Excited to share code & models for FastVLM — our blazing-fast Vision-Language Model appearing at #CVPR2025
Run it on-device with inference code optimized for Apple Silicon using #mlx.
Code: https://t.co/zrYytwr9N1
Updated paper & results coming soon. Stay tuned! 👀
(1/n) There’s a long-running debate on bringing representation learning into generative modeling—their latent spaces play different roles.
🚀🚀 We present FAE, a simple-yet-effective framework that bridges them with a single attention layer!
Paper: https://t.co/p8eLoGwDBk
We use latent continuous thoughts for retrieval optimized via downstream NTP loss, unified under one LLM backbone. Since representations are shared, documents can be precomputed—eliminating 2-stage RAG. We match raw text performance but with a much shorter context budget. 📉🚀
STARFlow gets an upgrade—it now works on videos🎥
We present STARFlow-V: End-to-End Video Generative Modeling with Normalizing Flows, a invertible, causal video generator built on autoregressive flows!
📄 Paper https://t.co/NIMAUlpuNw
💻 Code https://t.co/3sgI5dfD3W
(1/10)
SSMs promised efficient language modeling for long context, but so far seem to underperform compared to Transformers in many settings. Our new work suggests that this is not a problem with SSMs, but with how we are currently using them.
Arxiv: https://t.co/bCzxawF452
🧵
🚨While booking your travel for #NeurIPS2025, make sure to stay on Sunday, December 7 8am-5pm for CCFM Workshop (Continual and Compatible Foundation Model Updates). We have received exciting paper contributions and have an amazing lineup of speakers.
🤔 Ever thought a small teacher could train a student 6× larger that sets new SOTA in training efficiency and frozen evaluation performance for video representation learning?
🤔 Do we really need complex EMA-based self-distillation to prevent collapse, bringing unstable loss dynamics while offering little insight into representation quality?
🚨 In our new paper, we investigate these questions and propose SALT (Static-teacher Asymmetric Latent Training): a simple, scalable, and compute-efficient alternative for video representation learning.
📄 Rethinking JEPA: Compute-Efficient Video SSL with Frozen Teachers
🔗 https://t.co/C9amVFddSH
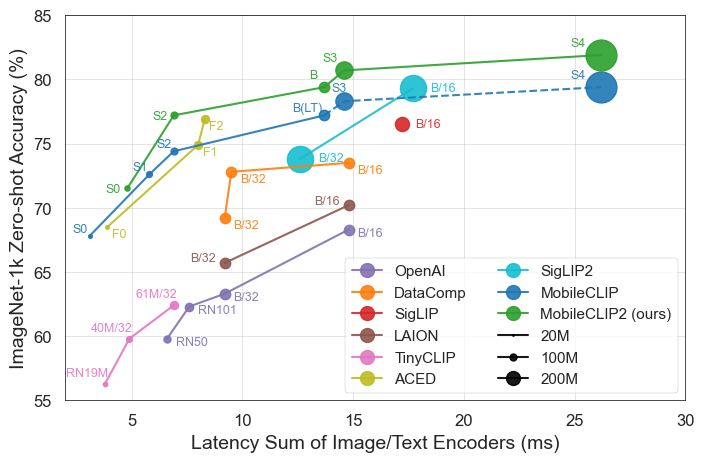
NEW: Apple releases FastVLM and MobileCLIP2 on Hugging Face! 🤗
The models are up to 85x faster and 3.4x smaller than previous work, enabling real-time VLM applications! 🤯
It can even do live video captioning 100% locally in your browser (zero install). Huge for accessibility!
📢 Releasing MobileCLIP2 (TMLR Featured). Small embedding models that can power your multimodal RAG applications on resource constrained devices.
Models are available on 🤗
🚨📅The submission deadline for #NeurIPS 2025 CCFM Workshop is just 8 days away on August 22. Get your papers in!
Submit your work on Continual and Compatible Foundation Model Updates to the #NeurIPS 2025 CCFM Workshop.
Learn more: https://t.co/oIrrtiRKD6
Introducing DINOv3 🦕🦕🦕
A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale.
High quality dense features, combining unprecedented semantic and geometric scene understanding.
Three reasons why this matters…
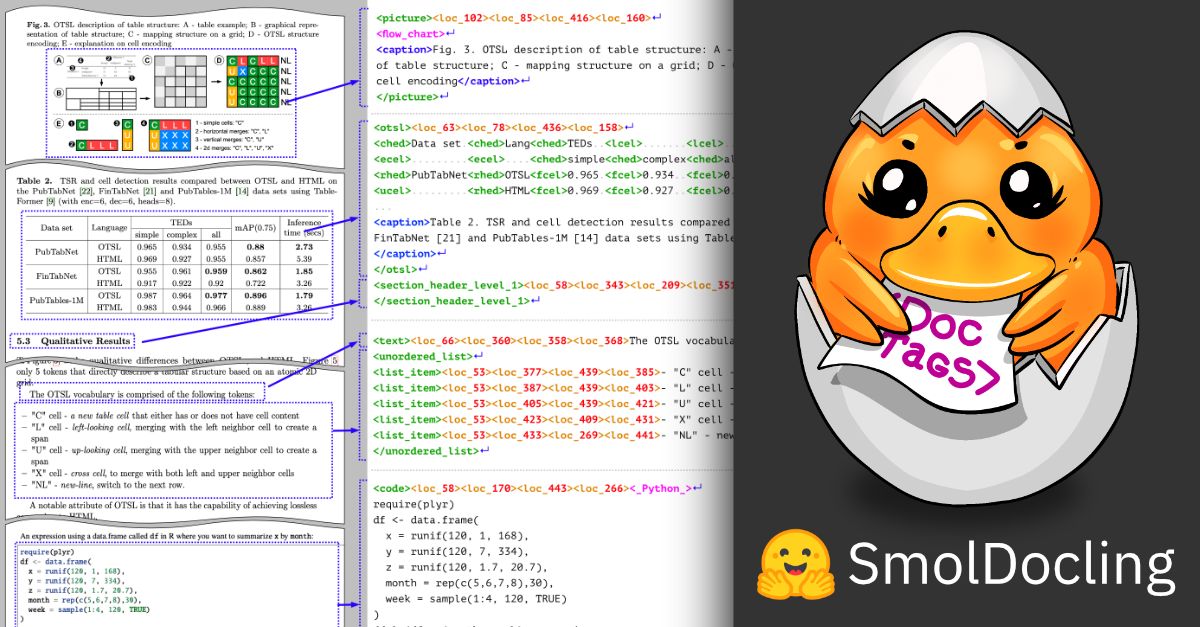
🚀 We're thrilled to launch four new OCR datasets with 20M images: DoclingMatix, SynthFormulaNet, SynthCodeNet, and SynthChartNet. We used them train SmolDocling, our ultra‑compact (256M) full-page document conversion VLM with performance rivaling models up to 27× larger.
Uncertainty quantification (UQ) is key for safe, reliable LLMs... but are we evaluating it correctly?
🚨 Our ACL2025 paper finds a hidden flaw: if both UQ methods and correctness metrics are biased by the same factor (e.g., response length), evaluations get systematically skewed
📢Submissions are now open for #NeurIPS2025 CCFM workshop.
Submission deadline: August 22, 2025, AoE.
Website: https://t.co/oIrrtiRKD6
Call for papers: https://t.co/9sUoMl7AJg
Submission Link: https://t.co/2aXHQaqFDf
We propose new scaling laws that predict the optimal data mixture, for pretraining LLMs, native multimodal models and large vision encoders !
Only running small-scale experiments is needed, and we can then extrapolate to large-scale ones. These laws allow 1/n 🧵
📣 We are excited to present our work on inferring user preferences from writing samples at @icmlconf Poster Session 3 (Wed. 11:00AM - 1:30PM)!
Come by to ✋ chat with us, 📄 learn about our method, and 💻 hear about our new interactive benchmark (🔗s below)!
🚀Super excited to share TiC-LM (Oral at #ACL2025)!
How to keep FMs up-to-date over months/years? We have a benchmark and lots of insights (https://t.co/Dm4n4xT0Ul).
Also organizing a related @NeurIPSConf 2025 workshop continual and compatible FMs (CCFM: https://t.co/Dly5OXTfOc)
Code/Models/Dataset: https://t.co/B2nJ8LSIrX
Our prior work on TiC-CLIP: https://t.co/QkOGeqHtWS
Thanks to @jeffwpli for his amazing work on DCLM and TiC-LM and other upcoming works during his internship at @Apple MLR. Thanks to everyone at @Apple MLR to help us do great research.
I will be attending #CVPR2025 and presenting our latest research at Apple MLR! Specifically, I will present our highlight poster--world consistent video diffusion (https://t.co/ms3o8L1R9B), and three workshop invited talks which includes our recent preprint ★STARFlow★! (0/n)
Imitation learning has a data scarcity problem.
Introducing EgoDex from Apple, the largest and most diverse dataset of dexterous human manipulation to date — 829 hours of egocentric video + paired 3D hand poses across 194 tasks.
Now on arxiv: https://t.co/bJBPER8GTC (1/4)