We have a live webinar coming up on February 11th.
You won't want to miss it!
AI support agents don’t fail in demos; they fail in production.
Join RagMetrics to see how teams evaluate AI support agents in real time.
👉 Register now - https://t.co/huJHtSLtEe
We're partnering with @RagMetrics to deliver built-in AI quality & EU compliance on @SerenityStar_AI, helping enterprises deploy trusted AI, faster.
Discover how this reduces adoption barriers and drives growth across regulated sectors👇
https://t.co/BLSyfF323E
AI chatbots don’t fail in testing.
They fail quietly in production.
Suddenly, accuracy drifts, or hallucinations creep in—and you don’t know until users do.
See how teams evaluate AI support agents in real time.
👉 Register: https://t.co/wMygg9VWQU
@KeithSakata We have a webinar coming up, and we want you to attend.
Understand best practices when evaluating AI agents in production, with real-time detection of:
• Hallucinations
• Accuracy issues
• Context drift
Click here to attend: https://t.co/hB64ziA4Oc
On February 11th, our CEO and founder, Olivier Cohen, will highlight why we built Live AI Evaluation at RagMetrics.
Understand best practices when evaluating AI agents in production, with real-time detection of:
Click here: https://t.co/hB64ziA4Oc
We have a live webinar coming up on February 11th.
You won't want to miss it!
AI support agents don’t fail in demos; they fail in production.
Join RagMetrics to see how teams evaluate AI support agents in real time.
👉 Register now - https://t.co/huJHtSLtEe
RagMetrics at RAISE Summit 2025: Elevating LLM Reliability & ROI
At the @RaiseSummit 2025, @RagMetrics is showcasing its evaluation platform for large language models (LLMs), designed to ensure reliability in real-world applications. This platform automates rigorous testing of retrieval-augmented generation systems, measuring outputs, retrieval accuracy, and consistency far beyond standard benchmarks.
Founded in 2024 and based in Miami, RagMetrics assists AI teams in identifying "silent failures”, issues that may pass standard benchmarks but become apparent in actual usage. The platform supports any model or use case and offers over 210 built-in rubrics, custom metrics, A/B comparison capabilities, and synthetic data generation.
Companies that use RagMetrics report a 95% agreement rate between human evaluators and LLMs, bridging the gap between automated assessments and real user judgment. Users can leverage this tool to optimize retrieval quality, balance latency and cost tradeoffs, and demonstrate return on investment (ROI) before launching their products.
RagMetrics' presence at the RAISE Summit 2025 highlights its mission to make AI trustworthy and actionable. The platform empowers teams to launch LLM applications confidently, supported by transparent, data-driven metrics that enhance user trust and improve business outcomes.
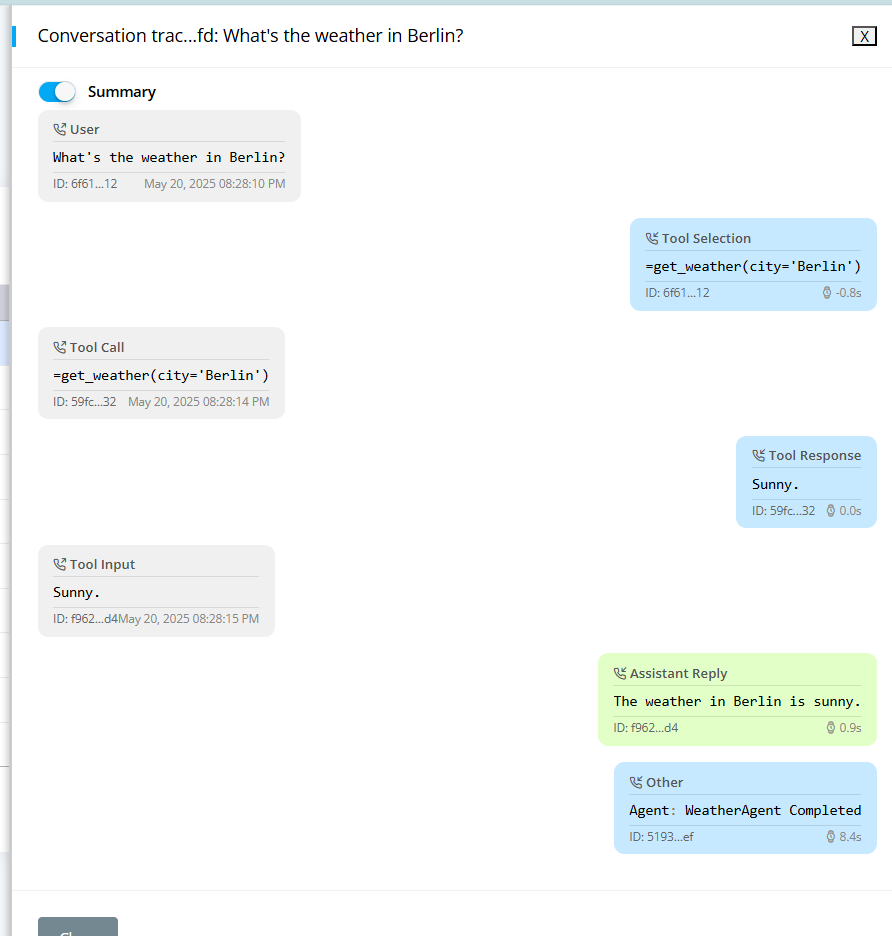
With two extra lines of code, you can review conversations between your OpenAI Agents, users and tools. Looks like any other thread on Teams, Slack or WhatsApp. Oh, and it's free!
https://t.co/00roUchSo2
@langchain Interesting article: if you want to learn more how RAG systems could be evaluated either on the retrieval or the generation phases check https://t.co/iC3PHHGJw4 or reach out to us.
At the 2025 Fintech Conference, Federal Reserve Governor Michael Barr raised critical concerns about AI in the financial sector, highlighting issues like hallucinations, inaccuracies, non-deterministic outputs, and regulatory compliance.
https://t.co/JOED2Hf0g6
#aip#ai#ml