i cut my Claude Code token usage by 50% with one file
pasted this into my claude.md and measured for a week
the trick: teach Claude when to use cheap models vs expensive ones
Haiku for bulk work. Sonnet for research. Opus only when it actually needs to think
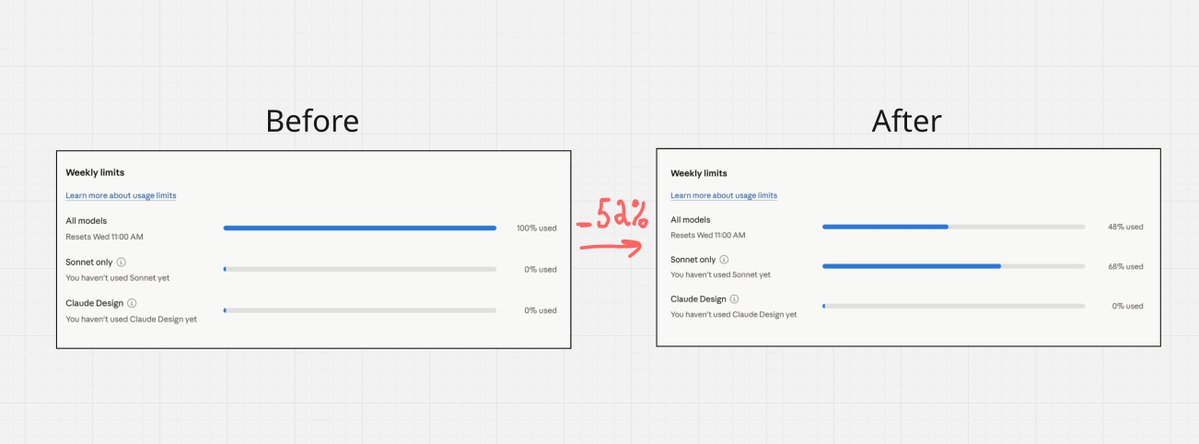
before: mass-burning tokens on everything
after: same output, half the cost
here's the exact config:
1. task delegation block (paste into claude.md)
tell Claude to spawn subagents and pick the cheapest model that can handle the job:
- Haiku: bulk mechanical tasks, no judgment needed
- Sonnet: scoped research, code exploration, synthesis
- Opus: only when real planning or tradeoffs are involved
set two caps:
- Haiku never spawns further subagents (if it needs to, the task was wrong-sized)
- max spawn depth is 2 (parent → subagent → one more tier)
if a subagent realizes it needs a smarter model, it returns to the parent instead of escalating on its own
2. preferred tools block
teach Claude to pick the free option first:
- WebFetch for public pages (free, text-only)
- agent-browser CLI for dynamic pages or auth walls (~82% fewer tokens than screenshot-based tools)
- pdftotext for PDFs instead of the Read tool
when Claude keeps fetching the same way repeatedly, tell it to wrap the pattern as a reusable tool
3. two lines in settings.json
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1" — stops Claude from loading massive context windows you don't need
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "80" — auto-compacts at 80% instead of waiting until it's full
these two lines alone save a mass of tokens on every single session
the whole setup takes 2 minutes
the savings compound on every task you run after that
apply it to your workflow and complete on 50% more tasks via Claude
save it.