Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
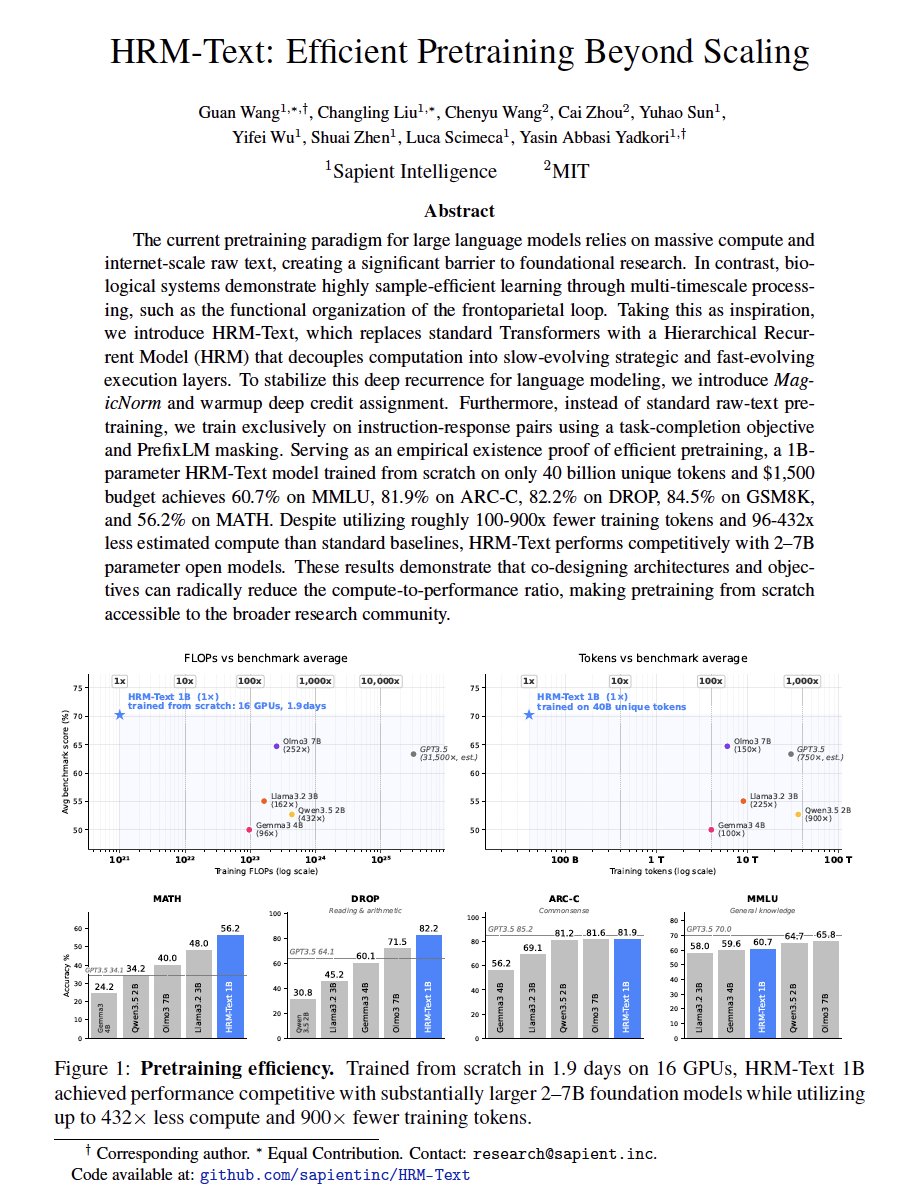
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
Excited to see our community building with HRM-Text! Can’t wait to see where you take it next.🚀
Whether you’re reproducing the benchmarks, testing it out in your own field, or building something entirely new, we’d love to hear about it.
Drop your ideas, questions, and experiments below, and tag @Sapient_Int so we can follow along and cheer you on!🎉
In this benchmark deep-dive, Sapient’s founders William and Guan are joined by research team members Changling and Yasin to unpack HRM-Text’s performance across MATH, DROP, ARC-Challenge, and MMLU. 📊
Beyond the scores, they discuss what each benchmark measures, how HRM-Text compares with larger models, and why efficiency matters.
Watch the full discussion to learn more about HRM-Text and Sapient’s leaner path toward general intelligence.
Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
The HRM-Text paper is now available 🎉
HRM-Text explores a different approach to language model pretraining: hierarchical recurrent computation, task-completion training, and latent-space reasoning.
At just 1B parameters, HRM-Text achieves competitive performance with dramatically lower training cost and data requirements.
1B parameters
40B unique tokens
~1 day of pretraining
~$1000 training cost
HRM-Text 101 is here.
This tutorial takes you from zero to one: from setup to fine-tuning to evaluation.
Download the base checkpoint.
Fine-tune it on a real task.
Evaluate the results.
End to end, on a single GPU.
Watch the tutorial and start building with HRM-Text.
It is time to liberate reasoning from language!
HRM (Hierarchical Reasoning Model) takes a simple idea from the brain: separating reasoning (thinking) from language.
When we think, our brains process information in high-dimensional, abstract streams--deep, instantaneous, and unbounded. Only after we formulate an idea do we compress it into concrete, low-dimensional language for communication.
Current LLMs do most of their "thinking" in the token space via Chain-of-Thought. The results are fascinating, but structurally shallow and highly resource-intensive.
HRM changes this. By reasoning natively in a dedicated latent space, it unlocks a massive internal "scratchpad." It thinks deeper and is unconstrained by tokens, only translating to language when the thought is fully formed.
Deeper reasoning. Way fewer tokens.
Is bigger always better in AI? 🧠
We've reached incredible SOTAs by brute-forcing scale with astronomical token counts. But consider the human brain: running on just 20W of power and trained on ~1B language tokens, it's still making miracles happen.
That efficiency is inspiring.
There are smarter paths toward smarter models, and much smarter ways to scale, and this will be the next breakthrough.
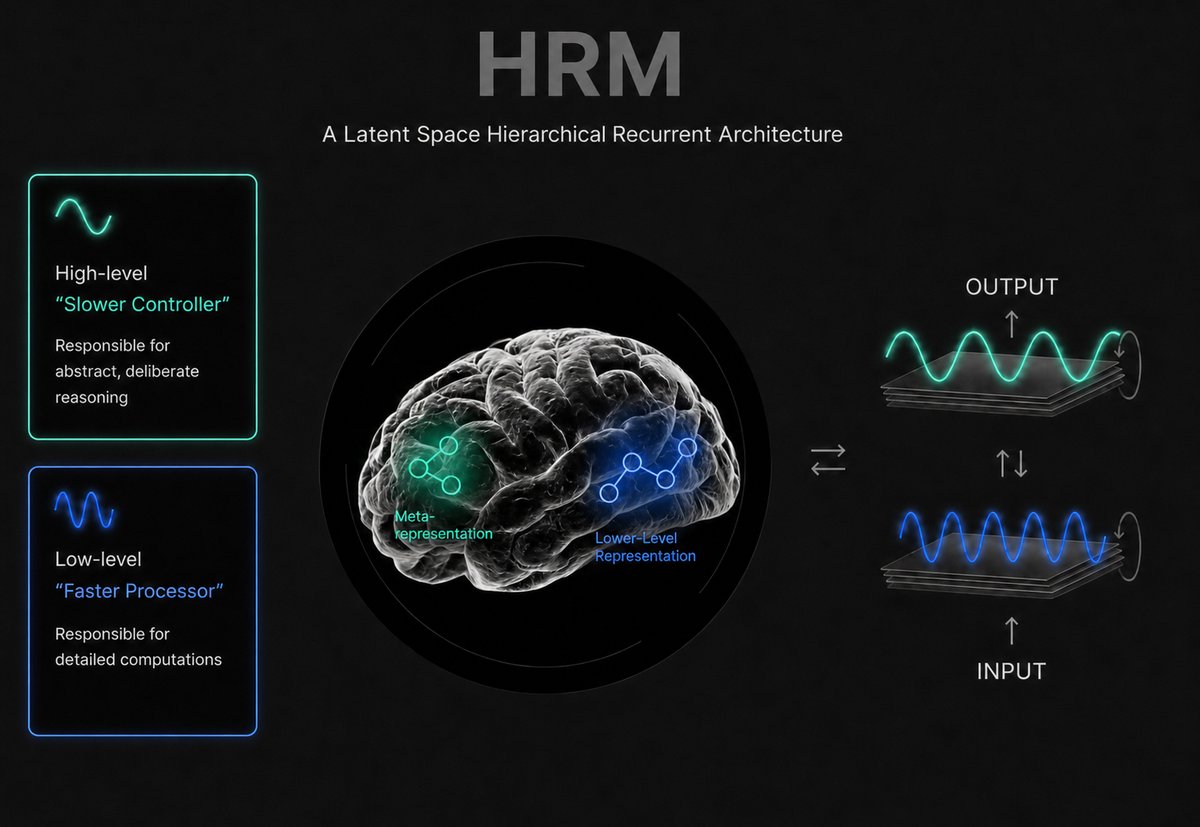
At Sapient Intelligence, we enable deep, efficient reasoning with our Hierarchical Reasoning Model (HRM)—a brain-inspired, latent-space architecture that moves beyond traditional, data-heavy AI.
By decoupling the cognitive load, HRM uses a Slower Controller to guide abstract, deliberate reasoning and a Faster Processor to handle detailed computations. This dual-stream design allows systems to reason, plan, and converge on solutions within latent space.
Behind the code, there is a specific kind of expertise.
We are a team of researchers and engineers rooted in the labs of Tsinghua University, University of Cambridge, University of Alberta, Carnegie Mellon University, and Peking University—with experience at DeepMind, DeepSeek, xAI, and more.
We've seen the limits of the current AI architectures firsthand from within the organizations that scaled them. Now, across three countries, we are building an alternative.
We aren't just shipping another wrapper; we are shipping a new fundamental architecture.
We were honored to support the global AI community as a Gold Sponsor of the #AAAI26 Conference on Artificial Intelligence. It was truly inspiring to connect with so many brilliant minds across the industry.
The future of AGI isn’t just being imagined, it is being built.
Our Staff Research Scientist, Tech Lead Yasin Abbasi Yadkori will be giving a presentation in HALL 4 at 11am.
Come join us in discussing the path to AGI 👏
#AAAI2026#SINGAPOREEXPO#sapientintelligence#HRM
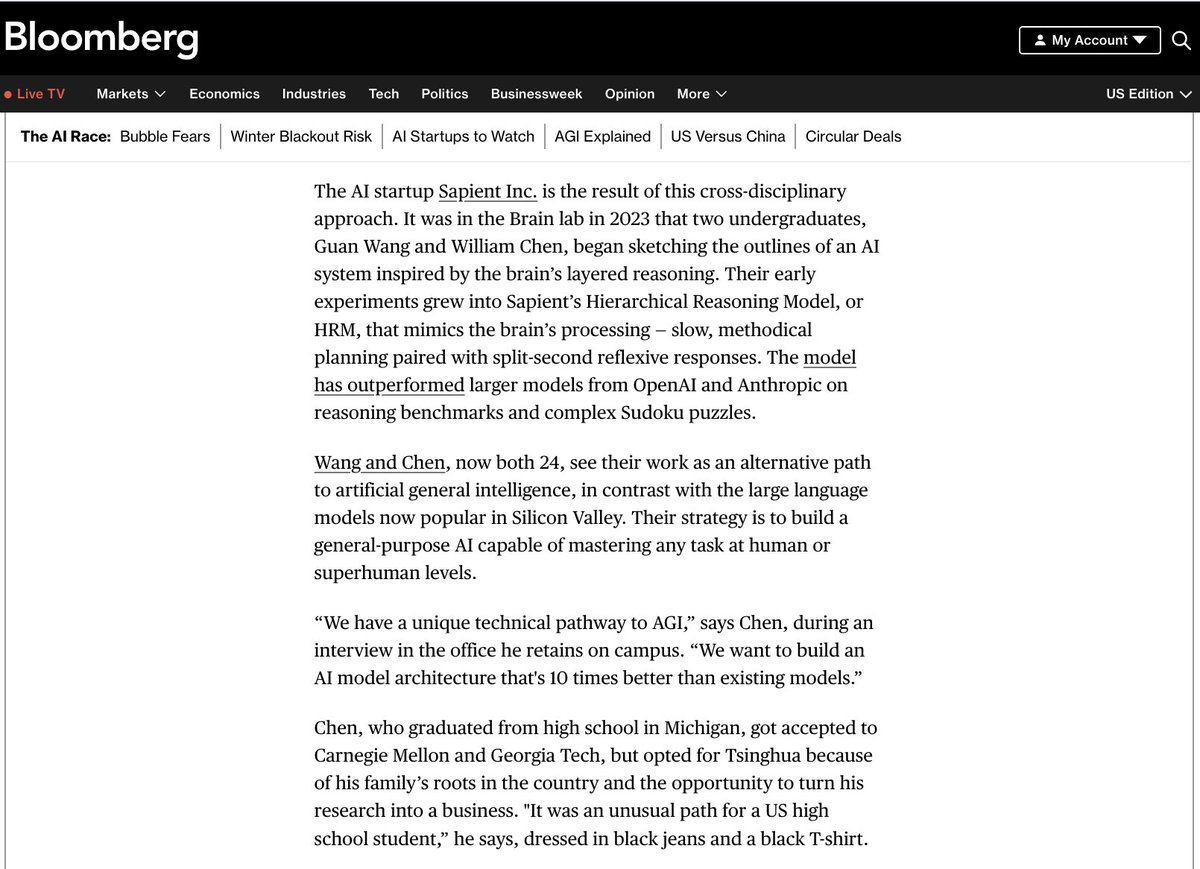
Thank you @Bloomberg for featuring us! We are guided by the belief that brain-inspired reasoning is the road to AGI, and we continue to advance this vision with unwavering determination🚀 https://t.co/RFZLdHNy0q
Proud to share that TRM, derived from our HRM model, is highlighted in Nature ! 🎉🎉🎉
This marks an important step forward for HRM-based reasoning systems, demonstrating the strength of small, structured models in complex reasoning tasks.💡