Was doing CVPR review and found gemini is doing pretty well on literature search. When I ask about GRPO, it can trace back to SCST and VIMCO without search, neither of them were cited by GRPO. So I made this GPTs to find missing related work:
https://t.co/2FYTrVfDoh
In the coming weeks, @Waymo will double the number of cities we’re driving fully autonomously in, with Miami (starts today), Dallas, Houston, San Antonio, and Orlando all coming online ahead of serving public riders next year. One Waymo Driver, 24/7, across 10 different cities – with many more on the way!
🤯 We cracked RLVR with... Random Rewards?!
Training Qwen2.5-Math-7B with our Spurious Rewards improved MATH-500 by:
- Random rewards: +21%
- Incorrect rewards: +25%
- (FYI) Ground-truth rewards: + 28.8%
How could this even work⁉️ Here's why: 🧵
Blogpost: https://t.co/jBPlm7cyhr
Guess: just like go players nowadays who are trying to be the best AI imitator, kids from K-9 would be taught to mimic AI thinking process for academic learning.
“I did it to make my presentations look humorous. Nobody at MIT taught us DEI or respect.”
- Excuse given by MIT Media Lab researcher who has received many recognitions.
NOTE: Most MIT Media Lab researchers I know are highly respectful and morally upright.
Mitigating racial bias from LLMs is a lot easier than removing it from humans!
Can’t believe this happened at the best AI conference @NeurIPSConf
We have ethical reviews for authors, but missed it for invited speakers? 😡
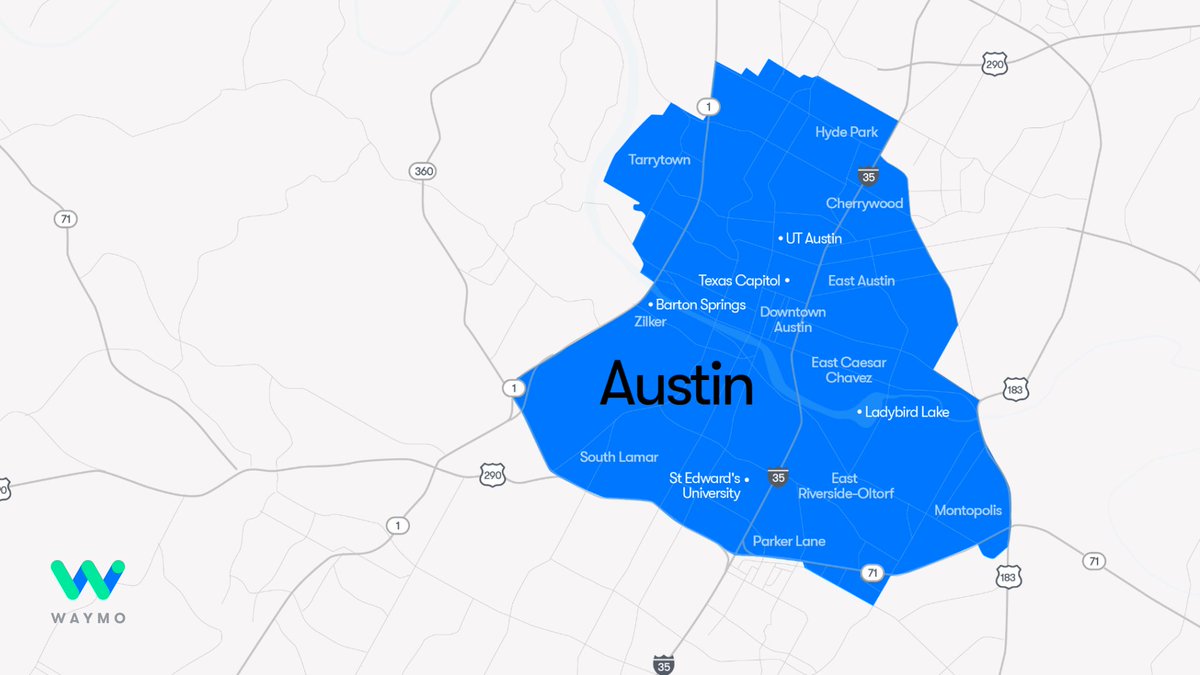
This week, we’re beginning to welcome riders in Austin from our interest list to try our fully autonomous ride-hail experience. Riders will travel across 37 square miles of the city, as we prepare for our commercial launch early next year - exclusively on the Uber app. Learn more: https://t.co/yjOv1nclJg
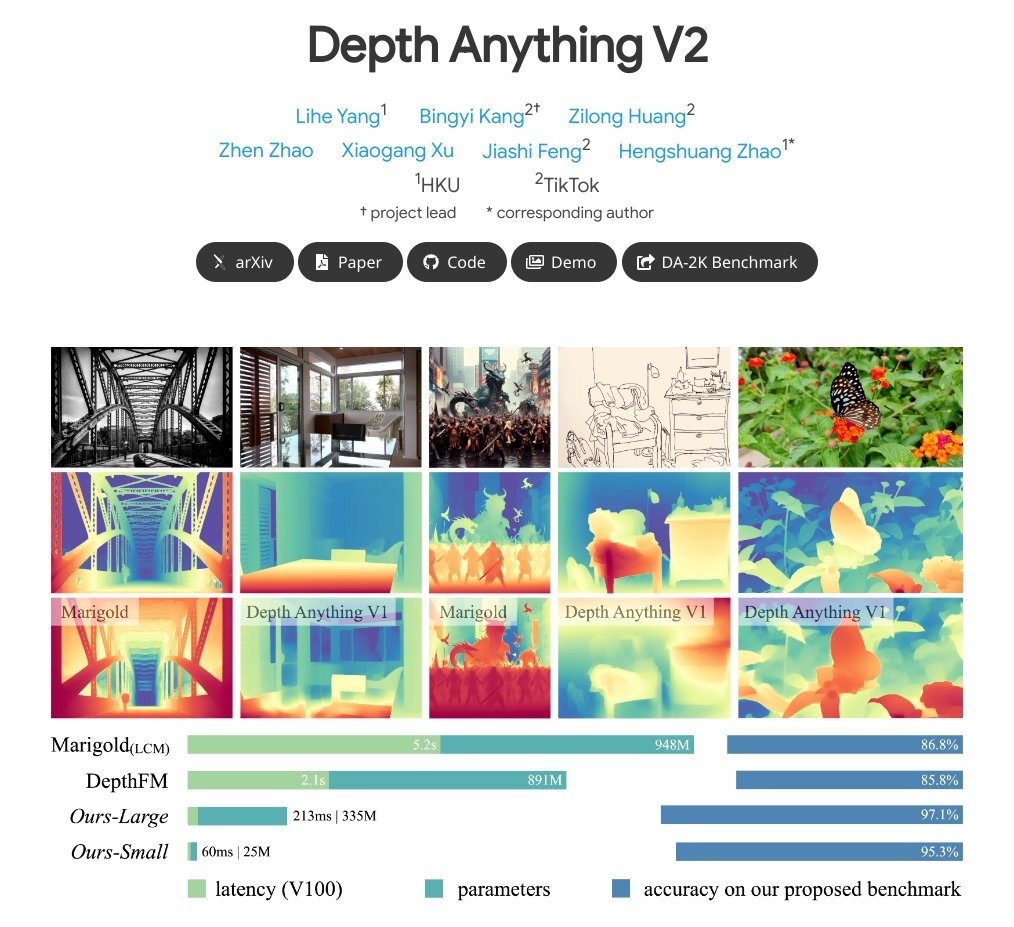
TikTok presents Depth Anything V2
Trained from 595K synthetic labeled images and 62M+ real unlabeled images, providing the most capable monocular depth estimation model
proj: https://t.co/KaOQauiOST
abs: https://t.co/9HxIpsPWJJ
Unbelievable! This is not a real video!
This was made with Kling - a new video model that looks better than Sora...
13 more crazy examples and link to the project below 👇
https://t.co/o92pVDagZJ
Last week when presenting Parti (https://t.co/qRlcWodcZf) at ICLR, I explained at least 20 times how I felt about autoregressive text-to-image generation models vs. diffusion models. So this is my take:
The major benefit of autoregressive image generation models is that they just predict image tokens, which makes it super easy to integrate into your LLM pretraining stack. Tokens in, tokens out: everything becomes just seq2seq! This also works for audio (https://t.co/A66k8RIagR) input and output. All modalities become sequences of discrete tokens, so it's easy to train once you learn the first stage to quantize image/audio.
For frontier companies like Google/OpenAI, this is advantageous from a systems perspective, because existing infrastructure is often already hyperoptimized for training transformer models on next-token prediction. In my experience, training these models is also a lot more stable than diffusion models or GANs. Another major benefit is that your model is a standard transformer, and you can use all the wonderful LLM bag-of-tricks that other people have developed: FlashAttention, speculative decoding, and other MLsys goodies.
One thing that others have pointed out is that these models seem really good at text rendering (if GPT-4o is such a model). This makes a lot of intuitive sense since it's generating discrete patches one by one (which can be thought of as patches of individual characters). I was also impressed by this ability of Parti to render text well in 2022.
So why doesn't everyone train such a model? One major downside is that you need to learn some kind of VQ-VAE (https://t.co/oUqVhRx7q1) to compress images/audio into discrete tokens. This means that your overall generation quality is upper bounded by how good this quantizer is. If you mess up this first stage, it can be very hard to generate high quality images even if your second (transformer) stage is strong. Another downside for training VLMs this way is that you potentially use much more compute by being a multi-modal model from the beginning (as opposed to training a LM on text only data, a vision encoder on images, and stapling them together at the end with some multimodal data).