Our team’s opinion after the recent AI discourse is pretty simple: frontier AI is moving fast, but no one should use a scaling curve to dictate the research pace for everyone else.
Given the state of machine learning as a whole, no one has a license to act like the core problems behind AGI, RSI, or ASI are close to solved.
The more sober view, in our opinion, is that we are moving out of a pure scaling era and back into a research era as Sutskever or Le Cun say. Scaling gave the field a lot. No serious person should dismiss that, and no one serious should be saying “stop scaling” or “stop frontier research.” But current systems still fall short in ways that matter: they can be brittle, they struggle under distribution shift, they do not learn continuously the way humans do, and they still lack the kind of grounded, reusable understanding that transfers reliably across very different contexts.
This is why no one should be dictating the pace of research as if the hard part is already behind us. There is still a massive amount of research left to do.
Sutskever’s “finite data” point is important because it cuts deeper than just “we need more data.” It points to the limits of relying on internet-scale pre-training as the main engine of progress. At some point, the question becomes how systems generalize, how they learn efficiently from limited signals, and whether the learning mechanisms themselves are enough.
The original “world model” crowd (May the meaning of this terminology rest in peace alongside “memory”) says that it’s not just that LLMs have flaws but that intelligence requires machinery for world models, grounding, memory, planning, and prediction in latent space. A system can be very good at modeling language while still missing the structures needed to understand and act in the world.
If clean data, feedback, and training signals were effectively unlimited, distillation and model-extraction attacks would not be such a major strategic concern. The fact that frontier capability itself becomes something others try to copy is a reminder that learned competence is scarce. It also suggests that the main mechanisms LLMs currently rely on to improve may be far from sufficient to reach super-intelligence or efficient learning.
These opinions are more AI-friendly than anything. Looking forward to progress across many areas, while giving the big labs real credit for what they have achieved in language, code is far more positive for the field than pretending we are already close to AGI or ASI when we clearly are not there yet.
And while we are not there yet, the large influx of serious STEM talent into AI is unbelievably good for the industry. Researchers from across math, physics, biology, engineering, and the rest of science are increasingly taking AI seriously, building with it, testing it, and bringing their own standards into the field. That should be celebrated as it means AI is attracting the kind of people needed to solve the rest of the problems.
Domains that are not compatible with prose strengthen the main point. A model can be excellent at language, code, and digital workflows while still being far from robust general intelligence. Physical prediction, causality, affordances, action-conditioned planning, and reasoning across long time horizons are still hard problems.
So yes, today’s models may reshape coding, security, science workflows, and other areas. That is very real indeed but it does not mean we already have the a perfect recipe for autonomy, alignment, continual learning, causal understanding, grounded world models, or reliable long-horizon reasoning.
The public conversation would be much healthier if it could hold both ideas at once: frontier models are good while there is still a lot left to do on all angles.
It’s hard to disagree with the direction of this. But it’s worth being honest that the neuro-symbolic lineage lost to scale for most of the last decade.
At the surface, everything collapses into prose. Fluent text is a poor record of what produced it. Two systems doing completely different work underneath can return the same paragraph. Whether anything symbolic is happening has to be answered below the language layer and not in the prose.
LLMs are excellent at prose, and they’ll remain relevant in that era. But prose is not the thing to lean on once a task needs real adaptation, verification, planning, or abstraction.
The lineage has been kept alive in places with DeepMind’s theorem-proving work among them and it’s finally starting to look right again.
Three Predictions:
1. Some form of AI, probably neurosymbolic in nature, will come that is far more economical and data- and energy-efficient than LLMs, and it will make an absolute fortune.
2. LLMs, on the other hand, will never be all that profitable (aside from the chip companies selling shovels in the gold rush).
3. Today’s gigantic bets are premature, and most won’t pay off.
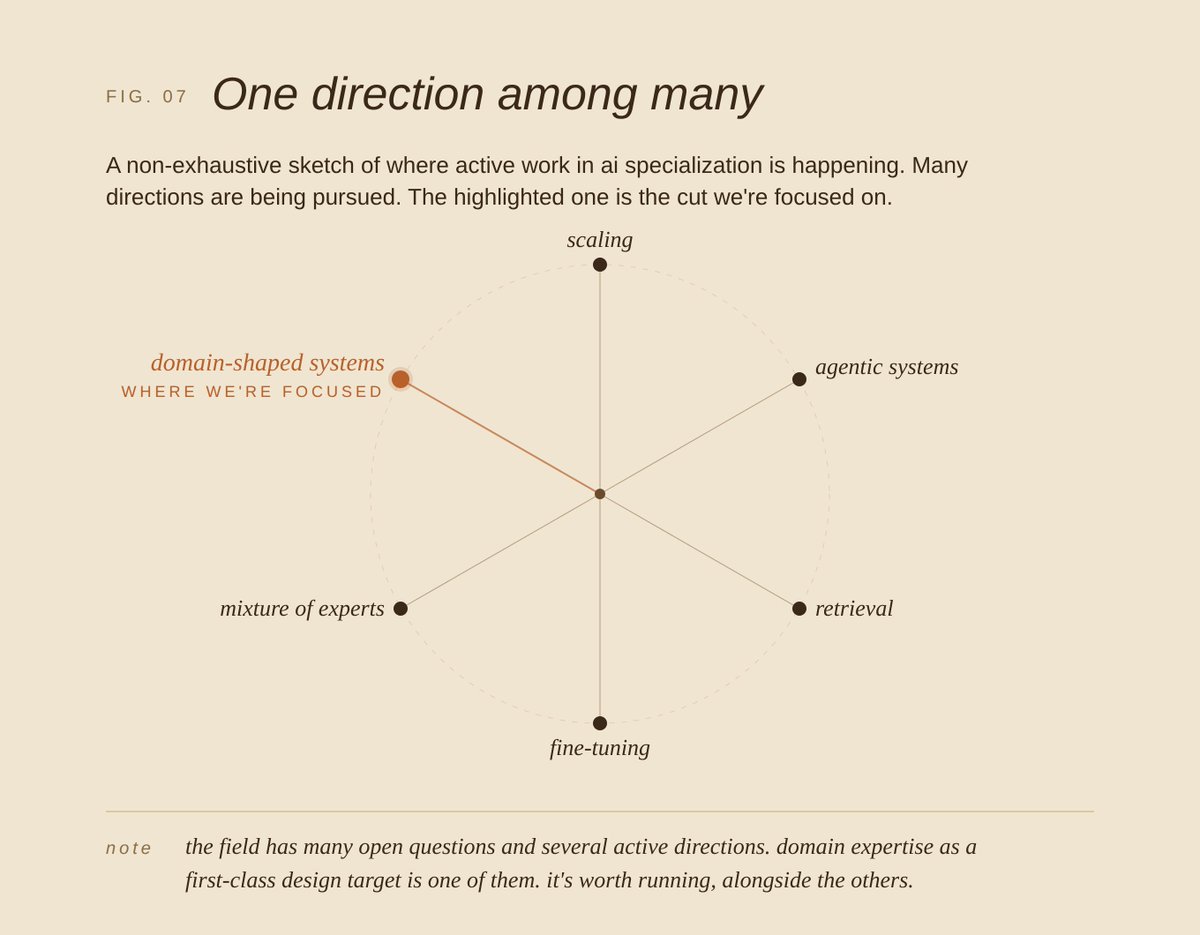
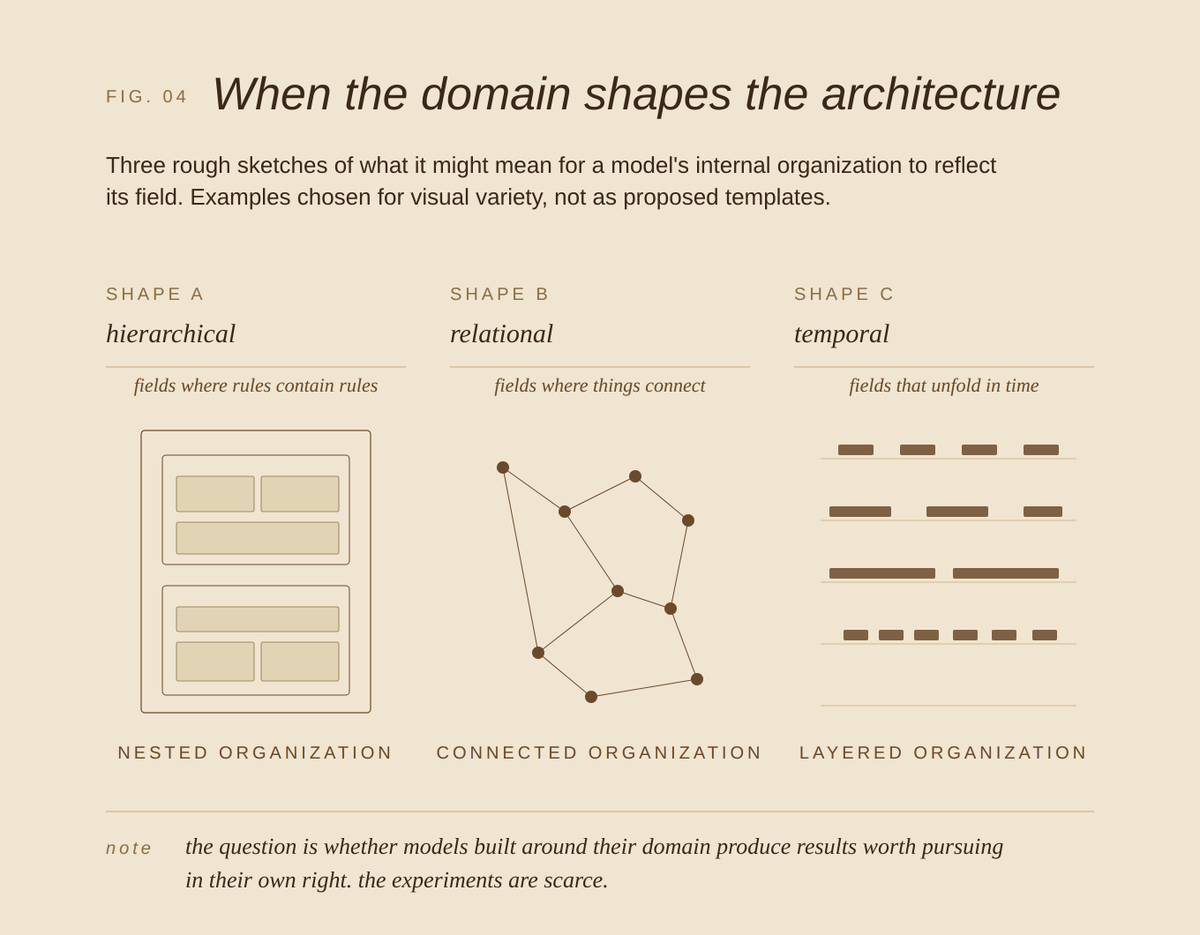
This isn't a claim that generalism is wrong. Labs are running scale, agents, training innovations, any could be the path. Domain expertise as a first-class design target is the cut we find most underexplored and the one we're running.
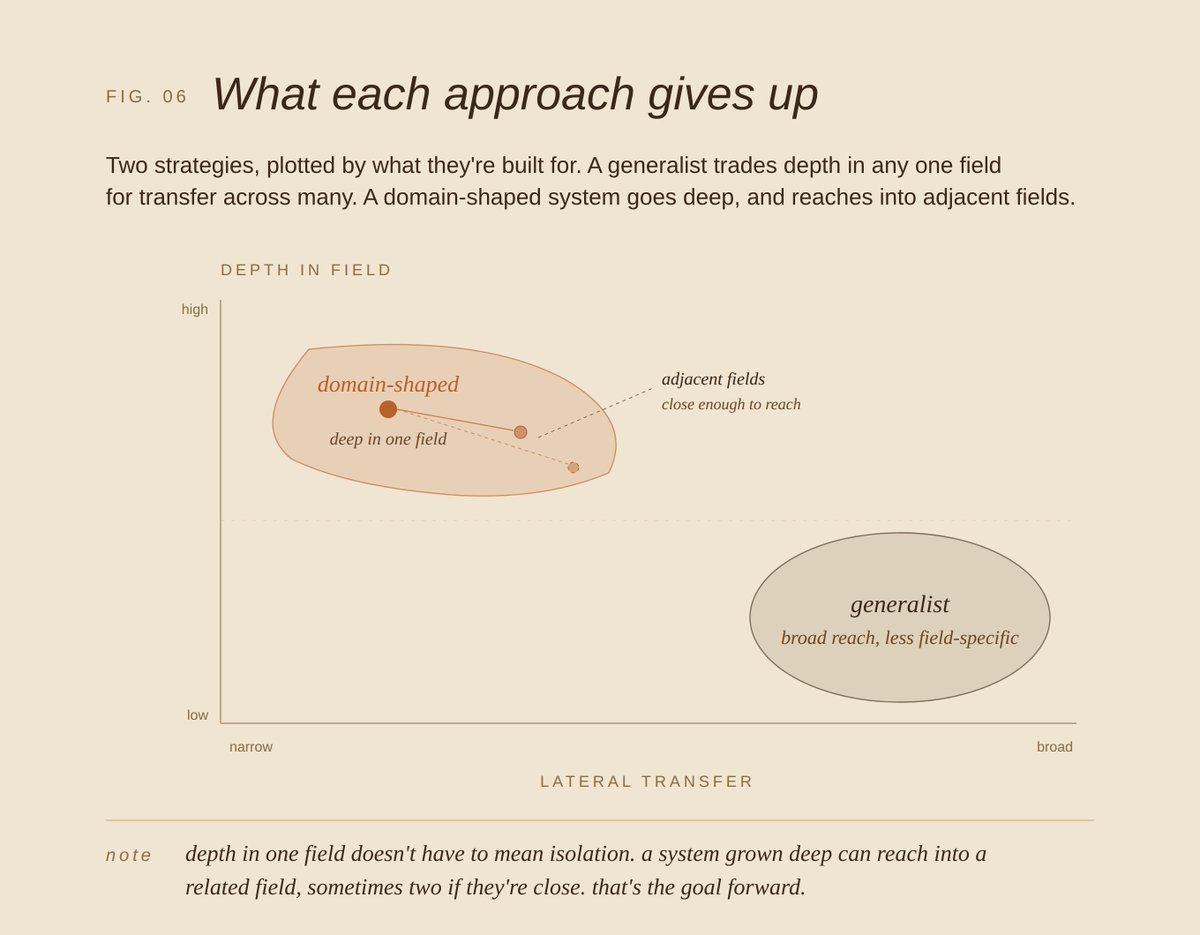
This isn't arguing for narrow over broad. Transfer and lateral moves matter but domain expertise has been underweighted as a design input. The goal isn't isolation. A system built deep in one field can reach into a related one or even two without losing what the depth bought.
As part of security measures, Code Sandbox will be replaced by our API endpoints until further notice.
Code Sandbox was shipped in closed beta as an experimental product, a first proof of work validating that reasoning and learning can persist independently of the model used for articulation. Thank you to everyone who tested and shared feedback.
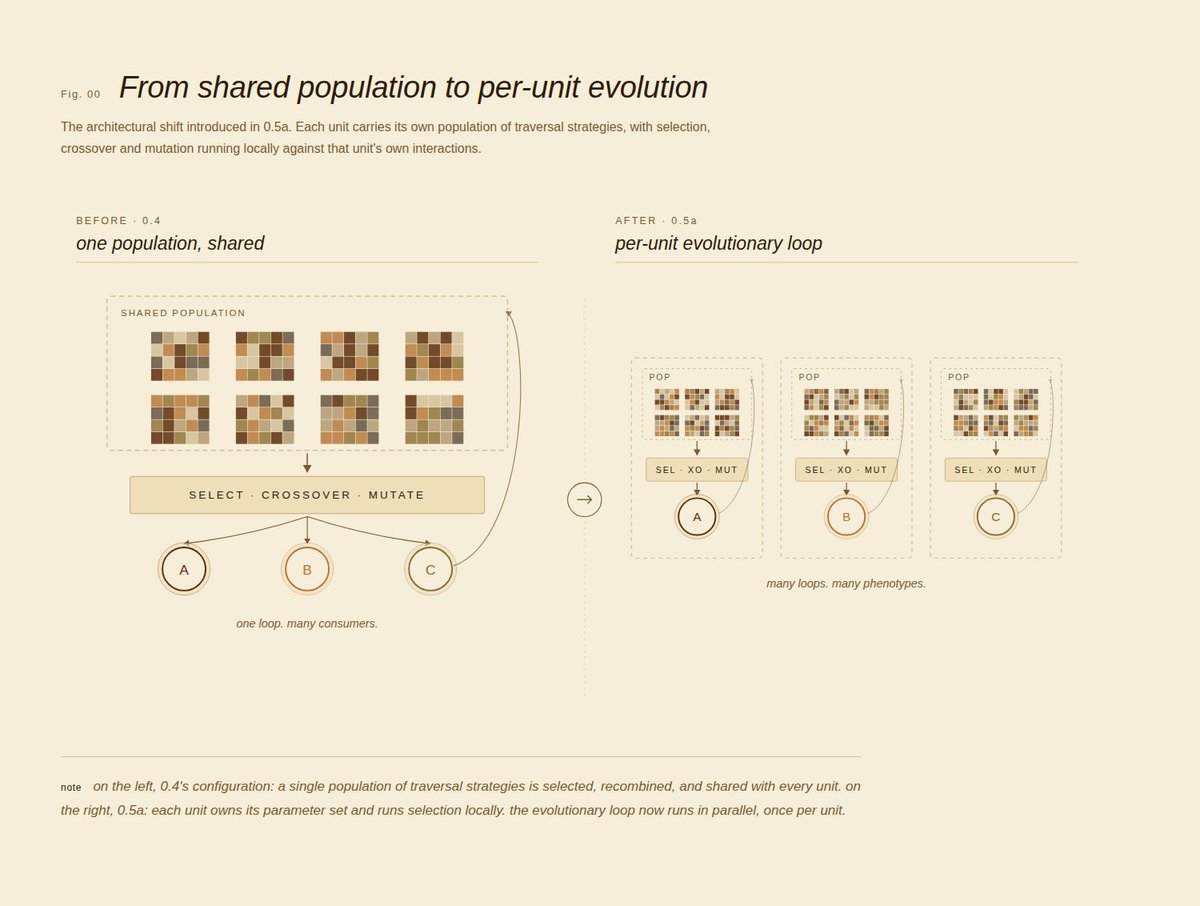
Quick context on why GAs will become more relevant in ML as time goes.
Gradient descent takes a fixed structure and tunes the values inside it. the architecture is set at design time and never moves, training gives you better numbers inside the same reasoner you started with.
Genetic algorithms in core operate on the structure itself. patterns form, link up, recombine, or decay under feedback. gradient descent can't do that, discrete structural change need work on structures directly.
Think of it as a software attempt to mimic brain plasticity. reasoning develops instead of staying fixed, two instances exposed to different feedback end up with different shapes, not just different weights and that's why it's interesting with plenty of room for exploration.
0.5a is live on Rei chat and the Rei Unit API. The figures in this thread describe the behavior of the running system. Make sure to create new Units as only fresh Units pick up 0.5a's evolution logic from the start.
Diversity here is the spread across the current population's parameter values. Once that spread crosses the threshold, the next population spawns from the survivors. Top performers carry forward as the seed, then crossover and mutation fill out the new generation.