OpenAI may secretly know that you trained on GPT outputs!
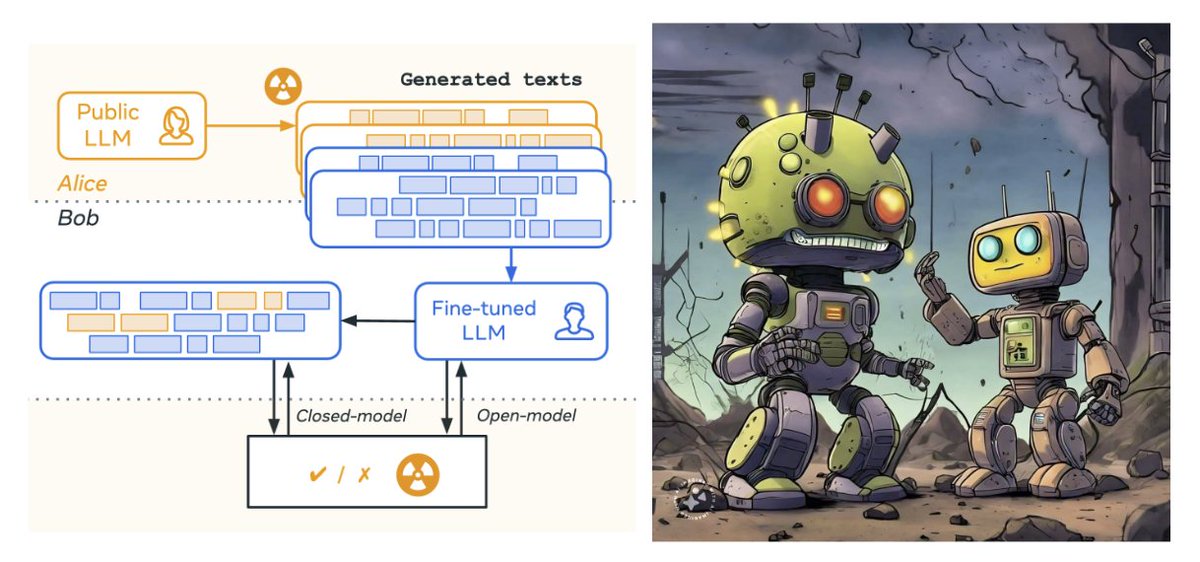
In our work "Watermarking Makes Language Models Radioactive", we show that training on watermarked text can be easily spotted ☢️
Paper: https://t.co/EETij4oLF0
@pierrefdz@AIatMeta@Polytechnique@Inria
1/9 Excited to share TextSeal, our new state-of-the-art watermark for large language models at FAIR / Meta Superintelligence Labs (@AIatMeta) 🔐
Paper: https://t.co/XMJ1nYrEQF
Code: https://t.co/PAZygG69me
9/9 Beyond provenance, TextSeal is “radioactive”: its signal can transfer through model distillation, helping detect when another model was trained on watermarked outputs.
Try it out! Code is Apache 2.0.
Paper: https://t.co/0xRfv0xFFZ Code: https://t.co/PAZygG69me
1/9 Excited to share TextSeal, our new state-of-the-art watermark for large language models at FAIR / Meta Superintelligence Labs (@AIatMeta) 🔐
Paper: https://t.co/XMJ1nYrEQF
Code: https://t.co/PAZygG69me
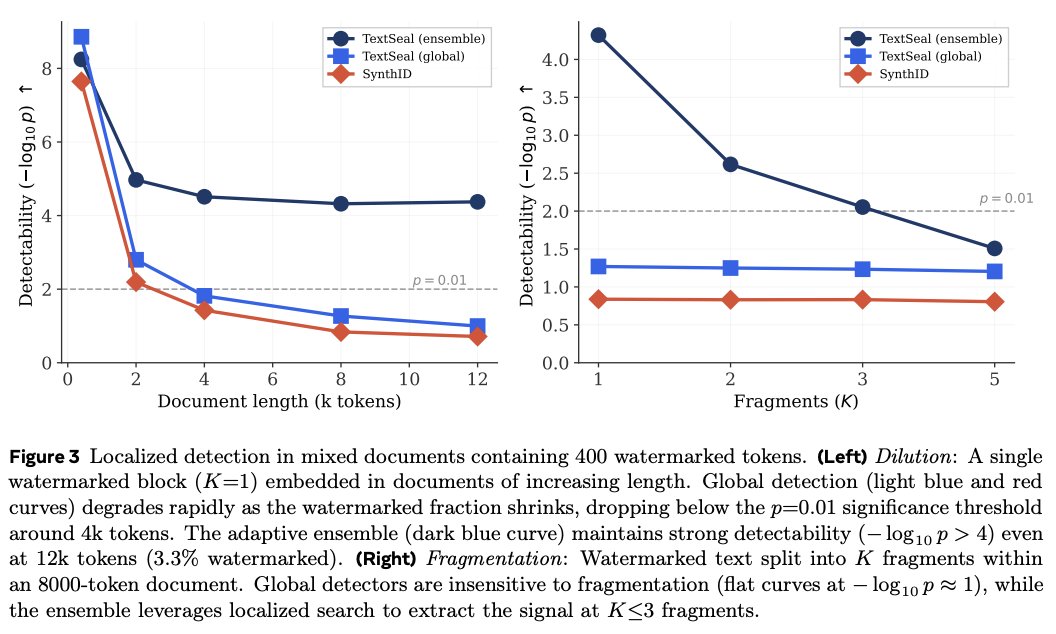
8/9 Novelty 3: fast localized detection.
Real documents are often mixed: some human text, some AI-generated text.
TextSeal searches for watermarked regions (previous figure), so detection remains strong even when the signal is diluted (results here)🧭
A sincere thank you to my thesis committee, my brilliant colleagues at FAIR and Polytechnique, and everyone who has encouraged me along the way. 🚀 https://t.co/6NZGVQ3JzR
Delighted to share that last month, I successfully defended my Ph.D. in Mathematics! 🎓
Huge thanks to my incredible advisors, Chuan Guo at @MetaAI (FAIR) and Alain Durmus at @Polytechnique, for their phenomenal mentorship and support throughout this journey.
My research focuses on the intersection of machine learning and security, specifically Privacy, Traceability, Provenance and Watermarking in Deep Learning. It has been incredibly rewarding to work on making AI models more secure, transparent and accountable.
A couple of months after OmniASR, we’re excited to release OmniSONAR alongside OmniMT. OmniSONAR brings new training recipes for cross-lingual and cross-modal sentence encoders, enabling massively multilingual embeddings for text and speech. https://t.co/ZhkJjC9GBI
🧵 1/3
with the usual suspect @pierrefdz and the rest of the AVSeal Team!
We’ve released our code, and are part of the Meta Seal release!
Check out the full paper
📄 Paper: https://t.co/Ajuoxv0Wji
Website: https://t.co/XMEW39wb48
💻 Code: https://t.co/PAZygG69me
Most text watermarking methods focus on generation time. But what about existing text?
We explore "Post-Hoc Watermarking," using an LLM to rephrase and watermark copyrighted books, training data, or similar content. 🧵
https://t.co/Ajuoxv0Wji
https://t.co/PAZygG69me
Why does this matter?
"Watermark Radioactivity."
If we watermark specific documents post-hoc, we can detect if they are used to train future models or retrieved in RAG systems. It turns passive data into active tracers.