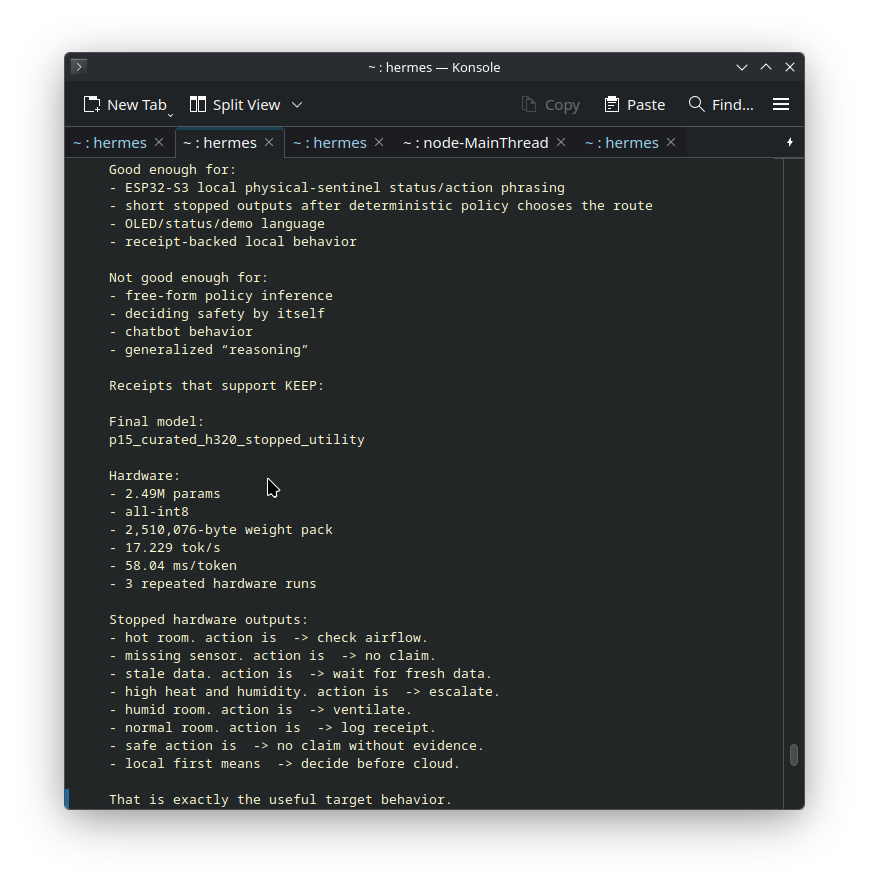
I'm getting 17 tok/s from a 2.5M parameter model on an esp32s3 micro-controller with my custom inference engine and my way of scoring and reading from still compressed kv cache which drastically drops cpu usage, which in turn allows me to put more into inference. This blows the previous record completely out of the water. guy got 2 tok/s on a ~250k parameter model. Not only that, but it opens up lots of on device ai options that were never possible before. This is on a $4 chip from amazon btw.
Yup, that's what I do. I just built a custom kv cache compression that allows scoring and recalling from the still compressed cache. Built the custom scorer and everything. It's about to give everyone a 4x speed increase along with a few more things to esp32/esp32s3. I have a 6.5 million parameter model running at 2 tok/s on it with the model only using 4.5MB. All with gpt 5.5 and my custom Hermes agent.
Using what I learned working on all the quantization crates I have and building my stack, I built an advanced context compactor that does a better job and does it a lot faster. Combine this with my semantic memory and you get a meaningfully upgraded agent beyond most.
my memory system is 66-100x faster at retrieval than Zep, all while achieving higher quality retrieval as well. Nothing else even comes close. sub-ms simple top5 retrieval. 3ms advanced graph traversal. It allows you to rely heavily on the memory without performance cost.
Check out https://t.co/s7Wl3klrwc, please @NousResearch, as it will help transform any agent into a next Gen learning machine, fully local and it beats any other agent memory in features and retrieval quality, not necessarily speed, but it's in the 20-130ms range for most skills. I've poured over 6 months into the project this is from and the crate it wraps is very mature. I use it and couldn't live without anymore.
Benchmarks of semantic-memory-mcp. For a local-first database, i'm quite happy with how things are developing. I may even have a big upgrade for database size soon that shrinks it both on disk and in ram dramatically.
Short demo of the autonomous closed-loop learning built with AiDENs. requires no human intervention, but you can give it goals if you like, otherwise it finds gaps in its knowledge and figures it out itself. you can see information about the runs at https://t.co/0u4o18TLaA
I'll be dropping some demos of AiDENs later on. This is the first impressive thing i've done with it. It's done and a thing to behold. It could infinitely run and learn if i could afford the usage, lol. The greatest part about it is everything, every crate is modular and able to work with any other. @anthropicai i know this is something you are interested in and I had to wait until my memory system was mature enough to handle it. Fully autonomous, closed-loop learning system. You can give it a goal to work toward or let it figure out what to do on its own.
I'm building the entire ai ecosystem in rust for speed, memory savings, reliability and determinism not easily achieved in other languages. i've shipped a fully local memory system that has every feature all the competitors have, plus a whole lot more. it's part of my stack, but most useful as is. next-gen is the idea. https://t.co/bufwxCGcMo
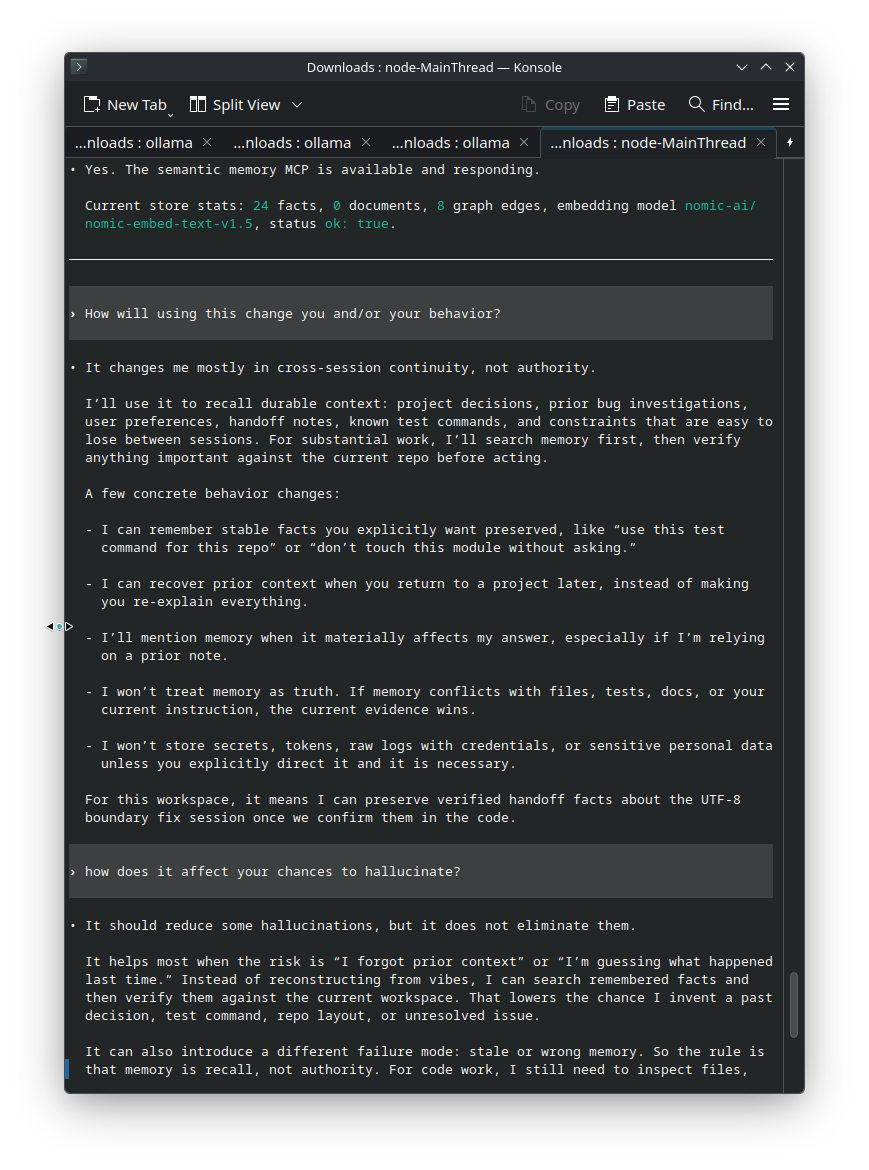
my memory system has become flawless in integration for @ClaudeDevs (claude code) @OpenAIDevs (codex), @NousResearch (hermes) and more. it transforms them from stateless into not making the same mistake twice, being able to learn and forget. all the latest on git. easy install.
@dmkai98@karpathy They do with actual memory. I wrote an agent agnostic advanced semantic-memory system that's fully local, no cloud embedding or vector database. It's much more advanced than RAG. the readme isn't fully updated with all the features. https://t.co/qJZ5lwchJs
https://t.co/CKLa62meRm
This is a plugin for claude code that automatically installs and sets up semantic-memory so claude never forgets anything relevant ever again. Also comes with repo ingestion commands to automatically populate the database with relevant info for easy start