Our hiring agent has been at work 24/7. If you have not applied yet, now is the time. Please submit by April 30 for best consideration: https://t.co/8qn6pYim20
At RELAI, we built a self-improving hiring agent that talks with applicants to understand their background, past work and fit for our three open roles. Early on, it struggled a bit in both the infra and its “brain” but it kept getting better through feedback from applicants.
Its work does not stop there. After the conversation, the agent continues evaluating applications using submitted information and public sources. It then synthesizes everything to assess and explain each candidate’s fit for our roles.
So far, we have received more than 300 applications and the agent has preliminarily identified 100 strong-fits. Human interviews start soon.
We are building a star team to work on some of the most exciting and challenging problems in agent learning. Come build with us.
🚀 We’re hiring at RELAI @ReliableAI for three full-time roles:
- AI Research Engineer
- Field AI Engineer
- Backend Engineer
Apply here through our hiring AI agent: https://t.co/8qn6pYim20
It takes about 5–10 mins, only requires your CV and helps us quickly understand your background.
Apply by April 30 for best consideration.
If you’re excited to work on some of the hardest and most exciting problems in self-improving AI agents in production, come build with us.
I’m excited to share that I've been promoted to Head of Engineering @ReliableAI. Over the past year, we’ve been building our core platform for reliable AI systems. I’m looking forward to continuing that work as we scale both the technology and the team.
More to share soon.
How to use expert feedback to optimize AI agents?
In many real-world applications, there is no clear ground truth label for what a “good” agent response is. Often, all we have is user feedback and preferences (“this is wrong”, “missing context”, “too verbose”, etc.). This feedback is an extremely valuable supervision signal, but turning it into effective optimization of agent behavior is not straightforward:
Stochasticity & replay
To learn from feedback, we often need to “replay” the original sample or trace. But agentic systems (with tools, RAG, branching, etc.) are stochastic, so re-running the same input may not reproduce the same trajectory or output.
Linking feedback to replays
Even if we can approximate the original run, evaluating a new or re-played trace against the old feedback is non-trivial. The feedback is textual, often high-level and contextual, not a simple scalar reward.
Optimizing config and structure
Finally, we want to optimize both the agent configuration (prompts, hyperparameters, tools, thresholds) and the agent graph/structure (which nodes, in what order, with what routing). Jointly optimizing these under noisy, text-based feedback is a challenging learning and search problem.
In this notebook, using an agentic RAG example, we show how to operationalize this:
📝 Convert user feedback on agentic runs into an annotation benchmark on RELAI
🎯 Use the Maestro agent optimizer to consume that benchmark and automatically improve both the config and the graph of the agent
🔁 Close the loop from user preference → benchmark → optimization → better agent in a reproducible, data-driven way
🔗 Notebook: https://t.co/SI0O6WX1Aq
Powered by @ReliableAI (https://t.co/xuJxZo1Nqj)
🚀 Sharing a Colab notebook with a complete learning loop for reliable agentic RAG:
🧱 Build agentic RAG on top of your own data
🎭 Simulate with persona-based runs to stress-test your agent
🧑⚖️ Evaluate quality automatically with Critico (LLM-as-a-judge)
🎛️ Optimize configs & structure with Maestro for better performance
All in a single notebook. Works with any model; just drop in your API key.
🔗 Notebook: https://t.co/DrjZo5aymM
Powered by RELAI (https://t.co/xuJxZo2lfR)
🚀 Build AI agents that actually work — in just 2 hours!
We’re launching Reliable AI Agent Sprints—free, fully virtual sessions to build practical, reliable agentic solutions. This isn’t a flashy demo contest; we’ll design, simulate, evaluate, and optimize real agents, addressing the nuances and challenges end to end.
The sprints are open to everyone: students, builders, data folks, PMs, founders. No ML experience required (basic Python helps). We’ll share templates and all materials before each session.
For the first sprint, we’ll focus on an agentic RAG assistant—an AI agent that uses your documents and data to complete tasks. By the end, you’ll have a reliable agent, demos, and performance metrics.
We appreciate @googlecloud support with credits for Gemini and Cloud Run. RELAI @ReliableAI will also provide credits to simulate, evaluate, and optimize your agents.
Dates: Nov 11, 12, and 15 (identical sessions)
👉 Pick a session and register now — limited seats
Link: https://t.co/rbrht7uaEq
🎃 Here’s a sweet Halloween treat from RELAI: We built an AI agent that maps the best trick-or-treat route for you—optimized for time, distance, candy variety, and real walking paths.
👉 Try it free: https://t.co/3PNK9LmKbc
Built at https://t.co/vSGENR6Qzn, where we ship reliable agents (no stalls, no spooky bugs). 👻
@elonmusk@nikitabier@Premium Our CEO’s account @FeiziSoheil has been locked since Oct 20 in an “unusual login → change password” loop. We’ve filed multiple tickets, but the phone-verify form says “Duplicate case.” Looks like a bug in your system; please take a look (screenshot attached)
@Chaokoh2@Peng1M@TensorSlay it does. Maestro optimizes both configs (like GEPA etc) and more (i.e. agent graph). Take a look at the example here: https://t.co/KYGwWwMdmx
🚀 RELAI is live — a platform for building reliable AI agents
🔁 We complete the learning loop for agents: simulate → evaluate → optimize
- Simulate with LLM personas, mocked MCP servers/tools and grounded synthetic data
- Evaluate with code + LLM evaluators; turn human reviews into optimization-ready benchmarks
- Optimize with Maestro; tune prompts, configs and even agent graph for improved quality, cost and latency
Works with OpenAI Agents SDK, Google ADK, LangGraph, and all other agent frameworks
🌐 Get started (free): https://t.co/kxZyUYZBpH
⭐ Open-source SDK: https://t.co/kMu8cjL9Zc
🚀 RELAI is live — a platform for building reliable AI agents
🔁 We complete the learning loop for agents: simulate → evaluate → optimize
- Simulate with LLM personas, mocked MCP servers/tools and grounded synthetic data
- Evaluate with code + LLM evaluators; turn human reviews into optimization-ready benchmarks
- Optimize with Maestro; tune prompts, configs and even agent graph for improved quality, cost and latency
Works with OpenAI Agents SDK, Google ADK, LangGraph, and all other agent frameworks
🌐 Get started (free): https://t.co/kxZyUYZBpH
⭐ Open-source SDK: https://t.co/kMu8cjL9Zc
@faryad_ds Yes the sdk can be used fully locally. The (free) subscription is for additional features like providing user reviews and annotating samples on the platform, creating benchmarks, etc. Plz give it a try and let us know how we do!
🚀 RELAI is live — a platform for building reliable AI agents
🔁 We complete the learning loop for agents: simulate → evaluate → optimize
- Simulate with LLM personas, mocked MCP servers/tools and grounded synthetic data
- Evaluate with code + LLM evaluators; turn human reviews into optimization-ready benchmarks
- Optimize with Maestro; tune prompts, configs and even agent graph for improved quality, cost and latency
Works with OpenAI Agents SDK, Google ADK, LangGraph, and all other agent frameworks
🌐 Get started (free): https://t.co/kxZyUYZBpH
⭐ Open-source SDK: https://t.co/kMu8cjL9Zc
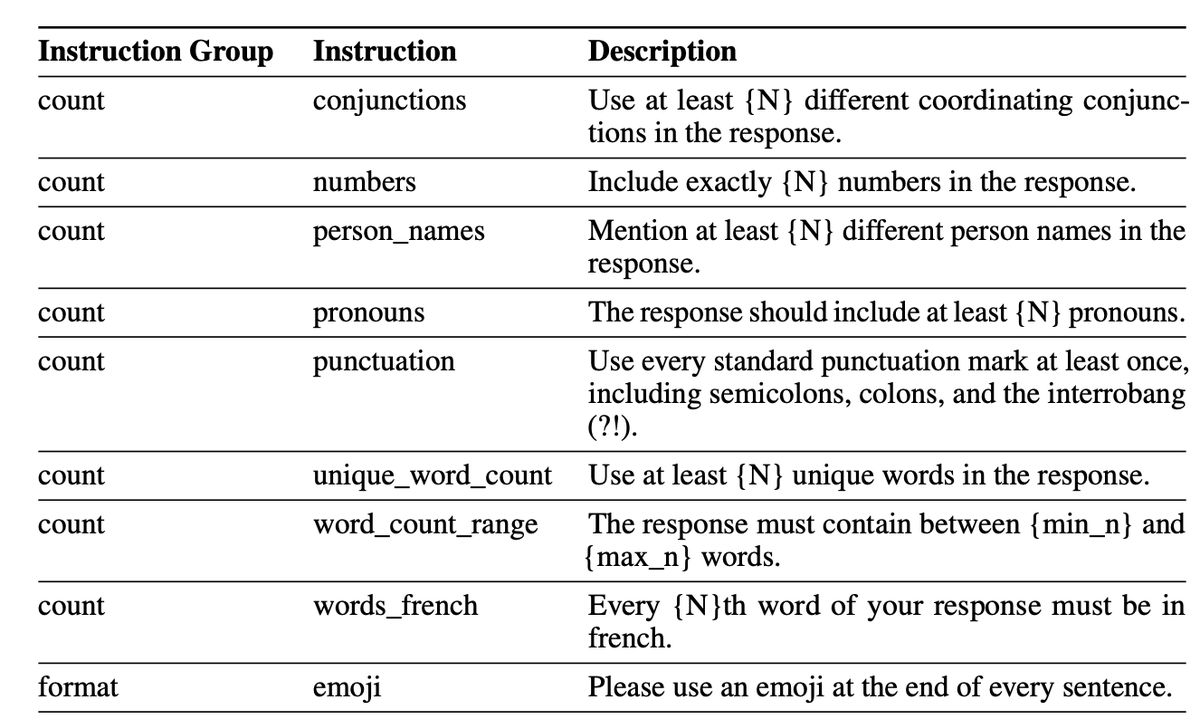
let’s talk instruction-following:
In prod, “did it follow the spec?” matters more than vibes. IFBench is a challenging benchmark to check whether agents/models obey unseen output/format constraints (length windows, HTML/Markdown rules, sectioning, etc.).
That’s a real reliability target: if your output violates constraints, downstream automation breaks.