🎉The Flexibility Trap has been accepted as an ICML 2026 Oral paper (168 out of 23,198)! Huge thanks to my coauthors, especially @ZanlinNi1 and @YangYue_THU.
In this work, we bring the token-entropy-based CoT analysis from Beyond the 80/20 Rule into the dLLM setting.
We find that “arbitrary-order generation,” long viewed as a key advantage of dLLMs, does not necessarily expand the solution space on general reasoning tasks such as math and code. Instead, it may allow the model to skip over high-entropy yet crucial logical branching points, effectively “locking” its reasoning potential.
Based on this finding, we propose a simple method, JustGRPO: train the model in an AR manner, and then enable parallel decoding at inference time. This improves performance while preserving the high decoding speed of dLLMs.
Recently, some friends mentioned that the “keep only the top 20% high-entropy tokens” method proposed in Beyond the 80/20 Rule may not be very robust in some RL settings. My view is that Beyond the 80/20 Rule was trying to highlight an important principle at a time when most analyses focused on overall entropy loss:
When analyzing CoT, we should also take a token-level entropy perspective and treat high- and low-entropy tokens differently. High-entropy tokens tend to determine the direction of reasoning, while low-entropy tokens help complete the reasoning content.
The “keep 20% high-entropy tokens” method in the 80/20 paper was just a simple proof of concept, a deliberately crude way to show that even a straightforward application of this principle can bring significant gains. Of course, this principle can inspire more elegant methods in future work.
The Flexibility Trap is one such example: it applies this principle to a broader setting in a simple and elegant way, and we are very happy to see it recognized as an Oral paper 😎
One small regret is that Beyond the 80/20 Rule also received fairly high NeurIPS scores at the time, but was not selected as a Spotlight. Still, one year later, it is now approaching 500 citations 😆
Please check out our work! I hope token-level entropy analysis can continue to be explored and developed across more areas.
The Flexibility Trap: https://t.co/hZxuJGbbb4
Beyond the 80/20 Rule: https://t.co/Tjxe7g4SYZ
Actually my advisor asked me to do that. But feature concat in densenet is not suitable for transformer, naively dense accumulation confuses different level feature. My advisor and me both got stuck and had no idea. Really appreciate this work
When ViT appeared back in 2021, many had been trying to make dense Transformer to reproduce the success of DenseNet. But most of them failed, including my advisor, the author of densenet. It turns out articulating transformer's residual stream has much more nuances. Great work
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
Do diffusion models produce novel data points, or reproduce the training data they see? What factors drive this?
In a new paper, we study this problem in the 3D generation context.
We propose an evaluation framework to quantify memorization in 3D shape generative models. We evaluate existing 3D generators and run controlled experiments to investigate what drives memorization and how to reduce it.
Our paper, Does reinforcement learning really incentivize reasoning capacity beyond base model, has just won the Best Paper Runner Up in #NeurIPS2025!
Really honored the idea and insight are recognized, and will stick with relevant and fundamental research. See you in San Diego!
@ChaseBrowe32432 It is possible that at a larger scale or with better techniques, the reinforcement learning can make model perform better. But this is not why reasoning LLM works for now.
@ChaseBrowe32432 thanks for your feedback. After all, reinforcement learning is all about improving the sample efficiency. What we mainly want to argue is that for current paradigm which use grpo or ppo optimizing base model for hundred steps, It mainly works by eliciting instead of improving
@ChaseBrowe32432 Also we manually checked the trajectory generated by the base model. It does not perform like random guessing. The answers are restricted in a very small set and include the right answer. But the probability of generating this correct answer is quite low
@ChaseBrowe32432 as the author of this paper, I want to politely point out that there are many other benchmarks that has answers beyond 0-1000 which are hard to guess. Not to mention coding benchmarks that passing the test means solving the problem. All show the same result
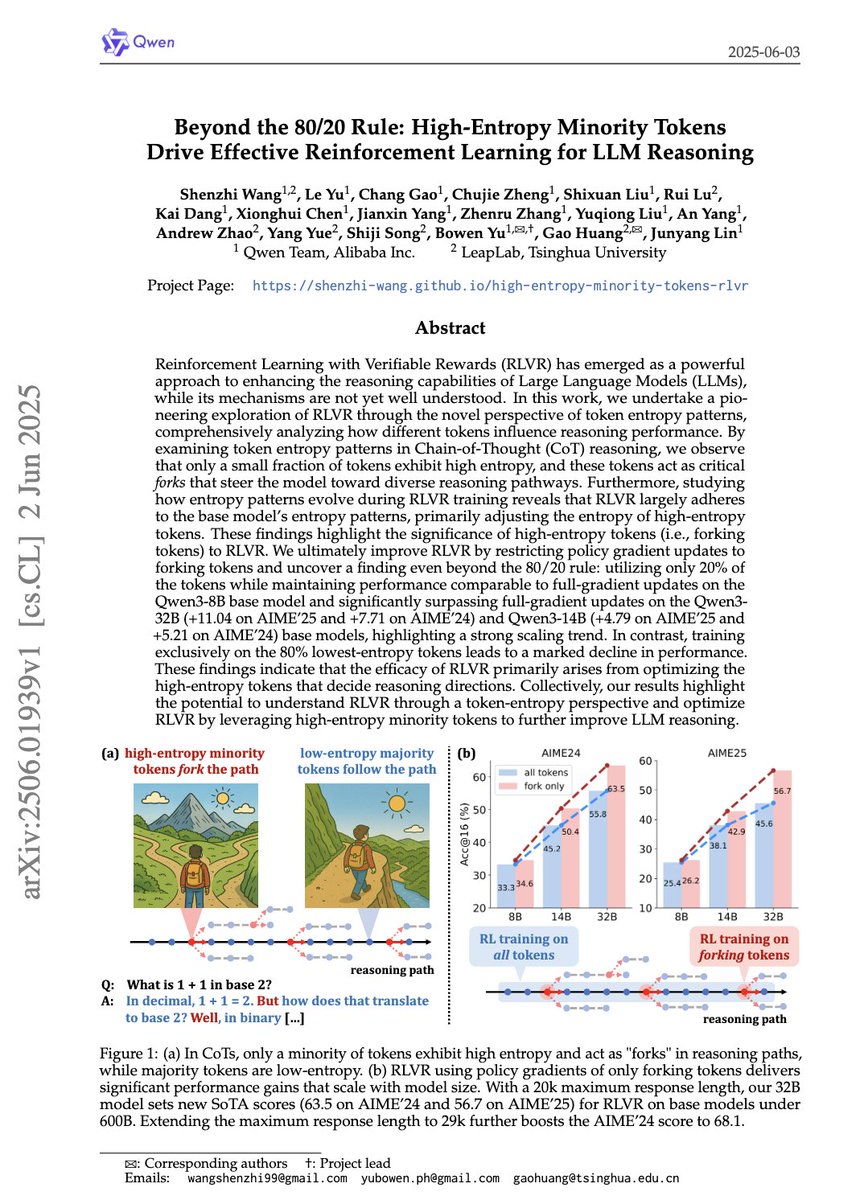
How does reasoning model actually reason? Our recent study shows that only 20% tokens with the high entropy play a critical role in deciding the reasoning trajectory! Check us out
The GAIA game is over, and Alita is the final answer.
Alita takes the top spot in GAIA, outperforming OpenAI Deep Research and Manus.
Many general-purpose agents rely heavily on large-scale, manually predefined tools and workflows. However, we believe that for general AI assistants:
"Simplicity is the ultimate sophistication."
🔗Full paper: https://t.co/KoApMuFGFj
🔗More Details will be updated here: https://t.co/uGH3PHFbnG
#AI #Agent #LLM