Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
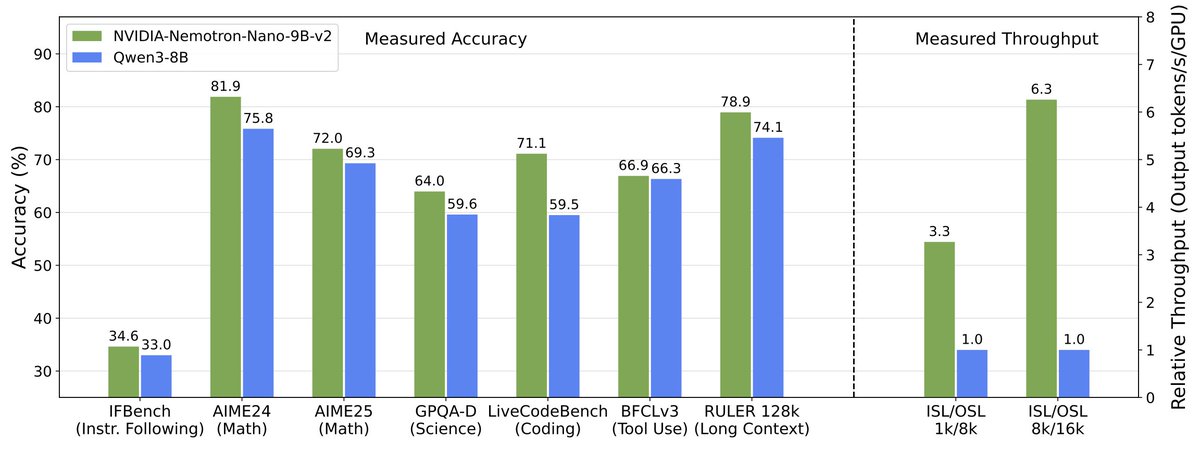
Today we're releasing NVIDIA Nemotron Nano v2 - a 9B hybrid SSM that is 6X faster than similarly sized models, while also being more accurate.
Along with this model, we are also releasing most of the data we used to create it, including the pretraining corpus.
Links to the models, datasets, and tech report are here:
https://t.co/NqSYULoiW3
Nemotron-H: A family of Hybrid Mamba-Transformer LLMs.
* Hybrid architecture means up to 3X faster at the same accuracy
* Trained in FP8
* Great for VLMs
* Weights and instruct versions to come soon.
https://t.co/h3dLuDuiUz
A 8B-3.5T hybrid SSM model gets better accuracy than an 8B-3.5T transformer trained on the same dataset:
* 7% attention, the rest is Mamba2
* MMLU jumps from 50 to 53.6%
* Training efficiency is the same
* Inference cost is much less
https://t.co/x62otbC5uN
Data pruning to reduce pertaining costs is hot, but fancy pruning can take just as long to select data as to train on all of it! Patrik, @Rwaleffe, and @vmageirakos's work at #ICLR2024 tomorrow shows how a simple, low-cost tweak to random sampling outperforms trendy methods!
🚨 "MariusGNN: Resource-Efficient Out-of-Core Training of Graph Neural Networks" with @RWaleffe is available now!
🎧 Listen on Spotify ➡️ https://t.co/PgTrDblzJx
☕️ Support the podcast ➡️ https://t.co/tVHEIk5EgN
Not convinced about using random sampling for data pruning? Consider twice! In our recent work, we introduce Repeated Sampling of Random Subsets: https://t.co/jk2dWHpocl, where we sample a subset of data at each epoch of training instead of only once at the beginning!
@BlackHC Regardless of which ‘viewpoint’ one chooses to look at our method with, this algorithm had yet to be studied extensively (empirically and theoretically).
@BlackHC If the sampling of S’ across rounds is done without replacement (instead of with replacement), then our method can also be seen as training on the full dataset but with early stopping after a few epochs (discussed in the paper). This version is particularly useful for analysis.
Marius, another amazing KGE (and more) library is now auto-formatting its code with black as of https://t.co/bCxU19K73t 🚀
@JasonMohoney @RWaleffe nice job :)