Very excited to share our new paper, accepted at ICDAR 2026: "Leveraging Morphology for Historical Script Metrological Analysis"! 📜We present a method to automatically extract high-quality character prototypes and compute stable paleographic measurements:
https://t.co/fXPF4SFjT8
Very excited to share our new paper, accepted at ICDAR 2026: "Leveraging Morphology for Historical Script Metrological Analysis"! 📜We present a method to automatically extract high-quality character prototypes and compute stable paleographic measurements:
https://t.co/fXPF4SFjT8
By unifying detection and reconstruction, our approach predicts accurate bounding boxes to deforms these learned prototypes. This unlocks objective metrics (like aspect ratios, bi-gram distances) without any manual segmentation! 📐
w/ @malamatenio_ , /D. Stuzmann /M. Aubry
Introducing Chapter-Llama [#CVPR2025], a framework for 𝐯𝐢𝐝𝐞𝐨 𝐜𝐡𝐚𝐩𝐭𝐞𝐫𝐢𝐧𝐠 using Large Language Models! 🎬🦙
Check it out:
📄 Paper: https://t.co/1KhPsgZYUN
🔗 Project: https://t.co/68GevYyznx
💻 Code: https://t.co/MysWVlewRm
🤗 Demo: https://t.co/zKmL6v3PKU
Cuneiform at #ICLR2025! ProtoSnap finds the configuration of wedges in scanned cuneiform signs for downstream applications like OCR. A new tool for understanding the ancient world!
https://t.co/cfFvTu9U0G
h/t Rachel Mikulinsky @ShGordin@ElorHadar and all collaborators.
🧵👇
We are pleased to announce our next seminar by @RaphaelBaena (@ImagineEnpc, École des Ponts ParisTech) entitled "A General Framework for Text Line Detection and Recognition" on Friday 15/11/2024 at 11am CET. Details➡️https://t.co/HT1dKK52Dd
Our CvT-13 (~20M) encoder, trained on Xeno-Canto for 300 epochs with ProtoCLR loss, is now available on Hugging Face! Use it to extract informative features for your bioacoustic applications.
Check it out: https://t.co/386D4fsf4u
Bel article dans Le Figaro sur l'#IA pour l'étude de l'histoire de la langue française avec le projet #Himanis, un pionnier dans l'utilisation de la reconnaissance d'écriture manuscrite #HTR aux @ArchivesnatFr avec l'@IRHT_CNRS https://t.co/cqpqFHyFuX
This year at VISART @eccvconf, we have organised a fantastic panel session with Amanda Wasielewski (@awasielewski) moderating a panel of Olga Russakovsky (@orussakovsky), Augustus E. Wendell (@AEWendell) and Mathieu Aubry discussing all things #Art and #ComputerVision on Monday!
🚀Thrilled to share that our paper has been accepted at #NeurIPS🎉 We focus on detecting & recognizing characters in both printed and handwritten text (HTR) across Latin, Chinese, and ciphered scripts.
w/ @SyrineKalleli6, Mathieu Aubry
https://t.co/DtKiewCOBD #NeurIPS2024#HTR
The Learnable Typewriter
A Generative Approach to Text Analysis
w/ @NicaoGr@jgaubil@t_monnier and Mathieu Aubry
⭐️ won the best paper award at #ICDAR24
https://t.co/jUHXjS4BYN
An Interpretable Deep Learning Approach for Morphological Script Type Analysis (#IWCP 2024)
w/@YSiglidis@Himanis6 and Mathieu Aubry
📜🔡📊 https://t.co/U9XZRo2RiY
Join us for our talk in Athens // session II Parthenon I (11:15-13:15) https://t.co/gayZAnRMgc
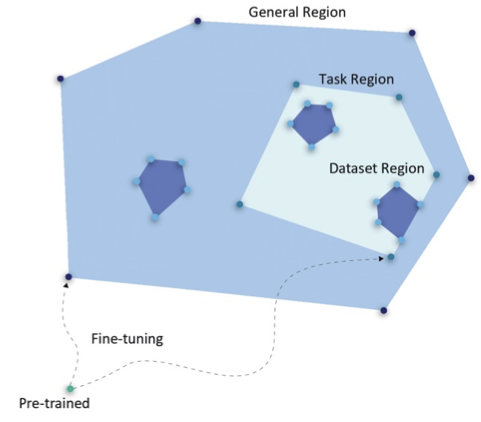
Finetuning millions of dimensions is not as complex as you may think🤯
Actually, it is quite interpretable in Euclidean space by
angles from the pretraining.
Seeds fall in small regions
Tasks in larger ones
All in some direction
https://t.co/OH1vi1AnZT
More is Better in Modern Machine Learning: when Infinite Overparameterization is Optimal and Overfitting is Obligatory. (arXiv:2311.14646v1 [cs.LG]) https://t.co/f2guypw2B0