This time we should say goodbye to PPO/GRPO for real 👋
PPO is a great algorithm in classical RL settings. However, it is fundamentally flawed in LLM regime due to the large, long-tailed vocabulary.💔
Checkout our paper for more details👇
Really a nice note on DPPO, covering every key message with very clear takeaways. 👇
If anyone want to know DPPO quickly without reading the tedious paper, I strongly recommand you to read this blog first!
Thank @pradheepraop for this awesome summary 🙏
@pradheepraop I read through the whole blog, and found it is really nice to me. It is succinct, but every key point in my mind is well presented.
It is really a good write👍
Really a nice note on DPPO, covering every key message with very clear takeaways. 👇
If anyone want to know DPPO quickly without reading the tedious paper, I strongly recommand you to read this blog first!
Thank @pradheepraop for this awesome summary 🙏
really enjoyed reading dppo.
the key statement imo:
ppo clips the sampled action ratio, but the trust-region violation actually comes from how far the full policy distribution moves.
wrote a short summary with intuition + derivations (math mode).
thread below ↓
https://t.co/cXdCWzklMW
Interesting results! 👍
Let me put more on the precision comparison between BF16 and FP16, on RLHF task (using a reward model) 👇
The numerical stability really matters a lot in RL👀
Find more in our FP16 paper: https://t.co/AjCjtWquEq
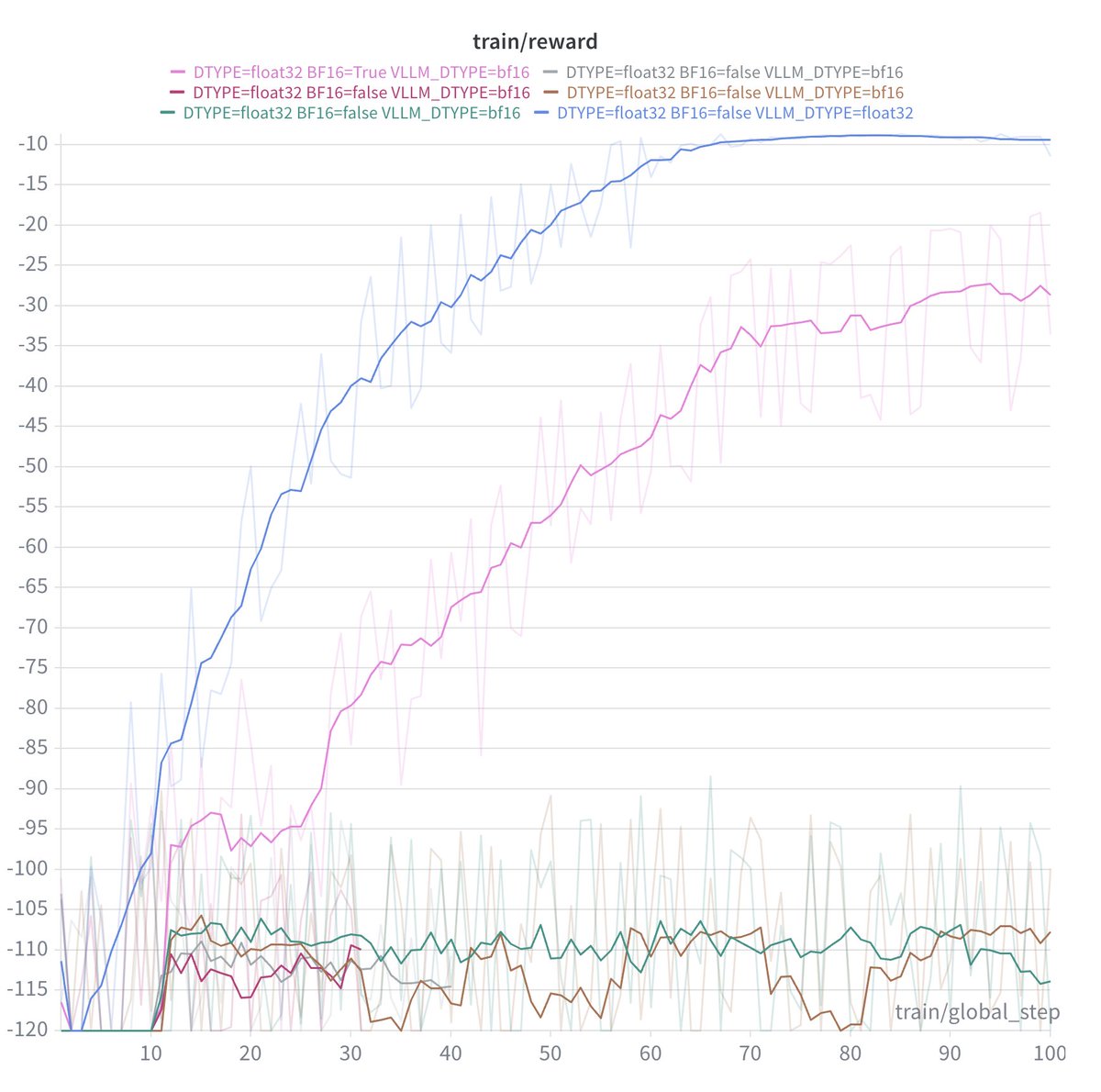
Been going down a massive rabbit hole with numerical stability in RL training lately.🕵️♂️🕵️
Take a look at these two GRPO sanity runs. Exact same model, identical task. One climbs perfectly, the other completely flatlines. The only difference? The dead run is in bf16, the successful one is fp32.
What do you think the problem is with these runs? Drop your best guesses below !
Finally finished!
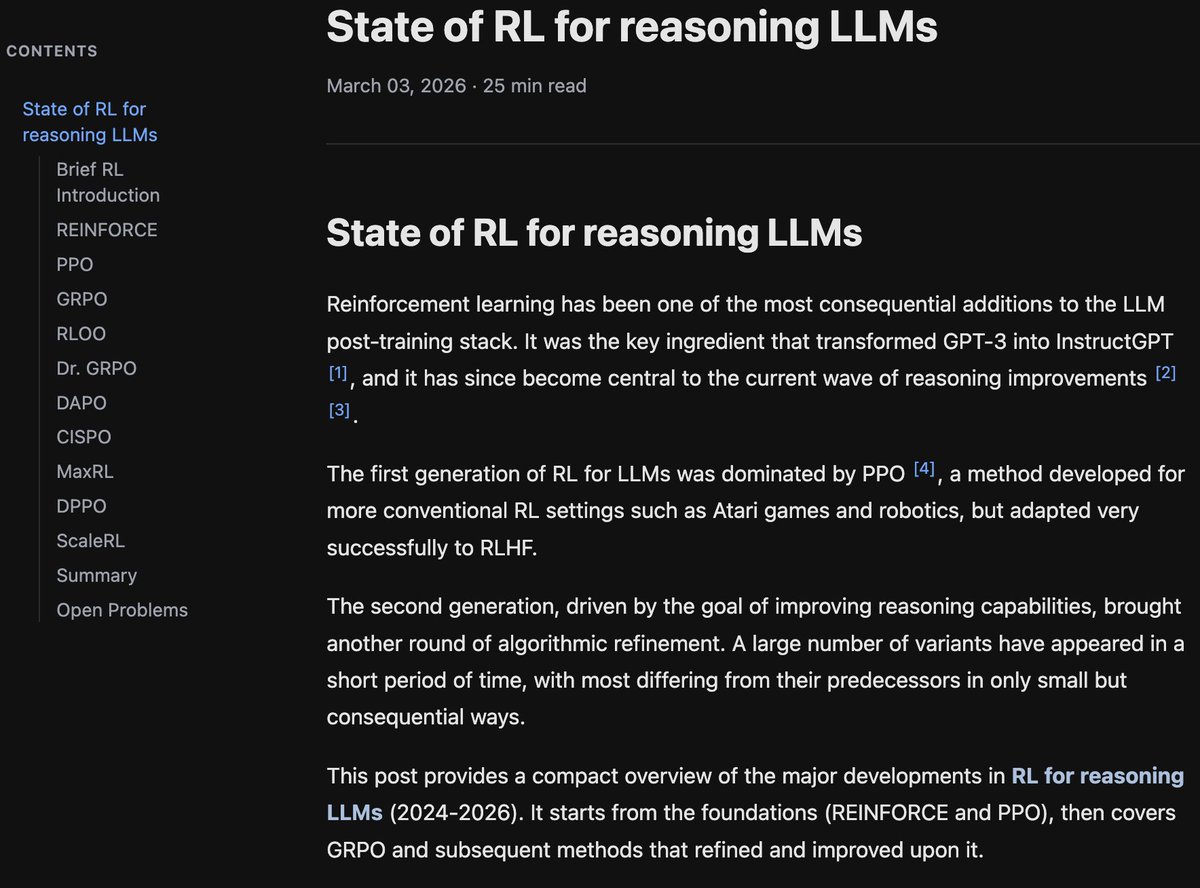
If you're interested in an overview of recent methods in reinforcement learning for reasoning LLMs, check out this blog post: https://t.co/SHUyFF4rvP
It summarizes ten methods, tries to highlight differences and trends, and has a collection of open problems
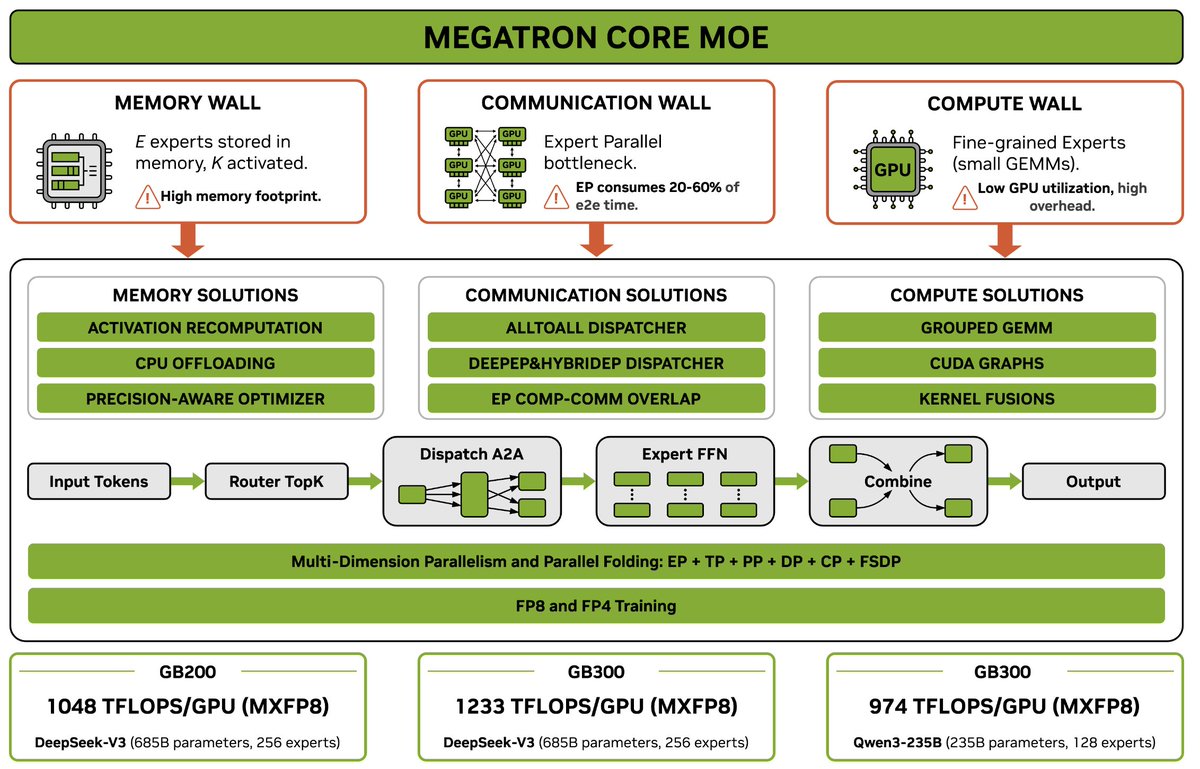
I was reading megatron code again recently for a moe project. It does improve a lot regarding both the efficiency and code quality, so many known optimization techniques integrated while the code remains readable.
Awesome work! 👍
My last open-source project before joining xAI is just out today. Megatron Core MoE is probably the best open framework out there to seriously train mixture of experts at scale. It achieves 1233 TFLOPS/GPU for DeepSeek-V3-685B. https://t.co/QA1KRGu2Nc
AReaL v1.0 released: Effortless #RL to make your #OpenClaw self-evolve 🚀:
•🛠️ One-click agentic RL for any existing agent
•📈 Open-source SOTA on tau2-bench
•💎 A new PyTorch-native 5D-Parallel Engine Archon
•🤖A full #opencode recipe
GitHub: https://t.co/bHaE6lRzXt
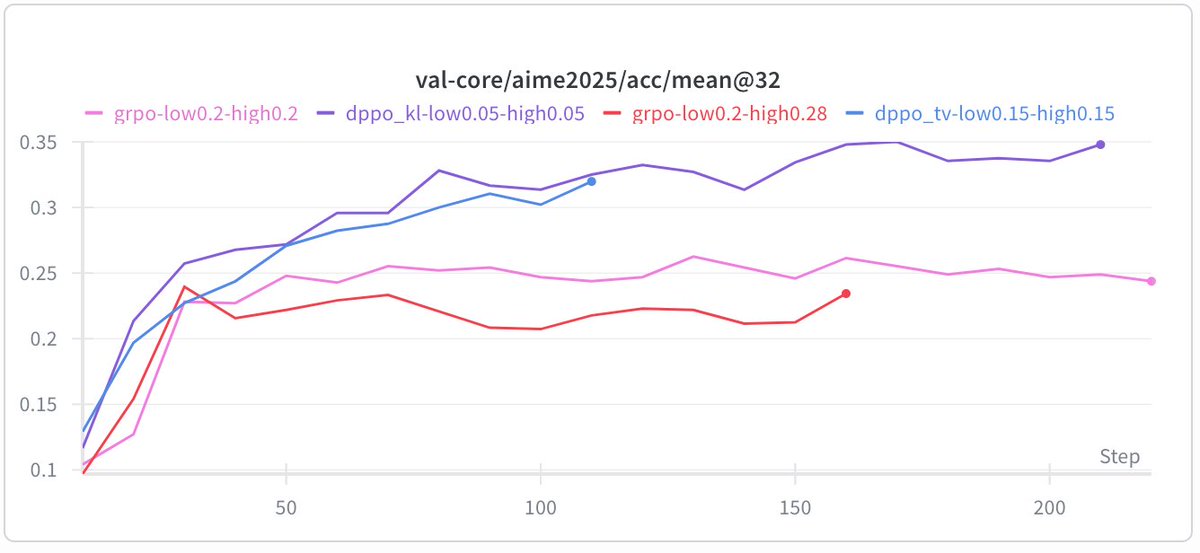
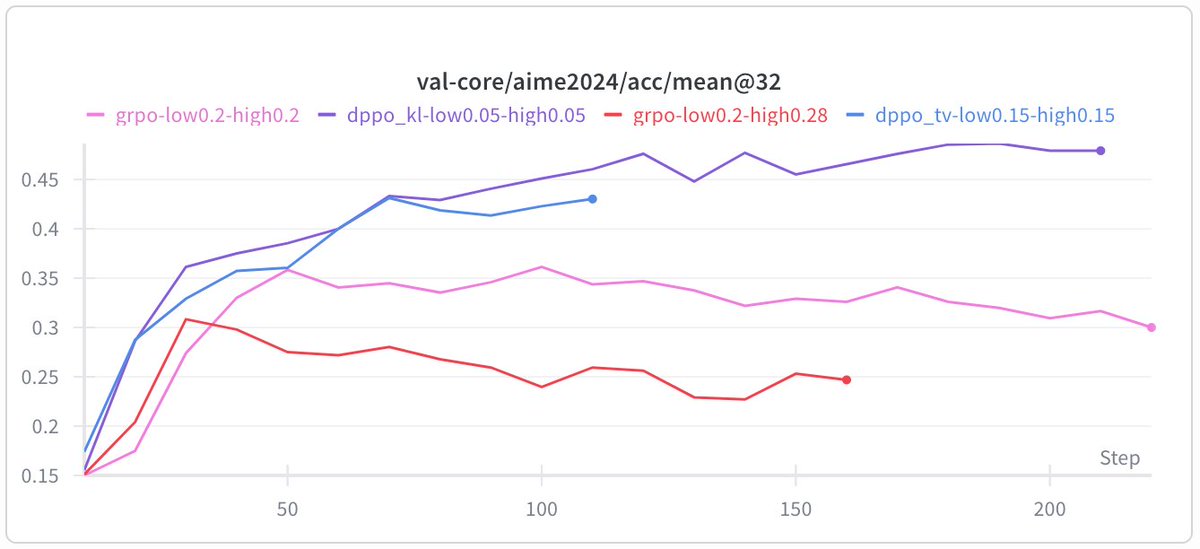
Today's paper was "Rethinking the Trust Region in LLM RL".
It is a clean theoretical and empirical case for why PPO's (and GRPO's) ratio clipping is fundamentally mismatched to LLM vocabularies, and what to do about it. (Yesterday we saw that DAPO proposes to clip-higher, today we see another solution)
The core problem: PPO clips based on the probability ratio of the sampled token. But this is a noisy single-sample Monte Carlo estimate of the true policy divergence. For large vocabularies this breaks in both directions:
- A rare token going from 0.001 to 0.003 produces ratio 3.0, gets hard clipped, even though the actual divergence is negligible. This over-penalizes exploration tokens and slows learning.
- A dominant token dropping from 0.99 to 0.80 gives ratio 0.81, and stays inside the clip. But you just moved 0.19 probability mass, a potentially catastrophic shift that goes unpenalized.
The training/inference engine mismatch makes it worse: even with identical parameters, the probability ratio is highly volatile for low-prob tokens between frameworks, while total variation (TV) divergence stays stable.
Their fix (DPPO): replace ratio clipping with a mask conditioned on a direct estimate of policy divergence (TV or KL). Full divergence over the vocab is too expensive, but they show a binary approximation (just compare the sampled token's prob under both policies) or top-K approximation both work well empirically.
Three useful empirical takeaways from their stability analysis:
1. Trust region is essential even at tiny learning rates (1e-6). Without it, training/inference mismatch accumulates and training collapses.
2. Trust region must be anchored to the rollout policy, not a recomputed on-policy distribution. Decoupled objectives that use recomputed anchors fail.
3. Instability comes from a tiny fraction (less than 0.5%) of updates on negative samples that push the policy far outside the trust region. A minimal mask blocking just these is enough to stabilize training.
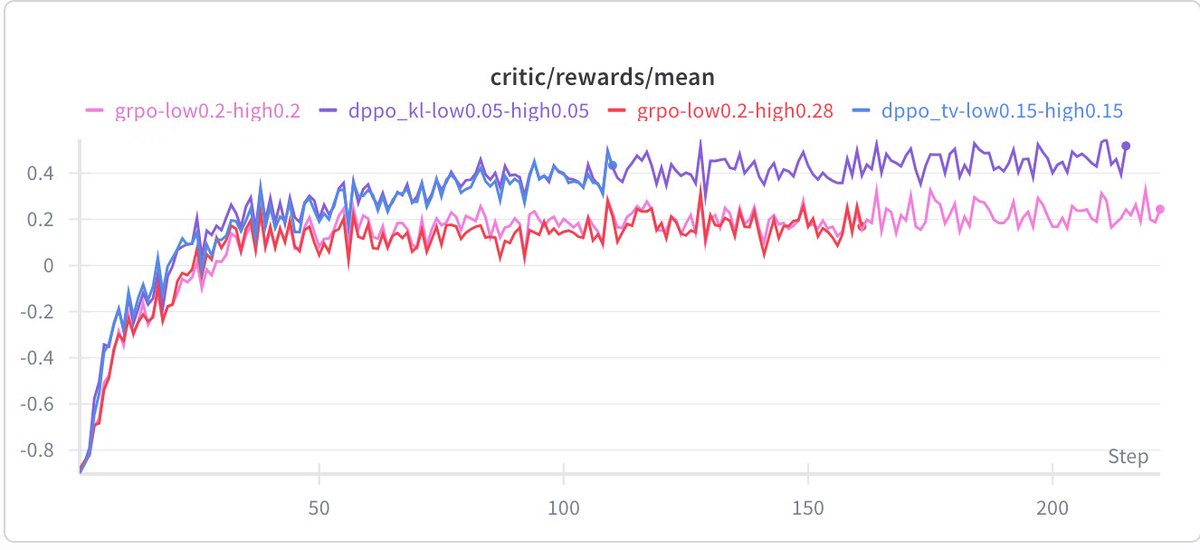
DPPO consistently outperforms GRPO-ClipHigher and CISPO baselines across five model configs (Qwen 3B, 8B, MoE, with/without R3, LoRA), often matching or beating R3-enhanced baselines without using rollout router replay at all.
It also has a long appendix that I still have to work through :)
Overall highly recommend it if you are interested in RL for LLMs and want to know what is going on in the trust regions.
Great and important paper from @QPHutu, @NickZhou523786, @zzlccc, @TianyuPang1, @duchao0726, and @mavenlin
@ericssunLeon@tongyx361 Hi Leon, many thanks for your great efforts. 🙏
I just reviewed the PR and leaved some comments (mainly for typo and default hyperparameters). Overall it looks nice!👍
This time we should say goodbye to PPO/GRPO for real 👋
PPO is a great algorithm in classical RL settings. However, it is fundamentally flawed in LLM regime due to the large, long-tailed vocabulary.💔
Checkout our paper for more details👇
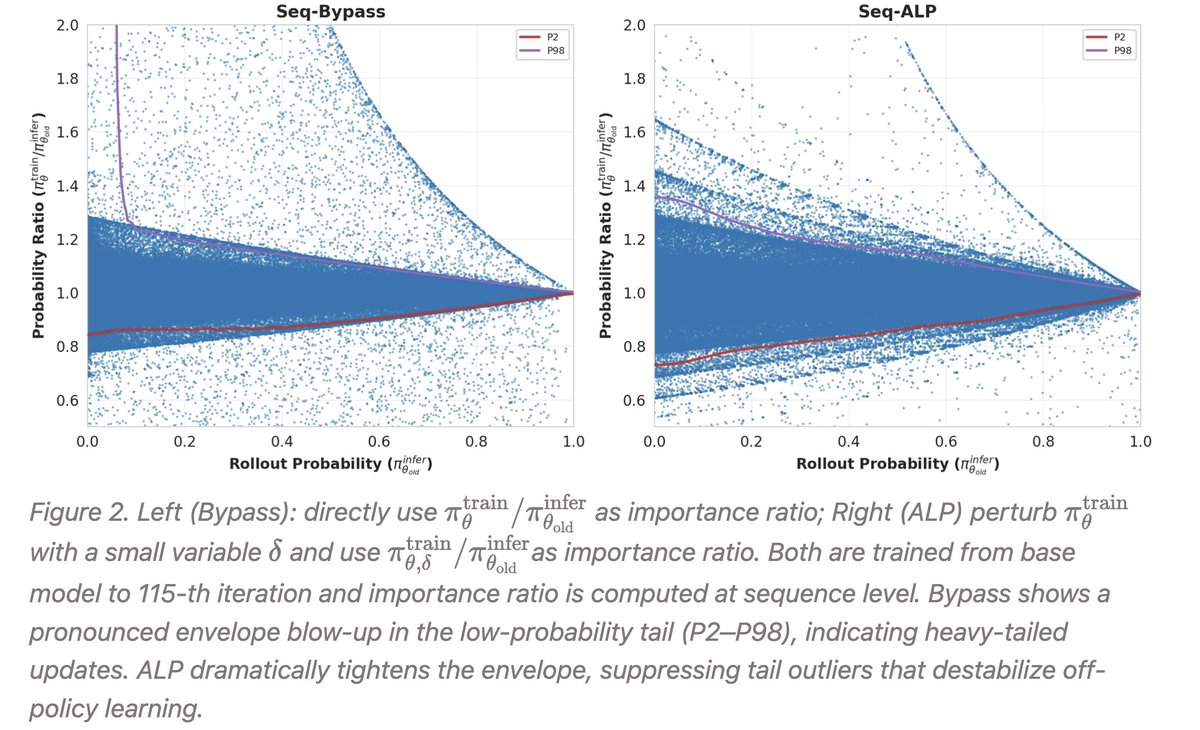
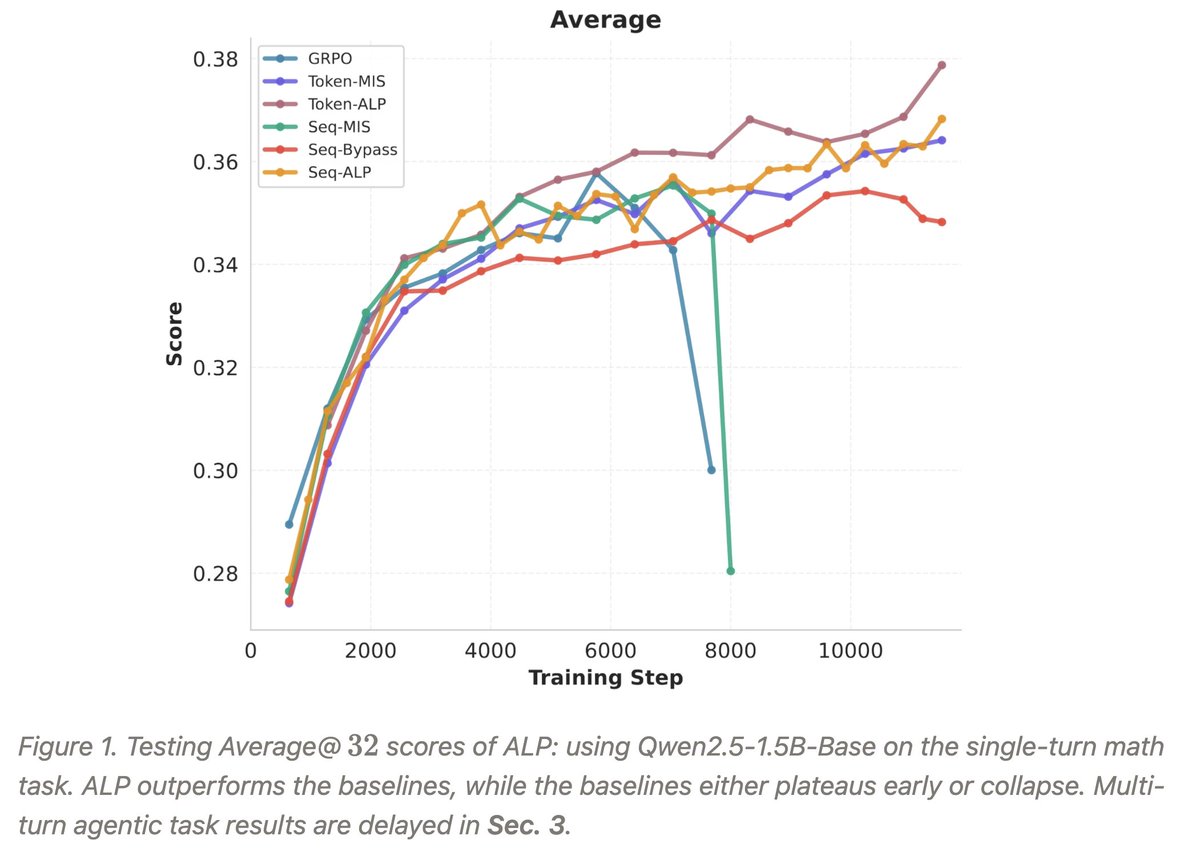
1/5 Happy CNY🎊 Still bothered by RL off-policy instability in LLM?
Introducing a new way💡Adaptive Layerwise Perturbation (ALP)💡, a simple but robust fix that outperforms GRPO/MIS/Bypass, achieves better stability (KL, entropy) and exploration!
🔗 Blog: https://t.co/0def1Nb7uI
@ericssunLeon We use the same importance sampling (pi_theta / mu_theta'), only changing the mask. The mask is based on (pi_theta / pi_theta').
It is similar to miniRL, so the training-inference mismatch is also corrected.
code: https://t.co/jExwN8aApU
This time we should say goodbye to PPO/GRPO for real 👋
PPO is a great algorithm in classical RL settings. However, it is fundamentally flawed in LLM regime due to the large, long-tailed vocabulary.💔
Checkout our paper for more details👇
Introducing Aletheia, a math research agent powered by an advanced version of Gemini Deep Think that produces publishable math research (two papers, one completely automatic and another with human-AI collaboration) and solved multiple open Erdős problems. 😀🔥
Paper link below! 👇
Sad for losing a fantastic daily collaborator in Sea AI Lab, but happy for Zichen for his new journey.
Thank you for everything, and wish you all the best on your next adventure! 🚀✨
Thrilled to share that I’ve joined @GoogleDeepMind to work on Gemini post-training!
I feel incredibly fortunate to be cooking on this sunny island under @YiTayML's leadership, within @quocleix's broader organization. Looking forward to enjoying RL research and pushing the frontiers of Gemini alongside such a brilliant team!