We’ve just released a white paper describing all the tools WordStat offers to support taxonomy building and content dictionary creation, refinement, and validation. You can get the PDF version at https://t.co/DISQVfoyhE or the web version here: https://t.co/3ZtEyVZdlm
#GenAI can help speed up coding open-ended responses, but judgment still matters. See how we balance automation with human review in #QDAMiner new AI coding feature: https://t.co/A9cOjshS0j. See all GenAI features here: https://t.co/VSkfeBy4ji
Think "zero data retention" & "data encryption" guarantee your privacy? Think again. Our latest blog looks at misleading claims giving a false sense of data security when analyzing qualitative data with #GenAI .
https://t.co/YB8ca6eWLo
We just released updates for WordStat 2025.0.5 (including WordStat for Stata) and QDA Miner 2025.0.3. We added the new OpenAI GPT 4.1 and Claude 4.0 models, as well as the Mistral medium model. Includes new scripts for text extraction, summarization, and translation.
Tricks, biases, and inaccuracies of sentiment analysis in qualitative software? Comparing three #CAQDAS tools: #NVivo, #Atlasti, #MaxQDA, and #WordStat. See full analysis at https://t.co/wWFA04eatX. Do you really think it is different elsewhere?
Analyzing large datasets with qualitative analysis software? Is it a good idea? Comparing scalability and processing speed of four #CAQDAS tools: #NVivo, #Atlasti, #MaxQDA, and #QDAMiner. See full analysis at https://t.co/qVEcpRpswO
WORKSHOP: "Harnessing QDA Miner and WordStat for Text Analysis" his is a one-day workshop aimed at equipping researchers with the skills to effectively use QDA Miner and WordStat in their research. Led by Christina Silver, an expert in the field.
https://t.co/KiLYBSGBYr
#BDAIP23 jour 2. Stand B30, Provalis Research présente ses outils pour analyser et visualiser le texte non-structuré, extraire les informations de retours d'expérience, CV, réseaux sociaux, brevêts, articles scientifiques, etc. Outil NLP et #TextMining avec un #TopicModel, etc.
A ne pas manquer, ce midi au #BDAIP23, présentation sur l'I.A. en analyse de texte. Quand les LLM (#BERT et ##ChatGPT) sous-performent face à des techniques statistiques du 19e siècle et début 20e. Salon 5.
Au poste pour répondre aux questions des participants du #BigDataAIParis et présenter nos outils d'analyse de données textuelles ("topic modeling", "rule-based categorization", ML supervisé et non-supervisé, et plein de visualisations.
Bonjour, viens nous voir au Stand B30. Nous sommens u société spécialisée dans le développement de logiciels d'analyse sémantique. Venez nous voir pour obtenir un à une démo personnalisée, en direct.
Lundi, nous serons là, promis😀#BigDataparis
Présentation d'une situation où les LLM (BERT et ChatGPT) et le deep learning ne performent pas très bien. Quelques pistes d'explication. #BigDataAIParis
Nous aimerions vous convier à notre atelier qui se tiendra le 25 Sept à 12:00 PM, salle 5. Lors de cette session, nous plongerons profondément dans le thème intrigant des "Bonnes et Mauvaises Applications de l’IA à l’Analyse Texte : Raisons et Recommandations". #BigDataparis
Nous aimerions vous convier à notre atelier qui se tiendra le 25 Sept à 12:00 PM, salle 5. Lors de cette session, nous plongerons profondément dans le thème intrigant des "Bonnes et Mauvaises Applications de l’IA à l’Analyse Texte : Raisons et Recommandations". #BigDataparis
Nous aimerions vous convier à notre atelier qui se tiendra le 25 Sept à 12:00 PM, salle 5. Lors de cette session, nous plongerons profondément dans le thème intrigant des "Bonnes et Mauvaises Applications de l’IA à l’Analyse Texte : Raisons et Recommandations". #BigDataparis
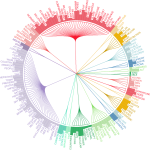
Didn’t get a chance to see us at booth 744. There is still time, drop by we will show you what this graph means and how you can use text analytics. If not contact us [email protected] book a demo. We’ll show you this, many more. @bigData_LDN