i am eternally frustrated by my inability to simply be better. my discipline to improve remains fulfilling, yet undeniably inadequate as my insatiable wants forever loom with contempt
super simple way to solve linear systems of equations:
start with a set of linear equations. for this example the following will do
3x + y = 5
y + z = 4
x - y + 2z = 8
convert each equation to a homogeneous vector representation
3x + y = 5 --> 3x + y - 5w
y + z = 4 --> y + z - 4w
x - y + 2z = 8 --> x - y + 2z - 8w
next, we need the exterior product. the exterior product is pretty easy once you get the hang of it. you write it like a ∧ b. there are just a few basic rules of the wedge we need.
1. a basis vector wedged with itself is zero. x ∧ x = 0.
2. you can flip the operands if you negate. x ∧ y = - y ∧ x. 3. it distributes over addition. a ∧ (b + c) = a ∧ b + a ∧ c. 4. scalars factor out. x ∧ 4 y = 4 (x ∧ y).
these are all the properties we will need. continuing from earlier, join all of our equations using the wedge product.
(3x + y -5w) ∧ (y + z - 4w) ∧ (x - y + 2z - 8w)
now reduce using the rules of the wedge product + the normal rules of a vector space. this part is tedious, so i'll just show off the first multiplication
(3x + y -5w) ∧ (y + z - 4w)
=
3x∧y + 3x∧z - 12x∧w
+ y∧y + y∧z - 4y∧w
- 5w∧y - 5w∧z + 20w∧w
y∧y and w∧w turn in to zero. and we can swap some of the wedge products, adding in minus signs, so that we can group terms together. after all this we end up with
3x∧y + 3x∧z - 12x∧w + y∧z + y∧w + 5z∧w
once we wedge this term with the remaining term, x - y + 2z - 8w, and simplify (left as an exercise for the reader), we get the following
10x∧y∧z - 35 x∧y∧w + 5x∧z∧w - 15y∧z∧w
the final thing we need to calculate for this expression is the dual. the dual is traditionally written like ⋆v. the dual of a wedge product v is another wedge product w, such that v∧w equals the wedge of all of our basis vectors in ascending order. in our case this is x∧y∧z∧w.
to find the dual of a particular wedge product, say z∧x, we can solve this equation using the swapping rule for the wedge
z∧x∧⋆(z∧x) = x∧y∧z∧w
z∧x∧⋆(z∧x)= -x∧z∧y∧w
z∧x∧⋆(z∧x)= z∧x∧y∧w
x∧⋆(z∧x)= x∧y∧w
⋆(z∧x)= y∧w
the dual also distributes over addition. if we compute the dual for the term
⋆(10x∧y∧z - 35 x∧y∧z + 5x∧y∧w - 15y∧z∧w)
we get the result
-10w - 35z - 5y - 15x
or in a more familiar order
-15x - 5y - 35z - 10w
final step, we homogenize. make it so the coefficient in front of the w is 1. to do this we divide the whole term by the coefficient in front of the w, -10, and are left with
3/2x + 1/2y + 7/2z + w
reading off the x, y, and z coefficients of the result we get the solution to the linear system.
to summarize: take your linear system. put it in homogeneous coordinates. wedge those vectors together. reduce them using the rules of vector and wedge arithmetic. take the dual. homogenize. read off the values.
-------------------------------
i like this approach cuz it is so simple and algebraic. just the normal rules for vector arithmetic, plus the fairly minor addition of the wedge product (which has a lot of uses elsewhere! it is worth learning!), are enough to solve linear systems of equations.
i kind of wish this is how i had learned linear algebra in school. gaussian elimination is fine, but i feel like it requires too much creativity. i don't wanna think about which rows to mash together. i wanna just rewrite over and over and over again.
btw this approach fails in predictable ways if the system is under or over constrained. i think. if several constraints are linearly dependent, when they all get wedged together they wedge to 0. and 0 wedged with anything else is 0. so the whole system becomes 0. this is one condition that can be checked. the other is when the system is inconsistent, like you have x = 2 and x = 4 as equations. in this case it appears that the coefficient of the homogeneous coordinate, w, becomes zero. this prevents us from homogenizing the system back to normal cuz you cant divide by zero.
i don't totally know for sure that this is how things work, that's just what ive seen messing around with a lil toy implementation. don't got formal proofs to the effect.
-------------------------------
i think there is some kind of good geometric intuition hiding under the hood here somewhere. linear equations are like hyperplanes or something, and the wedge product is a well known way to intersect geometric objects. the way the homogeneous coordinate behaves is basically how it works in projective geometry too. when the homogeneous coordinate is zero, this is algebraically the same condition as a "point at infinity" in projective geometry. somehow the idea that infinity ties to the impossibility of satisfying a linear system, idk that seems right.
-------------------------------
i don't have anything for a final section idk why i added another section delimiter
-------------------------------
alright here is an attempt at a conclusion. linear systems of equations show up all over the place. they are so basic and solvers are so ubiquitous that it is easy to avoid thinking about the fundamentals. especially when the fundamentals are kind of awkward to deal with.
i think it is pretty neat that there is such a mechanical, brainless way to solve these systems of equations. now if you are stuck on a deserted island and you forget how to invert a matrix, you can rest easy knowing how to use the wedge product as your backup.
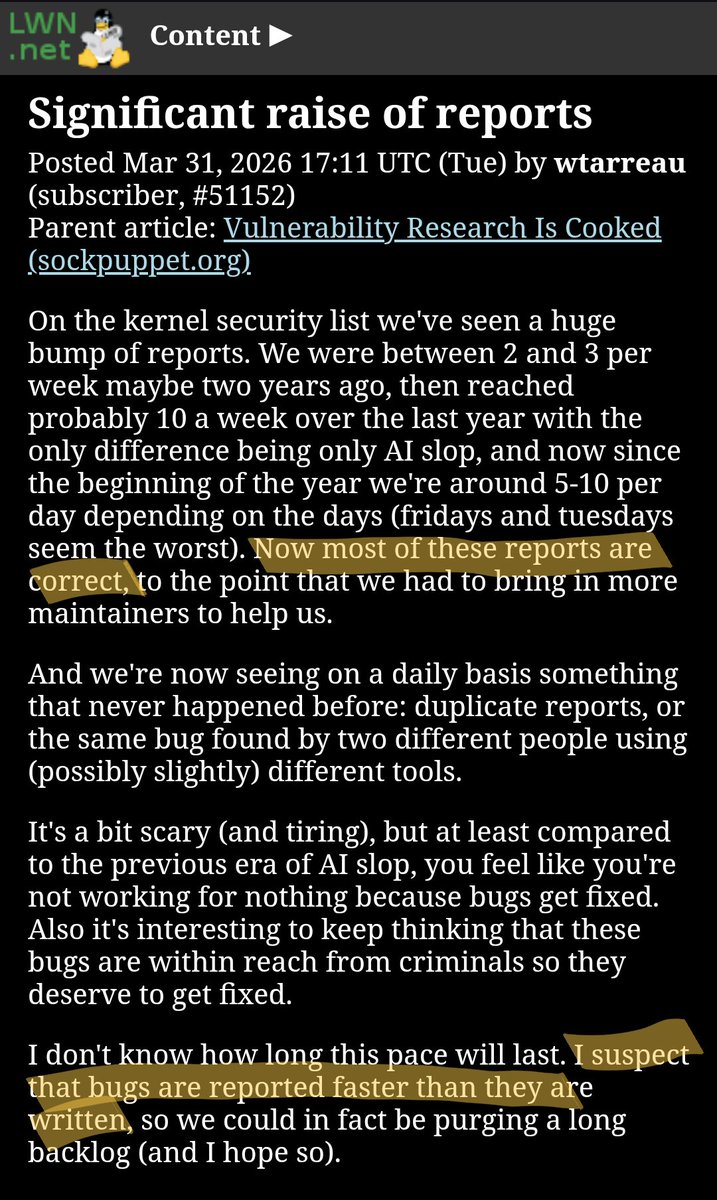
Just saving this here to document a story and as a self reflection on whether AI is really making me more productive
Yesterday morning I found a way to complete the new HVM approach, that is much faster than before. I spent a few hours writing a spec, and then used Opus to implement. About 3k lines of C code later, everything worked and performance was incredible: 5x faster than HVM4 (stable at ~10x now). So, in one day I had outclassed HVM4. Incredible. I'd never have implemented that so fast manually.
Now, enter today. I want to turn this into a real thing, but I haven't fully read the 3k lines yet. So, how do I trust it? I spent the whole day auditing the code. With AI. Several bugs found, most minor like forgetting to collect() some argument. But then I stumble upon this:
λ{ inl: 1 ; inr: 1 }
This was a test. But wait. This is matching on inl/inr. So the branches should receive the value of the Either. But they were numbers instead. Numbers aren't functions. This makes no sense. So why this is a test?
It then stuck me. The AI completely misunderstood how function arities work. It literally assumed for no good reason that HVM5 was supposed to handle under/over-applied functions. For no good reason. I never wrote that. It never asked either. It just kinda thought "HVM is weird in some aspects, this might be one of them..." - and then it went on to implement a massive system to handle cases that should never happen to begin with. And all of that code is obviously wrong because it should not even exist. It is wrong. It is damage. And it is there.
But it isn't too bad either. I just told Opus that it was wrong. Perhaps not so politely. And it solved it just fine.
But then this begs the question. I spent ~20 hours in this file, and it is STILL not done. I went from 0 to 95% in the first 5 hours. Yet, 15 hours later, it is still not 100%. I suppose that is the real effect of using AI. If I had just written the C file manually in the last two days, would I not be further than where I am *right now*?
Surely, the first version would have taken much longer to drop. But when I'd finish writing all that code, there would be zero, literally zero retarded shit. And, just today, I caught 5 or 6 retarded shit. And the worst part is: I don't know what the number of retarded shit left is, but I'm afraid it is >0.
So if I have to read it all, review it all to ensure there is no retarded shit... what did I achieve by using AI, other than that dopamine anticipation?
new grads often ask me what they should be doing so they don't fall behind in the ai space. there's a lot, but its honestly super manageable. become intimate with model internals. proof based linear algebra. non-convex optimization. this is stuff you could've done in undergrad. it definitely takes some time and work, but its doable. have taste, have opinions. train a small model, then train a big one. vLLM internals, tensor parallelism. hand roll kernels. cluster orchestration. do you have opinions on synthetic data? why don't you? SFT, PPO, you should know this. learn Triton. everyone is reproducing papers now so you need to be doing more. do you know the semi supply chain? where are the bottlenecks? hardware, man, hardware. your little gpu rig erector set in your basement isnt gonna cut it. build a cluster, a big one. pretrain a 800B model. now postrain it. serve it to millions of people. you should be able to beat deepseek on some benchmarks now. its a lot to take in but it all snowballs. this what job security looks like from now on. do you want to work in tech or not
What I like about intelligence is that everything is true:
- there is a genetic component
- yet nobody ever gets close to their cognitive ceiling
- language models deliver stunningly profound insights
- yet language is just a poor cognitive synchronization & persistence device, leaving massive room for future improvement with new AI architectures
- AI can do math
- yet humans using AI will become insanely better at math
- the bitter lesson is true
- yet it is also true that reading, thinking, disconnecting, working hard to master language and clearly articulate your most intimate thoughts, will make you infinitely smarter.
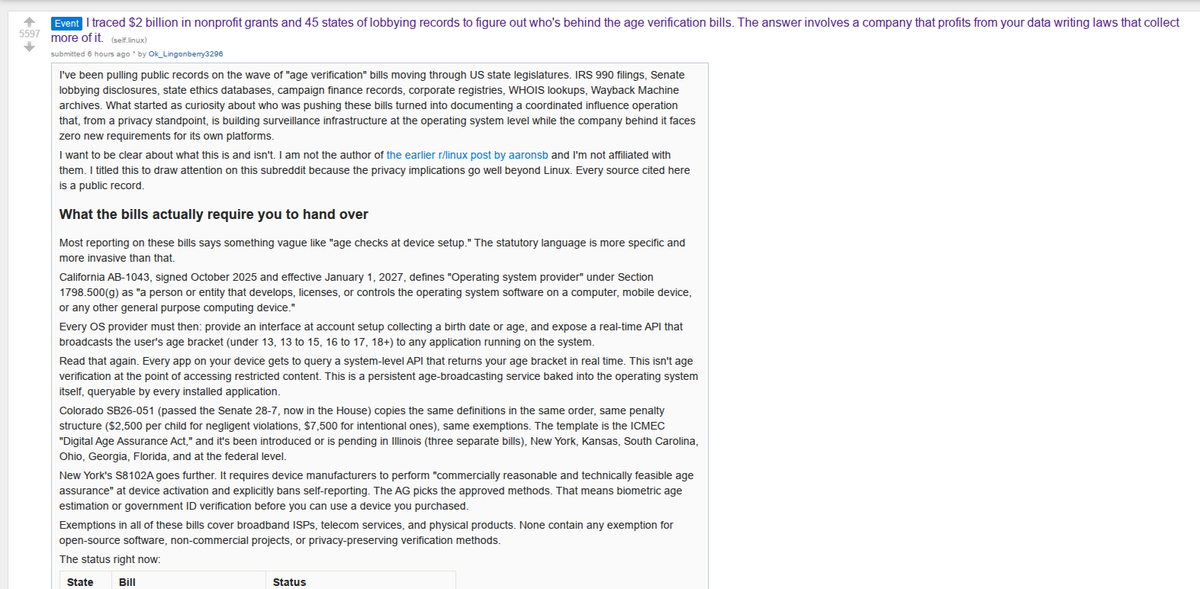
I agree that fundamentally, AI favors defense in cyber. We know that theoretically, bug free software (at least in narrow sense of conforming with spec) can exist, and as we find and fix more bugs, we can approach this asymptote.
For earth day, Pierre Computer Company is excited to announce the first public preview of…
TREES[DOT]SOFTWARE
A new, feature rich trees library – tuned for machines.
Demo of AOSP fixture (1.5 MILLION files with fixed dirs - no blanking)
kinda crazy how there's a million sorting algorithms and a solid chunk of them are actually practically used in different situations but there's really only one distributed consensus algorithm and basically everything is built on top of it with minor variations
You don't truly understand the magnitude of the potential impact of powerful AI on the world unless you are aware, and have fully internalized, that senior leadership and most researchers at the frontier labs *actually believe* the following:
1. Existing AI is already significantly speeding up AI research. Very soon (this year), AI will very likely take over *ALL* aspects of AI research other than generation of novel research ideas. Soon (within the next 2 years), AI will very likely take over *ALL* aspects of AI research, period. This means hundreds of thousands of GPUs working 24/7 to discover novel ideas at the level of, or better than, the likes of Alec Radford, Ilya Sutskever, etc. The thread below presents a conservative timeline: AI researchers will "meaningfully contribute" to AI development in 1-3 years.
2. Many (but, as far as I can tell, not all) executives and researchers at the frontier labs believe that fully automated AI research will kick off recursive self-improvement (RSI), wherein the AI models will autonomously build better and better AI models, with human oversight (for safety reasons), but increasingly with no human input into the research or implementation of that research. From the thread below: "'[h]umans vs AI on intellectual work is likely to be like human runner vs a Porsche in a race', likely very soon" - but replace "intellectual work" generally with "AI research" specifically.
RSI is a complicated and messy thing to consider, both because there will be compute and energy constrains and because there are unknowns (will there be diminishing returns from greater intelligence of the models? if so, when will these diminishing returns become meaningful? is there a ceiling to intelligence that we don't know about?). But suffice to say that, if RSI *is* achieved in a way that many leaders/researchers at the frontier labs believe is possible, *THE WORLD MAY BECOME COMPLETELY UNRECOGNIZABLE WITHIN JUST A FEW YEARS*. This is subject to various bottlenecks; as the thread below correctly notes, "[i]nstitutional, personal & regulatory bottlenecks will bind very hard", and much also depends on continuing progress in areas like robotics.
3. On ~the same timeline as full, end-to-end automation of *ALL* aspects of AI research (within the next 2 years), AI will also become capable of making significant novel scientific discoveries *IN OTHER FIELDS*. This is why Dario Amodei, Demis Hassabis et al. believe that it is possible that all diseases will be curable within 10 years. (One account of how this might be possible is set forth in "Machines of Loving Grace".) The point is that an LLM that is capable of significant novel insights in the field of AI research should likewise be capable of significant novel insights in at least some (and perhaps all) other fields. The thread below notes: "AI for automating science [is] very early" - obviously true, but I think some changes may be right on the horizon.
Overall, and again from the thread below: "'a million scientists in a data center' will think much more quickly than humans, on almost any intellectual task; this will happen in the next 2-10 years." This is ~the same timeline as that presented in "Machines of Loving Grace".
Many will be tempted to dismiss all this as "just hype", "they are just trying to raise money again", etc. But no! - the above, in fact, presents the *actual beliefs* of senior leadership and many researchers at the frontier labs. Again, they genuinely think that AI research will be automated soon. Many of them genuinely believe that RSI is achievable in the not-too-distant future. And they genuinely see a real path towards AI significantly accelerating science, curing diseases, inventing new materials, helping to solve key global issues from poverty to climate change, etc., etc.
Whether the frontier labs' beliefs are correct is, of course, a separate question. I personally have historically tended to take public statements by OpenAI, Anthropic and Google at face value and quite seriously. As a result, I was not surprised when LLMs won gold in the IMO, IOI and the ICPC competitions last year, or when Claude Code/Codex started taking off, or when Anthropic and OpenAI started releasing significantly better models every 1-2 months, or when some of the best coders became reliant on Claude Code/Codex in their daily work, or when LLMs became significantly helpful to scientists in fields like math and physics in the last few months. The trajectory has been ~the same as that publicly predicted by the frontier labs. We have been accelerating. And, as of right now, all signs are indicating that the acceleration shall continue and that full automation of AI research and, potentially, RSI are firmly on the horizon.
one of the reasons it’s hard to learn with LLMs is they don’t explain common failure modes necessary for intuition
see this random dudes blog vs sonnet 4.6 on attention
Really impressive work! It took just a few hours to formalize two classic algorithms in game theory. One of them took me three weeks, and I wrote nearly 2K lines Lean code, while Aristotle agent only spent three hours and used 400 lines. I am so surprised
Yesterday, John Morgan and I completed our “Covering Spaces Project”, whose goal was to formally (in Lean @leanprover, of course) prove the Fundamental Theorem of Algebra (that polynomials have complex roots) using only continuity: covering spaces, trivializations, and winding numbers, instead of the Mathlib proof that goes through complex analysis / Liouville.
We started the morning about 30% through the proof, and tried playing with the Codex VS code extension (running GPT-5.4, extra high reasoning). We had already written a complete natural language blueprint (last June, at the Simons @SimonsFdn Lean workshop) and were meeting for about an hour a month, leisurely working through the details by hand (John wanted to learn the process). We’d used AI before (mostly Claude) to help move things along, but this was the first time that we met after I turned on Codex.
I started by asking for Codex to give me just the formal *statement* corresponding to our next unfinished leaf in the dependency graph. It thought for 5 mins, and gave what looked like a reasonable statement. So I said, ok, can you now give a formal proof? It thought for 10 mins, and came back with a full proof, including helper lemmas. I asked it to add natural language around the helper lemmas so we’d see what they’re doing in the blueprint. It thought for 5 mins, and did it. We went on to the next statement, then the next proof, and it got those too.
It continued like this for an hour or so, and we jumped to about 60% done with the project, amazing progress! I had to run to get on a train to DC (for the DARPA meeting). Once in my seat, I decided on a whim to just tell Codex to keep working on the whole file and get as far as it could, stopping to ask me for help if it got stuck. I left VS Code running in the background, while working on other things. After an hour, I remembered to check back on what progress Codex had made.
It was done. And so was the project!
Now I’m having Codex go through the whole proof all over again, remove all our bespoke definitions and statements, and make it clean and Mathlib-ready. Many more hours of iteration later, and it’s ready to go as a PR.
Wild wild times we’re living in!