Liquid Track Winner: GalamseyWatch by @SAMADON_ 🇬🇭
A fine-tuned LFM2.5-VL-450M detects illegal mining across Ghana's forest reserves (4.8× pixel-IoU lift over base). An LFM2-2.6B tool-calling policy then decides, per tile: downlink_now, flag_for_review, request_higher_resolution, or discard — reasoning over bandwidth budget, cloud cover, and neighbor tiles.
The satellite sends a decision, not a tile.
https://t.co/Gv0yCAeF3l
Our “AI in Space” hackathon, with @DPhiSpace, asked builders: What becomes possible when state-of-the-art models run in orbit?
The hackers that joined us really delivered, and we’re proud to announce the winners today: GalamseyWatch, by @SAMADON_ 🇬🇭, and Parali, by @kumar_munish_ and Aashish Kumar 🇮🇳.
Here’s what they built:
@cactuscompute@nothing@huggingface Excited to share that our team placed 2nd at the Cactus (YC S25) x Nothing x Hugging Face Mobile AI Hackathon.
We were up against teams from MIT, Stanford, and builders from around the world. Grateful to have had the chance to build and compete alongside so many talented people.
Our submission to the @cactuscompute + @nothing + @huggingface hackathon
Lucid bridges your digital world (email, calendar, tasks, notes etc.) with your physical environment using AR spatial memory, voice-first interaction and on-device AI
Never procrastinate your ideas. I had this same concept in 2022 called Urban Moon and I kept procrastinating until I never executed. If you have an idea today, try your very best and bring it to live
Announcing Speech Recognition and Generation from @KhayaAI for 32 African Langs covering ~540 million people!! Live demo in comments.
See video for demo of Speech Recognition for Southern Ghanaian Langs.
@KhayaAI is the only AI covering all government sponsored Ghana langs 🔥
The output was complete gibberish.
So I found a better dataset: intronhealth/afrivox with 18,881 samples and 64 hours of audio. Currently waiting for access since it's gated, but my training pipeline is ready to go.
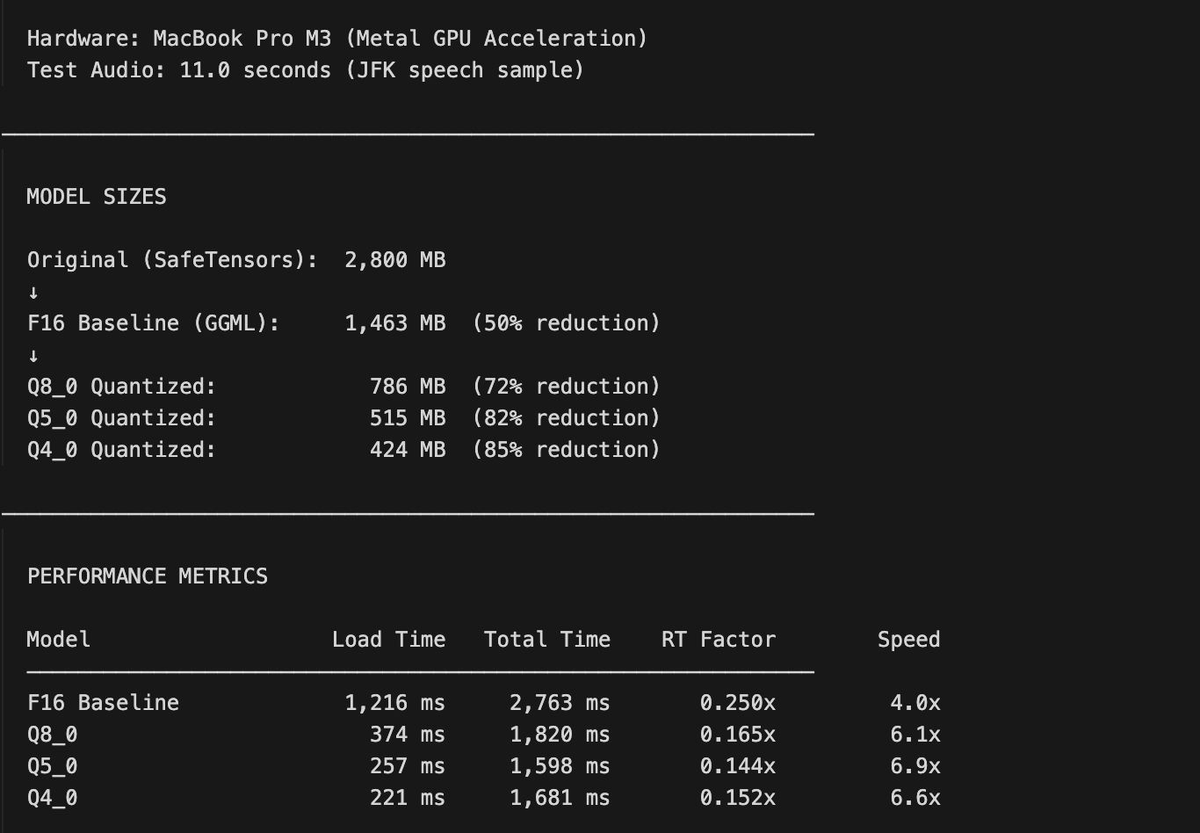
Spent the weekend optimizing afriSpeech-whisper-medium for mobile inference.
The base model is 2.8 GB which is way too large for mobile devices. So I converted it from PyTorch to GGML format, creating three compressed versions:
Q8_0: 786 MB (72% reduction)
There's a "Goldilocks zone" in quantization where you balance size, speed, and accuracy.
Next, I tried fine-tuning the model using intronhealth/afrispeech-dialog. Turns out it only had 49 samples, basically just 3 training batches for a 769M parameter model.
Bscribe helps clinicians spend less time on paperwork, and more time with patients.
It captures clinical conversations, generates structured, evidence-based notes, and syncs directly with your EMR.
Join the beta today.
https://t.co/i7Ne9RspxY
Bscribe helps clinicians spend less time on paperwork, and more time with patients.
It captures clinical conversations, generates structured, evidence-based notes, and syncs directly with your EMR.
Join the beta today.
https://t.co/i7Ne9RspxY