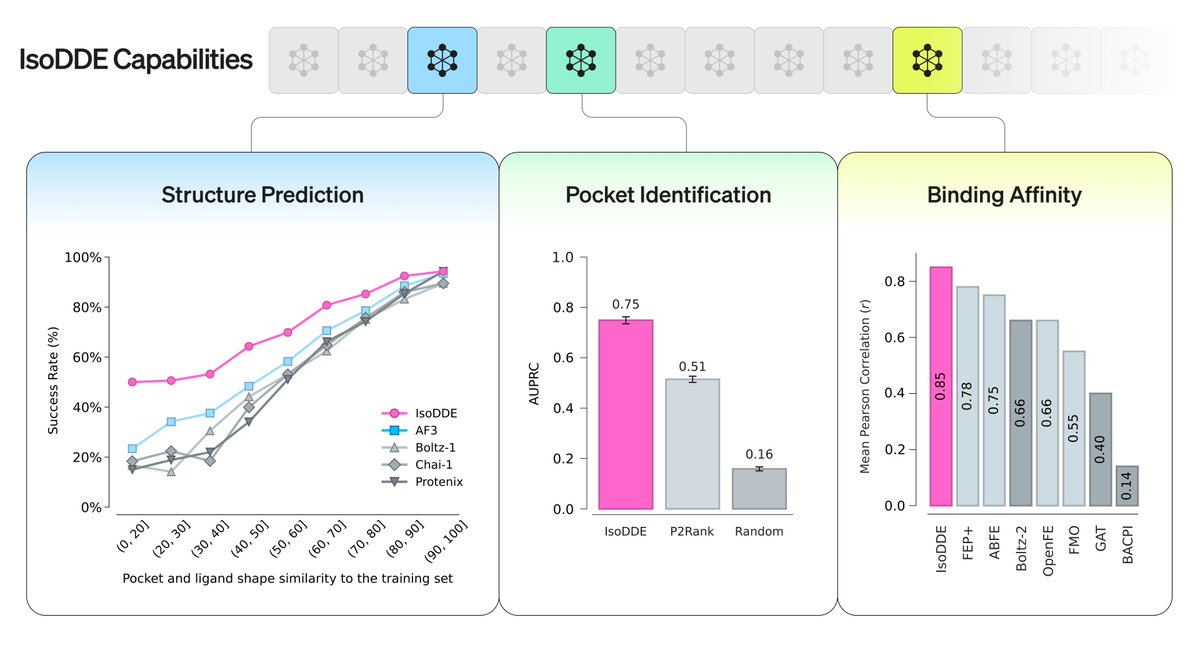
We're launching a Protein Design Skills marketplace for Claude Code!
We received a lot of questions about the protein design agent, so we're releasing the skills we used in the demo. The first batch includes skills for design generation, experimental testing, pipeline orchestration and more. The marketplace is open to community contributions too, so you can build and submit your own skills for others to use
Install with
/plugin marketplace add adaptyvbio/protein-design-skills
and check out the full list here: https://t.co/zS2dV2mrG9
Big news from Boltz today: we’re launching Boltz Lab, a new platform with new small-molecule + protein design agents, announcing Boltz PBC and a $28M seed round, and sharing a multi-year partnership with Pfizer. More below! 🚀
@owl_posting@leashbio The 'Money Stuff'-style introduction was excellent, I'm a big fan. (Though I don't know if that was an explicit inspiration or not!)
@owl_posting Huge +1 from me in favour of the podcast format.
- Stronger guarantee for the reader that the piece is technically accurate.
- It's great market research to know the in-depth view of a particular company / research groups.
Interesting post from @owl_posting asking whats next for antibody design. I agree with him that in vivo properties are likely the answer, but the question is how do we get there?
The PDB has enabled de novo binding models to be incredibly successful. Properties like developability likely are implicit in the models, given the data they are trained on is well formed antibody crystal structures. Fwiw at @ManifoldBio using our open source mBER de novo design approach, we also see very similar affinity/developability properties for our molecules, when we get around to it we might update the preprint to reflect this. Of course you are welcome to try out mBER as it is open source: https://t.co/VsOyzgXXOT
Back to in vivo properties, the challenge here is that unlike the PDB, we don't have an accurate and high throughput dataset for antibodies in terms of PK/PD or ADAs etc. Using standard methods, these traits are quite hard to measure in high throughput, which make learning them very challenging. And arguably, these properties are more important than binding for making a successful drug.
These properties are complex, essentially you are asking "I have a binder that I know binds a target of interest in vitro: but does it get to the right place, bind the right target (and not the 20k other possibilities in the body), last long enough to enact its function (i.e. PK) and then perform the function on the target (inhib, activate etc) in a highly complex living system that is nothing like the petri dish that the molecule likely was initially tested in before?"
To some extent, binding has been a solved problem for quite a while. If you talk to folks like Dane Wittrup (inventor of yeast display, founder of Adimab), he will tell you that using yeast display Adimab can design binders to specific epitopes / gpcrs, whatever you want. They will bind with high affinity and specificity in vitro. These new de novo methods indeed speed this process up by a couple months, but fundamentally the really question is still, does your molecule work in a living system, and have you optimized for all the properties (PK,PD, ADA) that will enable clinical success.
This is exactly what why we built @ManifoldBio. We saw the need for high throughput in vivo data to unlock the real power of AI. AI / de novo design are only as good as the data they are trained on, without in vivo data, we will never learn in vivo properties! So we built a measurement engine to solve that.
We have generated PK data on over 12,000 molecules to over 100 targets of interest to date. We have generated in vivo tissue enrichment data on half a million molecules to almost a thousand targets. This is the data we believe will unlock the true promise of AI. Lot's of folks talking about virtual cells, but perhaps we should start thinking about virtual organisms. Even if you had a virtual PK model, this would be a huge benefit to drug discovery. In fact, we already are building such a model, more details soon :)