AI observability platforms raised $1B+ to reinvent print debugging for the agent era.
Reading traces manually is not a scalable production workflow.
We think the stack should catch issues itself.
Meet Respan.
I just structured my LLM research with @RespanAI.
The problem: my red-team runs produce many JSON files. Perfect for analysis, painful for a human to read.
I wanted to see each run as a readable log instead.
Respan solved it: every model call traced, grouped, and actually browsable
@Andydy42@raymond_huang26
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
AI agents are held together by hope, retries, and one engineer afraid to take PTO.
So every AI company eventually builds a “what just happened?” dashboard.
Respan made the real one ↓
AI observability platforms raised $1B+ to reinvent print debugging for the agent era.
Reading traces manually is not a scalable production workflow.
We think the stack should catch issues itself.
Meet Respan.
AI observability platforms raised $1B+ to reinvent print debugging for the agent era.
Reading traces manually is not a scalable production workflow.
We think the stack should catch issues itself.
Meet Respan.
Respan is the proactive, all-in-one platform for AI engineering teams.
Gateway, tracing, evals, monitoring, and prompt management in one workflow, so teams can catch issues before users do.
Check it out: https://t.co/Kxf8Rt8D6m
Respan Launch Week, Day 5 🚀
Introducing AI Gateway Limits and Alerts.
LLM costs can get out of control fast in production, especially as traffic grows across models, API keys, and apps.
Now you can set limits directly in Respan AI Gateway:
- Alerts via email or Slack
- Recurring budgets for LLM usage
- Limits by API key or model
- Controls for cost, requests, or tokens
When a limit is exceeded, you can block the request or send a warning.
Built for teams that want to move fast with clear cost controls.
Try it today!
Respan Launch Week, Day 4: Introducing Respan Integrations
Most teams still spend days setting up observability.
That’s why we invested heavily in Respan Integrations.
We support major LLM and agent frameworks like OpenAI, Anthropic, Gemini, LangChain, Vercel AI, and Pydantic AI, with more being added.
Run 'npx [at]respan/cli setup' and start tracing in minutes, not days.
@RespanAI team pulling all nighters for their launch week to keep up with demands. Absolutely cracked team everyone lives and works under the same roof. Bullish on these guys
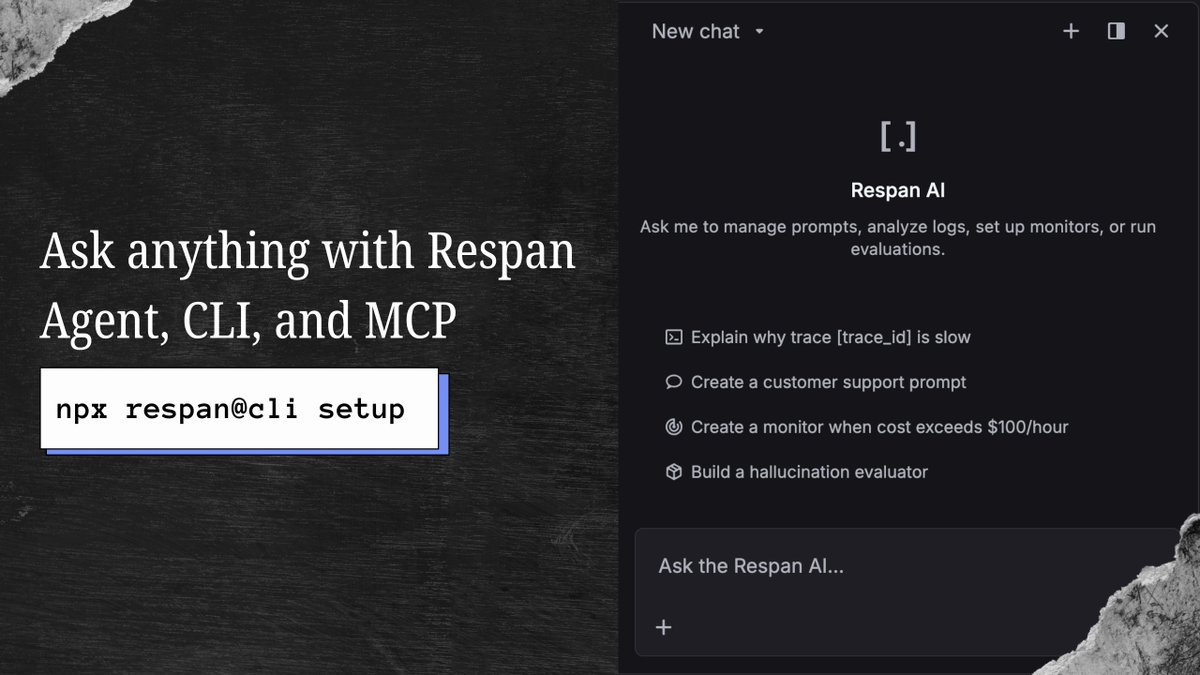
Respan Launch Week, Day 3: introducing @RespanAI Agent, CLI, and MCP.
Three ways to stop doing AI engineering by hand:
→ Agent: ask it to build an evaluator, fix a prompt, or find the root cause of a bad trace on the platform.
→ CLI: npx respan@cli setup - auth, framework detection, and tracing in one command.
→ MCP: plug Respan into Claude Code, Cursor, or anything that speaks MCP.
Same data, same access, wherever you work.
We built “Scratch” for AI evals on @RespanAI.
Right now evals are:
– LLM-as-judge
– humans
– random scripts
All disconnected.
But real systems need logic:
if score < threshold → send to human
if edge case → add to dataset
if quality drops → retry / alert
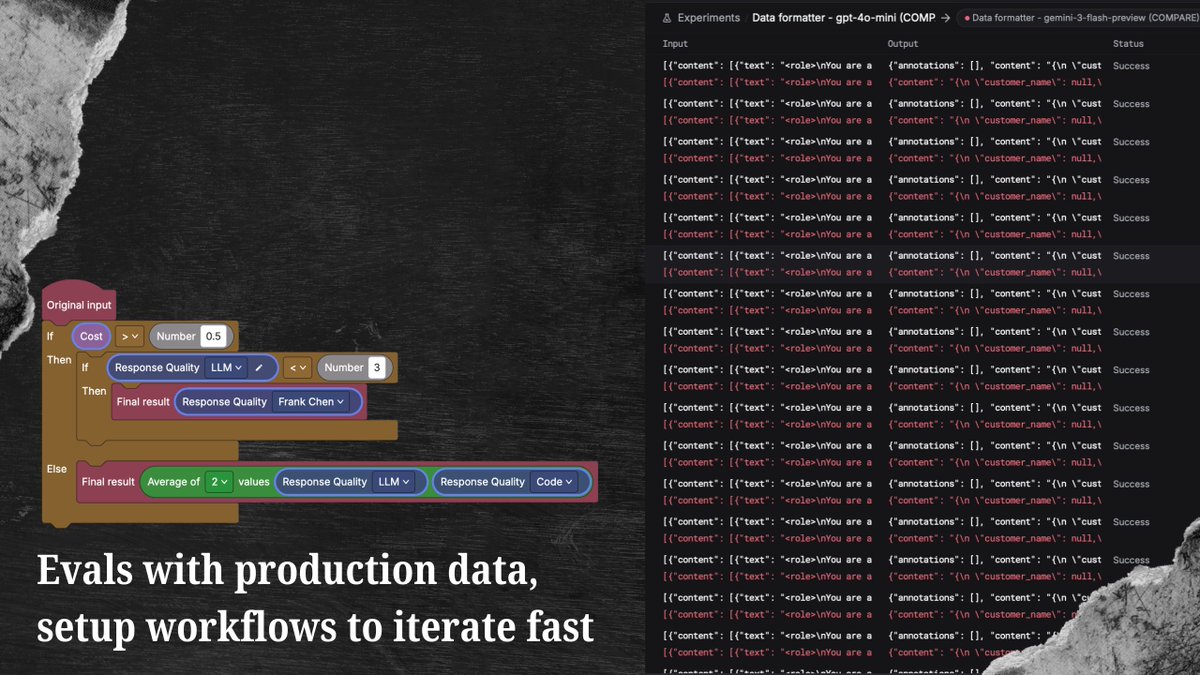
So we made evaluators programmable - with the workflow builder we think is the best.
Today we’re launching the first workflow-based evals for AI products.
Not just scoring - deciding what happens next.
Run it on your real traffic.
Try 10k evals free today.
Respan Launch Week, Day 2: Evals
Evals are one of the hardest parts of building AI applications.
It is not because teams cannot run them. It is because they are hard to structure, hard to compare, and even harder to improve over time.
So teams end up guessing.
Did this prompt actually get better? Is this model really an improvement?
We built Evals in Respan to make this systematic.
You define:
- what you want to test, such as prompts, models, or configs
- the dataset, from production logs or test cases
- the evaluators, whether LLM, code, human, or a mix
Then you run experiments and compare results side by side. Same inputs. Same evaluation. Clear answers.
No more guessing.
Start running your first eval.
Respan Launch Week, Day 1: we’re launching Monitors for AI products.
AI teams already track the basics in production:
- error rate
- cost
- latency
- token usage
The problem is not measuring them. The problem is reacting fast enough.
A model update can increase error rate. A prompt change can raise cost. Latency can drift over time. Most teams do not catch these problems right away.
Monitors turn these metrics into real-time alerts. You set the thresholds that matter, and get notified as soon as something crosses the line.
This gives teams a faster way to spot issues and respond before they grow.
Activate your first monitor now.
The first launch week in @RespanAI's history starts soon.
We'll ship a new feature every day from April 20 to 24.
This is our biggest product update yet. It will reshape how teams handle AI observability and evaluations.
Get ready. Next week is going to be a big one for us!











![RespanAI's tweet photo. Respan Launch Week, Day 4: Introducing Respan Integrations
Most teams still spend days setting up observability.
That’s why we invested heavily in Respan Integrations.
We support major LLM and agent frameworks like OpenAI, Anthropic, Gemini, LangChain, Vercel AI, and Pydantic AI, with more being added.
Run 'npx [at]respan/cli setup' and start tracing in minutes, not days.](https://pbs.twimg.com/media/HGnUfQaboAA1AGa.jpg)