DoD 2026 AI strategy. IBM Sovereign Core GA. TELUS Rimouski sold out.
Sovereign procurement now demands measurable infrastructure efficiency.
Vendors that can't publish tokens per watt per dollar drop out of the top contracts.
#SovereignAI
Grid-tied operators pay wholesale + transmission + ancillaries. The IEA flags AI-driven price spikes on regional grids.
Behind-the-meter generation locks the rate at the levelized cost of the on-site plant.
That's the watt term, won.
#TokensPerWatt
Two operators, same PUE.
One runs idle GPUs at 1.20.
One runs fully utilized inference at 1.45.
Same PUE. Very different intelligence per electron.
PUE alone is a misleading buying signal in 2026. Tokens per watt per dollar isn't.
#PUE
Worked example.
10M served tokens/hour.
400 kW at 1.10 PUE.
8 cents/kWh all-in.
Tokens per watt per dollar = ~284,000 tokens per dollar.
Now compare that to your cloud quote.
#TokensPerWatt
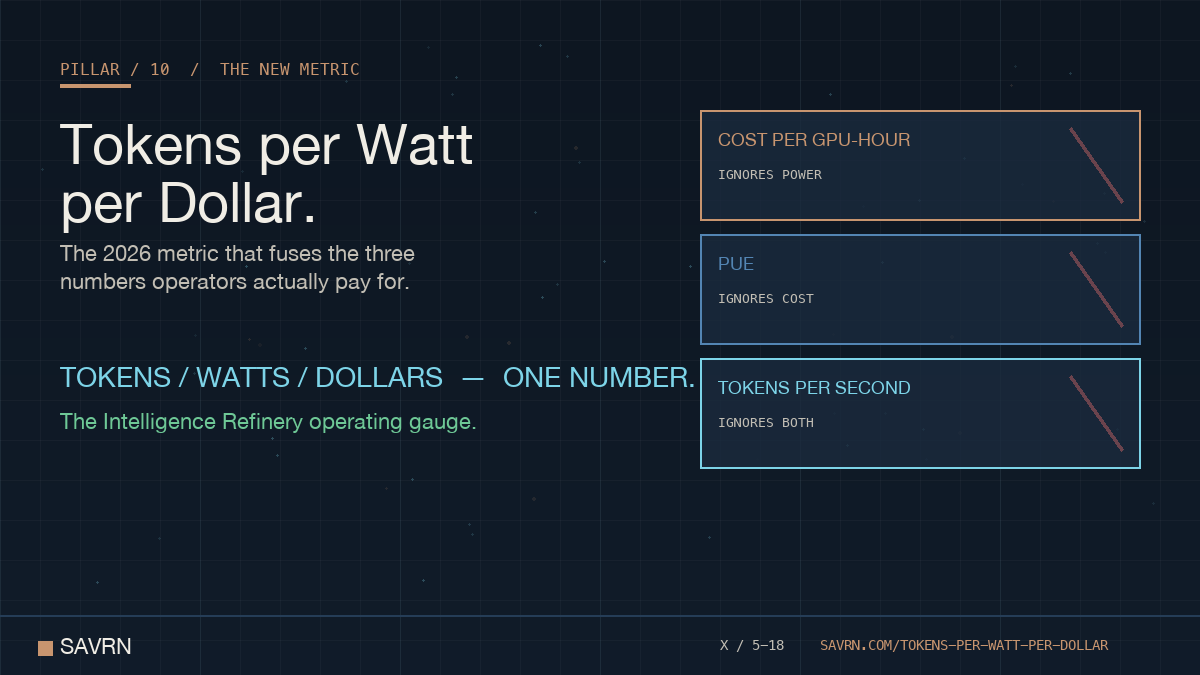
Cost per GPU-hour ignores power. PUE ignores cost. Tokens per second ignores both.
Tokens per watt per dollar fuses all three. The 2026 metric that finally measures intelligence the way operators sell it.
#TokensPerWatt
SAVRN density playbook chart for liquid cooling for AI. Five cooling classes mapped to rack power bands: air up to 30 kW, rear-door 30 to 80 kW, direct-to-chip 50 to 200 kW, single-phase immersion 80 to 200 kW, two-phase immersion 150 to 240 kW.
#SovereignAI #IntelligenceRefinery #AIInfrastructure #LiquidCooling #SAVRNDoctrine
https://t.co/6hSnwnwcEg
Tokens per watt per dollar is the 2026 AI stack metric that finally measures intelligence the way owners sell it. The figure fuses three numbers at once. It tracks how many tokens a system produces, how much power it burns, and how much capital it ties up. As a result, every other legacy metric collapses into a sub-component. Cost per GPU-hour ignores power. Power Usage Effectiveness ignores cost. Tokens per second ignores both. SAVRN treats the unified number as the operating gauge of the Intelligence Refinery, per NVIDIA’s AI factory framing of token economics.
https://t.co/35gBEW9RFz #tokeneconomy #tokenperwatt
The modular AI campus is the architecture enterprise buyers reach for when they cannot wait four years for compute. In particular, hyperscale builds still average 24 to 48 months from groundbreak to first token. Moreover, the grid queue alone runs five years on the median pr project. It collapses that window into 6 to 12 months by manufacturing the compute block in a factory, generating the power on-site, and running every workstream in parallel. https://t.co/n4HCoycClT
Build vs buy AI infrastructure has become the largest capex call of 2026. The decision faces every enterprise CIO, sovereign buyer, and defense integrator. Cloud GPU spend is now a permanent line item rather than an experiment. Colocation rents have re-priced upward as AI rack densities outpace conventional halls. Meanwhile, buyers running AI workloads at sustained utilization have started to ask a sharper question. Should we own the campus instead?https://t.co/vX5786uQLg
Data Center Moratorium: 12 States, 2026 Map, The Fix
Data center moratorium bills are spreading. More than a dozen U.S. states introduced them in 2026. The architecture they target has more in common across these bills than the politics that produced them. First, here is the architecture that does not trigger any of them. https://t.co/z33TxDpVMB
From Site to First Token: SAVRN's Campus Deployment Timeline
The AI infrastructure deployment timeline has become the deciding constraint of every enterprise AI strategy in 2026. Plan it around grid-tied capacity and the strategy is already lost. The median U.S. interconnection wait now exceeds five years. Data center applicants in the largest queues face wait times up to twelve years.
https://t.co/urPH4KnVr9 #ai #deployment #datacenters
The Bottom Line:
Savrn empowers enterprises to accelerate AI adoption—delivering secure, compliant, and high-performance infrastructure without compromise.
#EnterpriseAdvantage#BuiltForAI
Savrn’s Solution:
Deploy enterprise AI infrastructure in under 12 months—up to 65% faster than legacy models. Speed is your new advantage. #SpeedToAI#DigitalTransformation
Pre-Integrated, Offsite-Engineered:
Savrn delivers factory-assembled, tested, and certified systems for rapid, risk-free deployment. No more on-site chaos—just seamless go-live. #EngineeringExcellence#AIReady
Sovereign-by-Design Architecture:
Embedded compliance, data residency, and operational autonomy are built in from day one. Your data, your rules, your future. #Sovereignty#Compliance