If the price went from $100 to $600, the increase was $500, and $500 ÷ $100 = 5, which equals 500%.
and if the price decreases...
The decrease percentage is 83.33%
The price dropped by $500 ($600-$100), and $500 ÷ $600 = 0.8333, which is 83.33%.
Ladies and gentlemen, the United States.
RK JR: One of the Democrats was ridiculing President Trump for his math, and she was saying it's in mathematically impossible to have any drug drop by 600% cost. And I said, well, if the drug was $100 and it raised the price of $600. That would be a 600% rise. If it drops from 600 to 100, that's a 600% savings.
Trump: That’s right.
RFK JR: The president used that mathematical device to illustrate the magnitude of the theft.
The Arbitrum Security Council has taken emergency action to freeze the 30,766 ETH being held in the address on Arbitrum One that is connected to the KelpDAO exploit. The Security Council acted with input from law enforcement as to the exploiter’s identity, and, at all times, weighed its commitment to the security and integrity of the Arbitrum community without impacting any Arbitrum users or applications.
After significant technical diligence and deliberation, the Security Council identified and executed a technical approach to move funds to safety without affecting any other chain state or Arbitrum users.
As of April 20 11:26pm ET the funds have been successfully transferred to an intermediary frozen wallet. They are no longer accessible to the address that originally held the funds, and can only be moved by further action by Arbitrum governance, which will be coordinated with relevant parties.
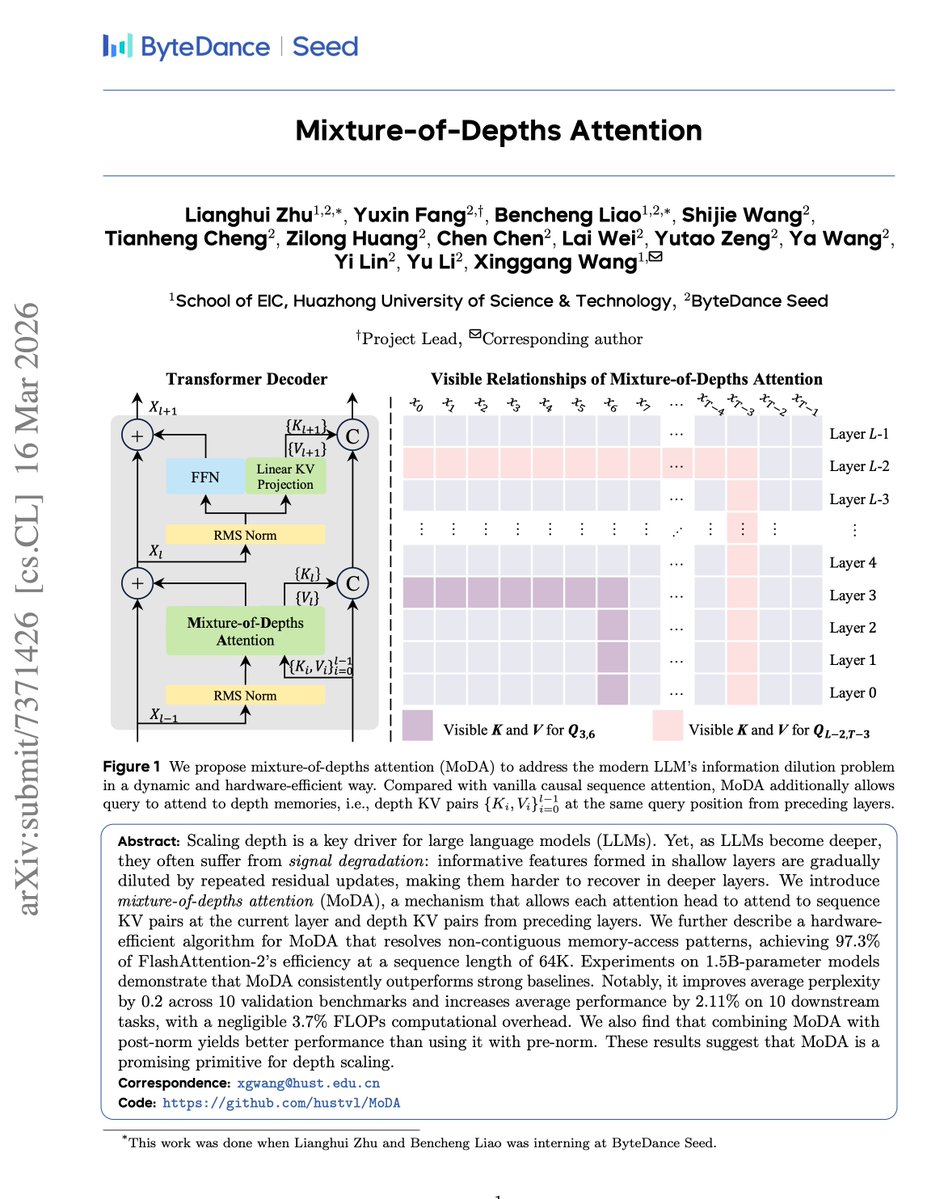
For a decade, we’ve scaled models wider and deeper like crazy, but inter-layer communication? Still stuck on ResNet’s x + F(x) from 2015.
Layers get deeper on paper, but early signals get diluted in the residual soup. Many just… stay silent. The bottleneck isn’t inside layers anymore. It’s how they talk to each other.
Time to upgrade the staircase.
Enter the “second half” of model architecture.
Instead of accumulation (better blending, more channels, adaptive weights), the new paper flips it to retrieval: “What do I need right now?” meets “What do I have from history?”
No more straining to hear layer 3 from layer 152 in a noisy chorus. Just direct access.
They solve the speed problem with Flash Depth Attention (FDA), a hardware-efficient kernel that makes full depth retrieval >40,000× faster (naive version was painfully slow).
Then they go nuclear with Mixture-of-Depths Attention (MoDA): one unified softmax where each head jointly attends to:
• Current layer’s sequence KV (the usual horizontal attention)
• Depth KV from all preceding layers (the new vertical dimension)
Completely rewires the Transformer block: depth att → sequence att → depth att → FFN.
Models now actively pull exactly the features they need across depth. Attention sinks disappear. Shallow syntax + deep semantics? Finally reachable without dilution.
On 1.5B models (vs strong OLMo2 baseline):
• Avg perplexity ↓ 0.2 across 10 benchmarks
• Downstream tasks ↑ 2.11% on 10 evals
• Just 3.7% extra FLOPs
Bonus: works better with post-norm.
Paper calls it a “promising primitive for depth scaling.” I call it the moment we stop treating depth like a one-way blur and start treating it like an addressable dimension.
This feels like when attention replaced recurrence for sequences. Now for depth.
📄 Paper (arXiv 2603.15619): https://t.co/LDKkrJuZRY
✍️ Blog (highly recommend): https://t.co/gVvAK69hv8
💻 Code + FDA kernel: https://t.co/woHcN5BtHz
For a decade, we've made models wider and deeper—but we've barely changed how layers *talk* to each other.
Since ResNet's `x + F(x)` in 2015, the depth residual has been the only highway for inter-layer communication.
It's time to upgrade the staircase. 🧵
Satoshi straight up had clairvoyance in 2009.
One brilliant little tweak to the script and he baked quantum resistant armor into Bitcoin from day one, protecting our digital gold against threats we hadn’t even imagined yet… no soft fork needed.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
The serious question is no longer "does quantum matter for crypto?"
It is:
If your system had to stop trusting elliptic-curve signatures sooner than expected, what is the migration plan?
That is the question worth answering now.
Quantum won’t need to kill blockchain.
It only needs to break the keys.
That’s the mistake too many people still make when they talk about "quantum risk in crypto"
The real threat is not that a quantum computer magically deletes chains.
It’s that a sufficiently capable machine could break the signature schemes that prove ownership.
And for much of crypto, that is the whole game.
A few hard truths:
The hardest part is not choosing a post-quantum algorithm.
The hardest part is migration:
• wallet support
• client updates
• custody systems
• contract upgrade paths
• recovery logic
• user coordination
This is a systems redesign problem.
The @DriftProtocol exploit is a reminder that crypto rarely breaks where the marketing says it’s strong.
It breaks where operations, signers, coordination, and trust are weak.
"Decentralized" does not mean safe.
A lot of the time, it just means the failure mode moved.