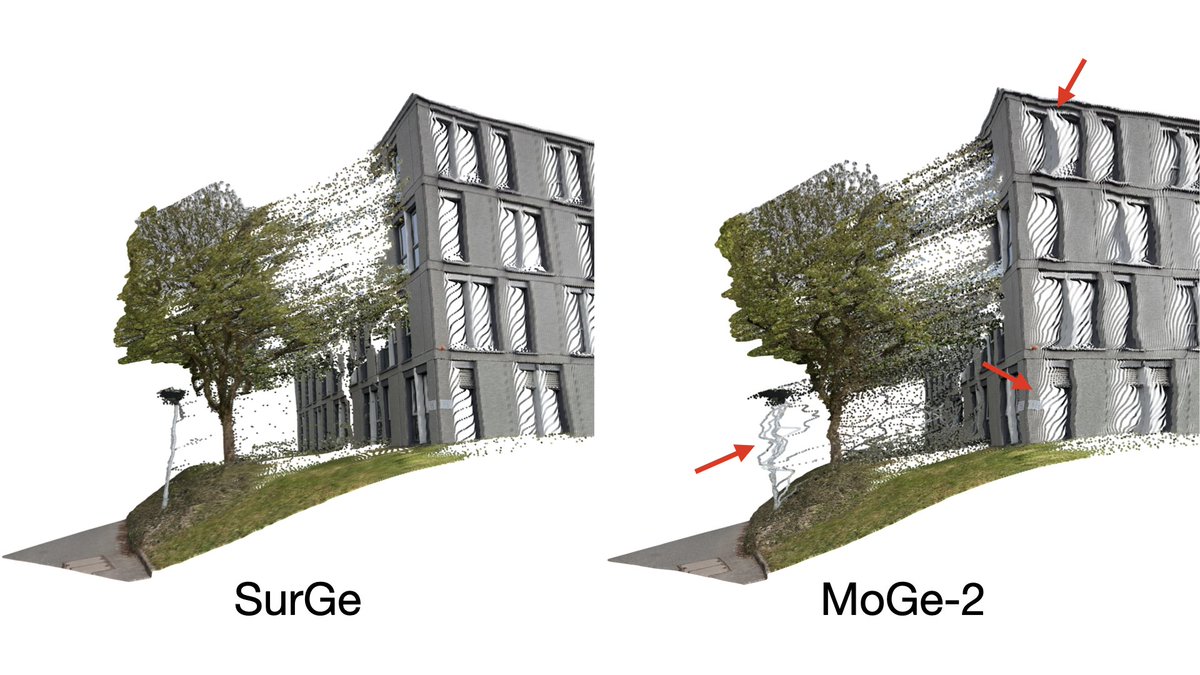
New work: SurGe
We improve local accuracy in feedforward 3D reconstruction. Current point map models struggle with bending and oscillating artifacts for thin structures (chair legs, street lamps, etc). Easy to spot visually, but not well captured by pointwise metrics like AbsRel.
The poster for our #CoRL2023 paper on Lidar 4D panoptic segmentation will be up on Thursday (Nov 9) at 4:15pm! We propose a cool new multimodal approach for Lidar segmentation + tracking that leverages both Lidar scan and camera image data.
Website: https://t.co/JoBk5spl57
💥 I'm pleased to announce our @CVPR Highlight paper: "TarViS: A Unified Approach for Target-based Video Segmentation".
💥TL;DR: We developed a single, jointly trained model that can tackle multiple video segmentation tasks e.g. VOS, VIS, VPS and achieve SOTA performance.
📢 Announcing Tracking & Its Many Guises (2nd Edition) workshop on June 18 at #CVPR2023! We are organizing two exciting multi-object tracking and segmentation challenges: Open-World & Long-Tail Tracking🏅Let’s innovate together!🤖 More info at: https://t.co/BZjTxicy6Z
Mask3D 🎭 is now at #ICRA2023, great work @JonasSchultCV!
We use Mask Transformers for 3D Instance Segmentation on Point Clouds ~ 🥇 on ScanNet
📰Paper: https://t.co/oGeepTsSqz
🛠️Project: https://t.co/gDNRDvLJJa
👨💻Code: https://t.co/FmBYExYy6S
@Pandoro89 @orlitany@SiyuTang3
En route to #WACV2023!
I'll present a paper on extreme multi-dataset learning of 3D human pose estimation when labels have different skeleton formats.
Paper: https://t.co/kJshBhV8hm
Project page: https://t.co/0UOW16pKdD
I'm pleased to announce our new dataset for object segmentation in video called BURST (Benchmark for Unified Recognition, Segmentation and Tracking).
URL: https://t.co/LIL9GQJzkr
This'll be a game-changer for people working on VIS, VOS, MOTS & open-world tracking: (1/5)
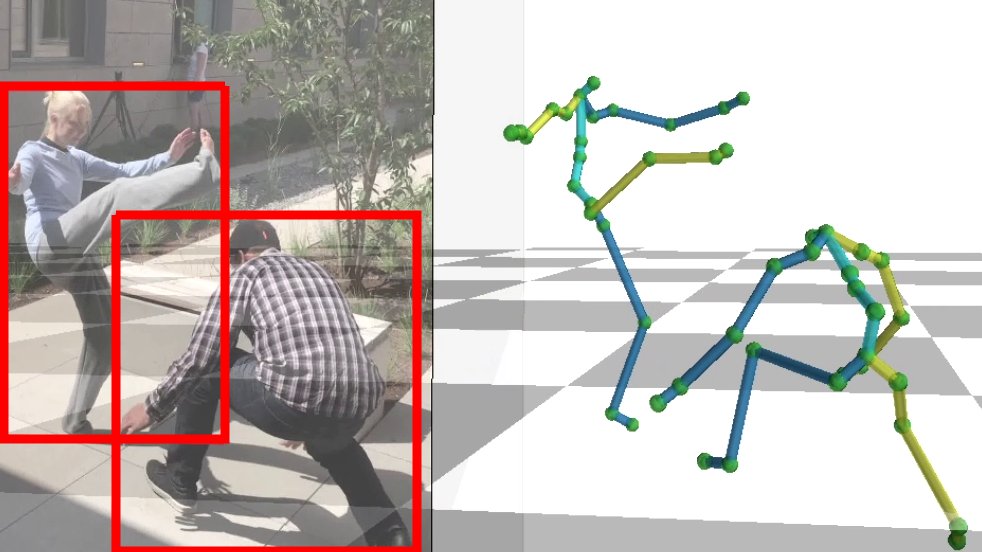
I'll demo our latest 3D human pose model @eccvconf
(Oct 26), trained on 28 different datasets at once.
https://t.co/jiNVSUUBJI
https://t.co/U0zfcrBwuI
A lack of 3D pose data used to be a big issue, but many new datasets have been released in the last few years. Let's use them!
Our workshop paper on 'Differentiable Soft-Masked Attention' is now up on Arxiv: https://t.co/K6LJy7sovl
We'll be presenting this at the Transformers for Vision (T4V) workshop at @CVPR'22!
Pleased to announce that we have 2x #CVPR2022 oral papers accepted:
1. HODOR (yes that's the name of the paper): https://t.co/o0aWS07Xzf
2. Opening up Open World Tracking https://t.co/TzIPumygYw
@aliathar94@JonathonLuiten @Pandoro89 @AljosaOsep
MeTRAbs got a new EffNetV2 backbone and works better than ever. Simple API, everything packed into one easy-to-use TensorFlow SavedModel. No repo cloning, just get the model and predict.
Code, model links: https://t.co/VR0HWMM7Ts
More qualitative results: https://t.co/yDuJlcrS6B
Your 3D model is overfitting?🥴
Then check out Mix3D!🤗
Simply "mixing" two 3D scenes improves generalization in only 4 lines of code!🤓🤯
Great work! @kumuji@JonasSchultCV@orlitany
🥇 1st Place on ScanNet
🤩 Oral @3DVconf
📰 https://t.co/VAeKoMJjXn
🛠️ https://t.co/N6l66mSvuM
Today @CVPR visit our paper "From Points to Multi-Object 3D Reconstruction" Joint reconstruction of multiple objects🍣 from a monocular image🧐 @krematas B.Leibe @VittoFerrariCV
👉#CVPR2021 Session 4
⏰17:00 CET / 11:00 EDT
📄https://t.co/ZSkq3wDqNB
🧑💻https://t.co/HjBxvMVHE1
Multi-Object Tracking (MOT) has been notoriously difficult to evaluate, and evaluation has been a constant source of frustration for many.
Check out this blog post (https://t.co/dWJWvdSuHI ) which describes our recent work on the HOTA metrics for better tracking evaluation! 1/6
DR-SPAAM, our real-time person detector from 2D range data, has been picked by @NVIDIAEmbedded as the "Jetson Project of the Month" for September 2020!
https://t.co/k2cHTJKlD9
Paper (IROS'20): https://t.co/RPZQIH32i1
Code: https://t.co/e9BTtOSyFc
Video: https://t.co/RVpMI1IrJ5
Our state-of-the-art MeTRAbs absolute 3D human pose estimation model is now released for #TensorFlow! @IEEEFG2020 @RWTHVisionLab
Code: https://t.co/VR0HWMM7Ts
Video: https://t.co/RExTL8lmDB
Paper: https://t.co/sqaspYA5Tq
Check out our WACV'21 paper on "Reducing the Annotation Effort for Video Object Segmentation Datasets", we introduce a new video object segmentation benchmark!
https://t.co/CGvyZCPke1
#wacv#wacv2021#wacv21#Videoobjectsegmentation
Tomorrow we'll be having live Q/A sessions for our paper "Making a Case for 3D Convolutions for Object Segmentation in Videos" at BMVC 2020: https://t.co/wAmC2eMT3X
@RWTHVisionLab@AljosaOsep@lealtaixe