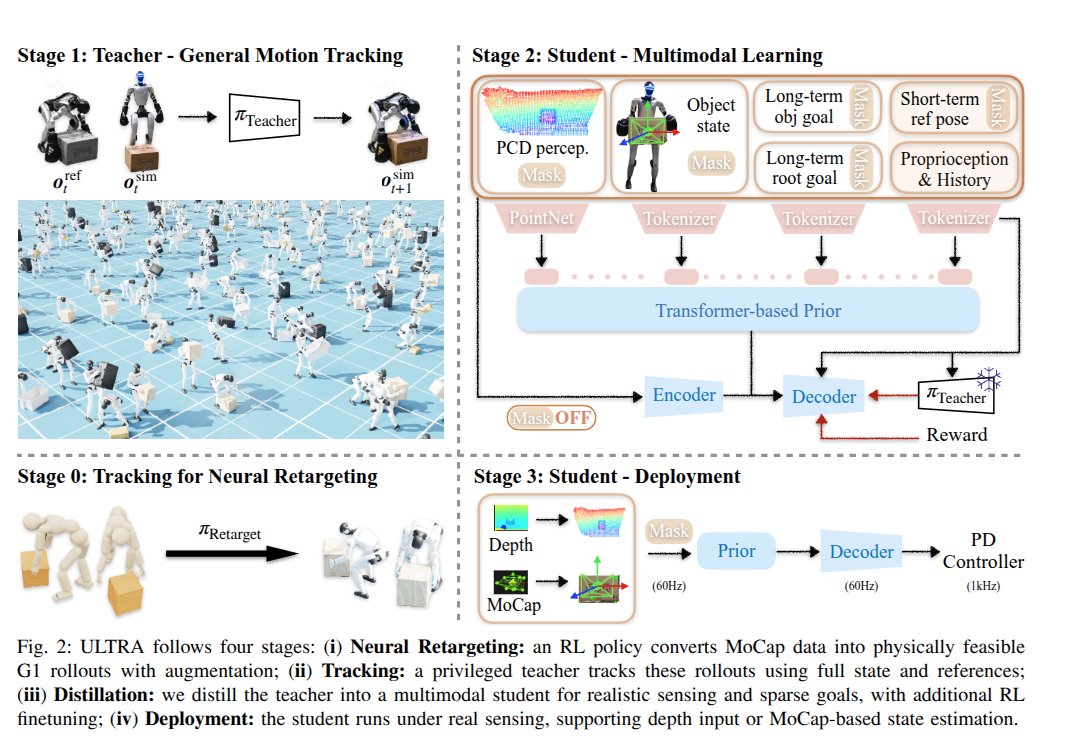
ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
https://t.co/HOxC0WXIL6
1. RL based retargetting
2. multi-modal command student distillation and finetuning so that it can switch between goal reaching vs reference tracking, mocap vs depth
HoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations
https://t.co/mYuPNafG1a
for cross-embodiement transfer:
1. use look-at points in 3D space instead of direct head states
2. mask out arms
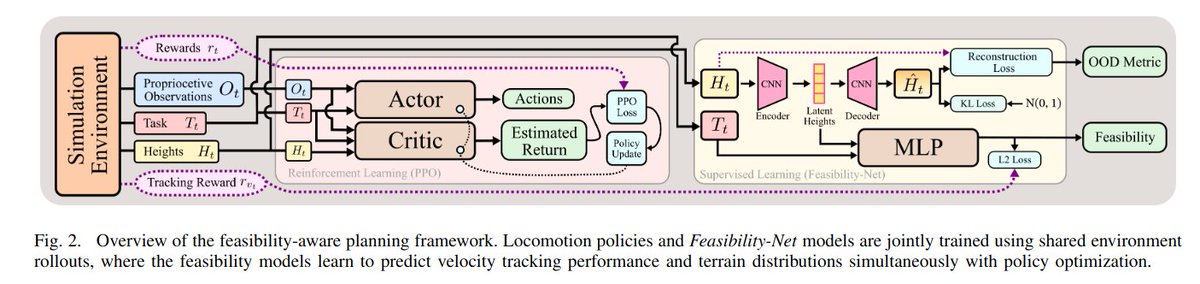
Watch Your Step: Learning Semantically-Guided Locomotion in Cluttered Environment
https://t.co/gwrC59fcnG
this works shows you can train a policy plus using a semantic map to avoid stepping on valuable things.
this is why I believe locomotion should all be mapping based.
Training is multi stage. They first have a mimic policy and distill that to a base policy. Then they use AIP (AMP for interactions) to make the policy generalize instead of memorizing kinematic references.
DF needs mocap, so they also distill this into vision policies.
https://t.co/zxbzsfLN0W
LESSMIMIC: Long-Horizon Humanoid Interaction with Unified Distance Field Representations
use distance field (DF) as a representation for HOI. each link's traj can be defined by DF + grad of DF + vel_norm + vel_tangent.
(tbc)
https://t.co/vFLZ4jbuCt
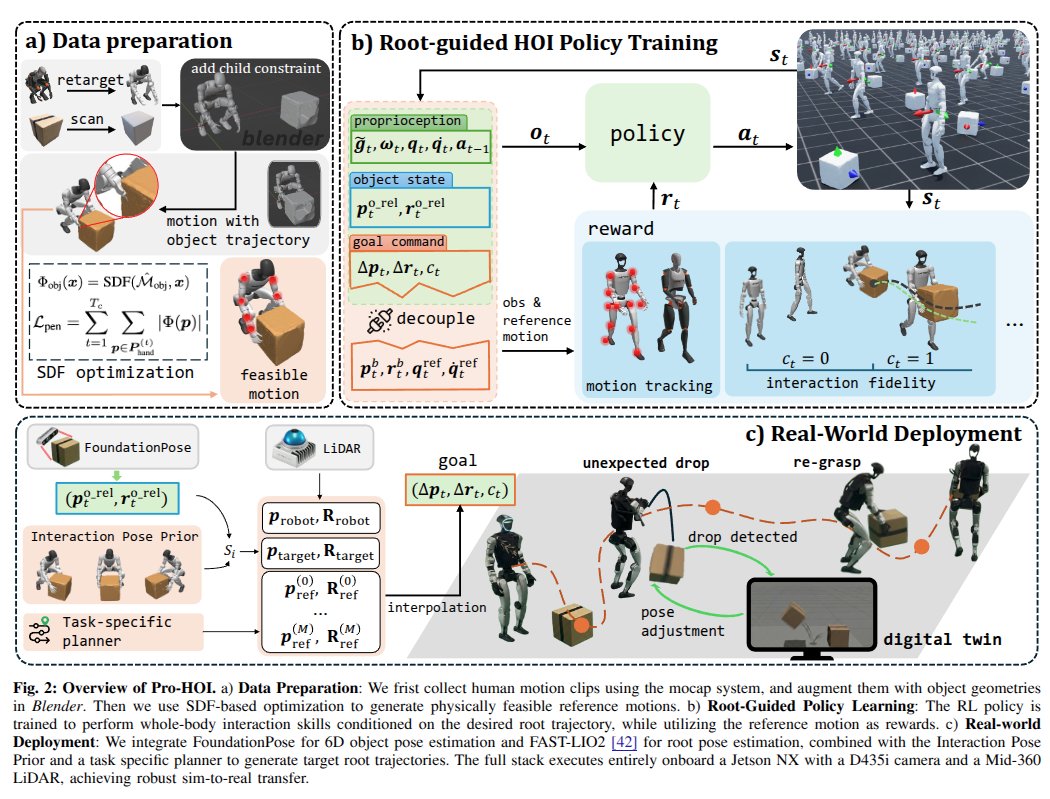
Pro-HOI: Perceptive Root-guided Humanoid-Object Interaction
trained with mimic + contact commands, but deployed with planner to replace the reference.
https://t.co/kPMg3oDKjN
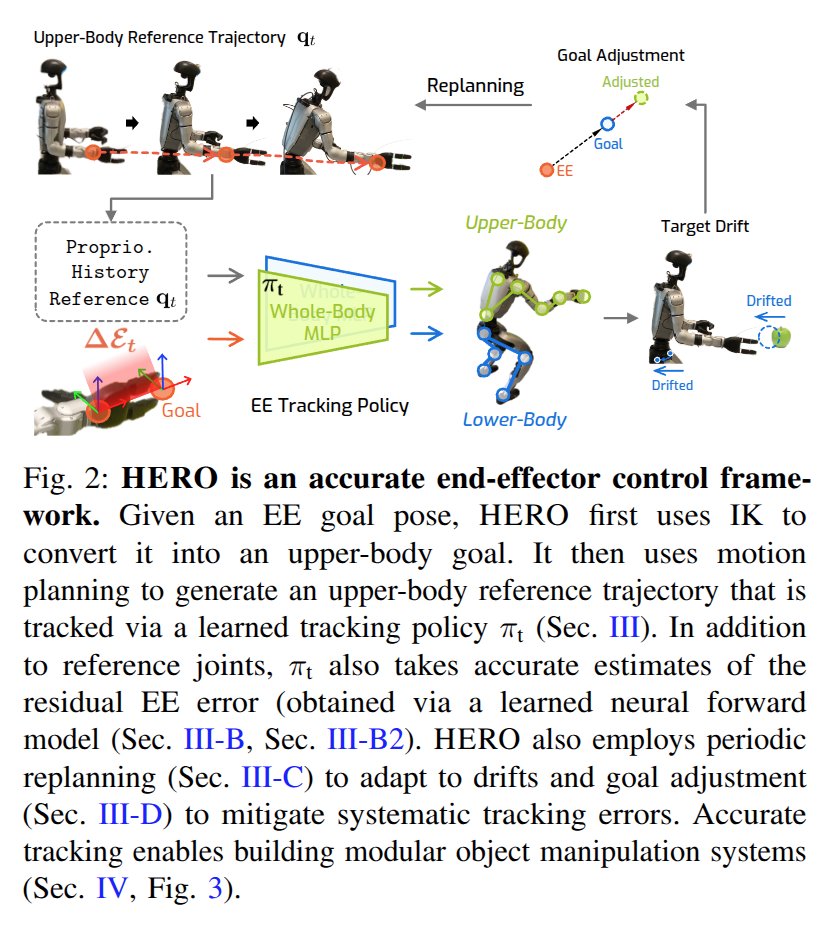
Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
For humanoid EE goal reaching, on top of WBC pose tracking, a neural model is trained to further correct small biases near the goal.
https://t.co/Gz7NSpUw2X
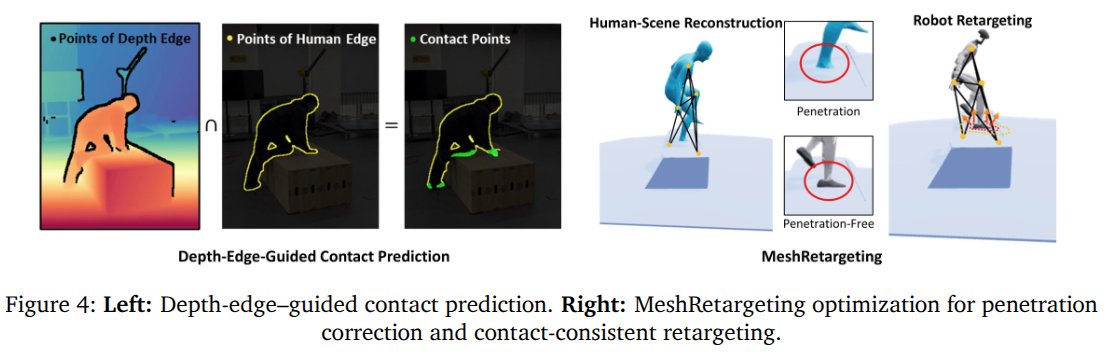
meshmimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
kinda like CRISP + OmniRetarget, but: 1) uses human edge and excludes depth edge in image to extract contacts, which is smart; 2) use polygonal primitives for clean scenes
https://t.co/k4YUDH3vSS
Humanoid Agile Object Interaction Control via Dynamics-Aware World Model
predict object states from proprioceptive obs, use it to transform object template pointcloud, and embed the transformed pcl as policy inputs.
https://t.co/LUJmdDluuJ
Recurrent-Depth VLA
Another way of VLM->diffusion or think-act model or whatever it is called; much faster and adaptive computation while reasoning in latent space.
HUSKY: Humanoid Skateboarding System via Physics-Aware Whole-Body Control
1) models skateboard dynamics in simulation
2) phase-based design for multiple skills
3) human reference and kinematics-based guidance
4) sys-id sim2real
No perception yet
https://t.co/3oMFka4ETh
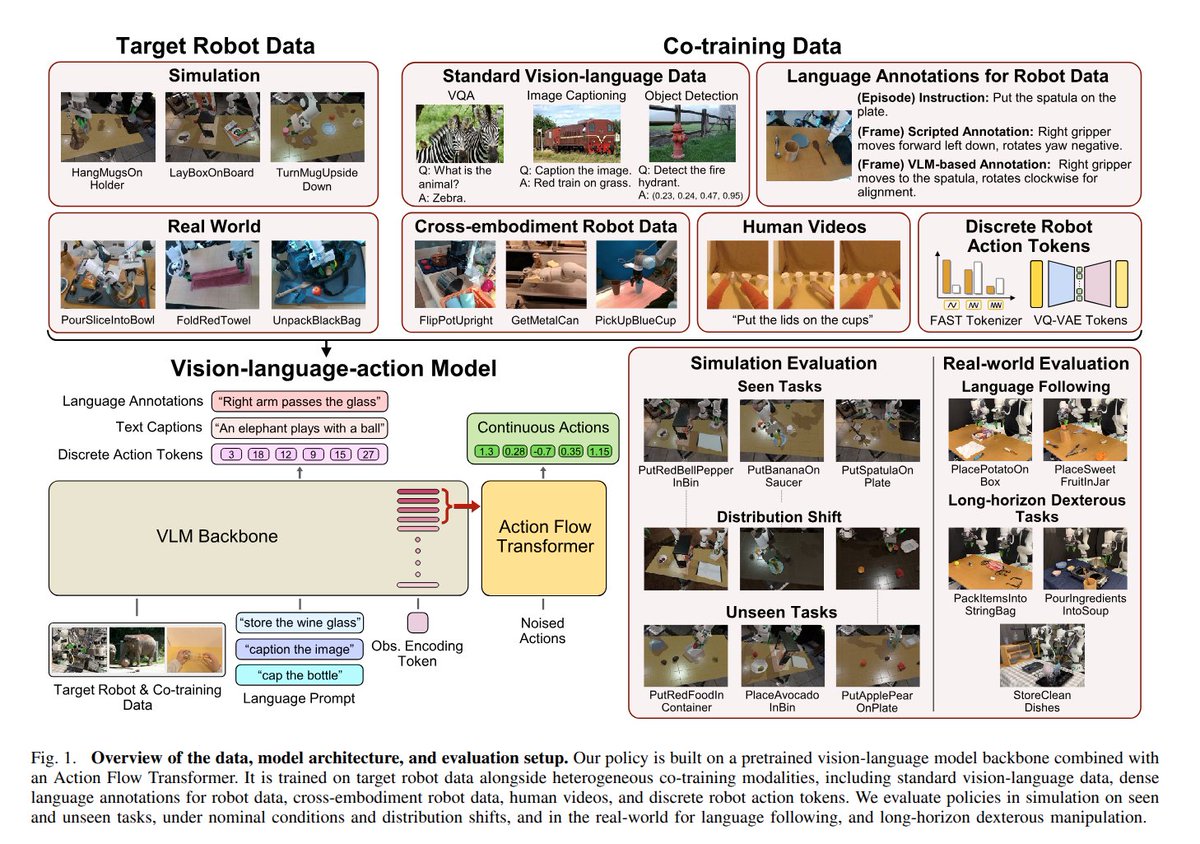
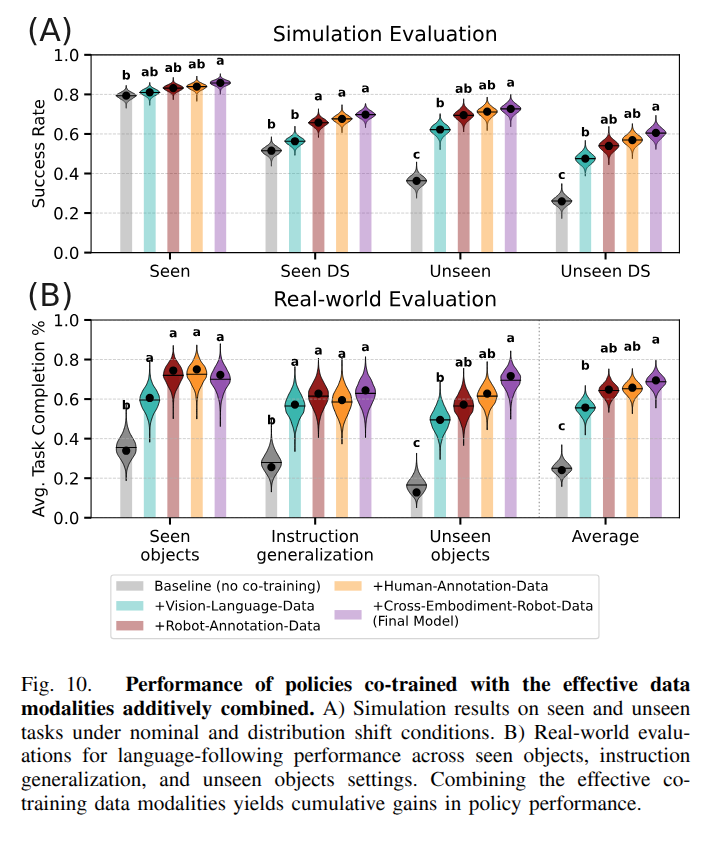
A Systematic Study of Data Modalities and Strategies for Co-training Large Behavior Models for Robot Manipulation
Another paper from TRI on how to train your VLA