👀 You’ve seen AI create.
⚖️ Now watch it evaluate.
Introducing Scorable — your Automated AI Evaluation Engineer from Root Signals.
🖱️ https://t.co/PtXjqScgx9
#AI#Automation#RootSignals#Scorable
What does a 3,000-dimensional LLM judge evaluation actually look like?
Here's a real-world example: 30x100 complex judge evaluations against a single data point.
The target is an AI system that creates employment contracts.
The driving question was:
"Are the clauses in this contract actually enforceable across the globe?"
This is not a yes/no question.
Every evaluation needs its own judgement call.
Once you run a comprehensive evaluation stack, things change from "individual tests" to more like mapping the risk surface.
When teams don't get value out of LLM judges, it usually comes down to one of these root causes:
a) The judges not calibrated accurately enough. (More on this later.)
b) The evaluation stack is too narrow - addressed here.
Check the 2 min video showing how it works.
The stack created and orchestrated with @ScorableAI CLI.
In other domains - if this is not yet standard operating procedure across your high-stakes business questions, or your agent behavioral analyses, it should be.
Btw, any lawyers out there who would like to expand this analysis, I'd love to hear from you.
ChatGPT, Claude and Gemini all just declared Scorable's new Aegis the most rigorous choice for building AI evaluators for any AI system that needs to survive audit. Aegis automatically builds tightly calibrated LLM judges across a variety of real-world situations.
Yes, but the key to sustained progress is missing: AI-driven measurement.
With AI running the company OS, each workflow needs a measurable AI judge layer that knows what "better" means for you.
No pass/fail. A metric. A utility curve.
Scores for: Did the sales convo was follow your proven success patterns? Is the landing page upgrade more convincing than before? Was the support bot's reply awesome? Etc.
You don’t need more AI metrics.
You need to know which ones matter today.
Scorable surfaces the right metrics in Slack when they’re actually useful.
👉 Connect Scorable to Slack and see it in action.
🎥👇
https://t.co/Ka76fyTfbO
#AIEngineering#Metrics#Scorable
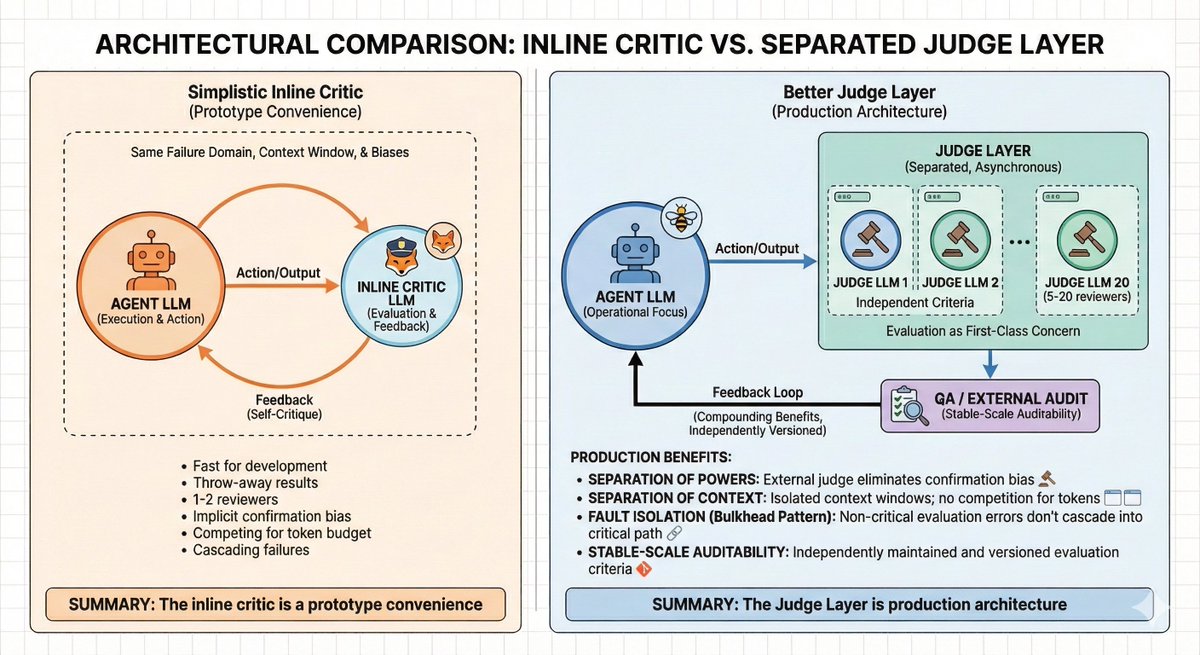
Adding a judge LLM to an AI agent's execution loop is a key component to building better agents.
But most builders misunderstand the limitations.
The reason this approach works because the judge provides iterative feedback ('evals') to the agent.
But in that tightly-coupled system, evaluation and action share the same failure domain, context window, and implicit biases.
The fox guarding the henhouse is *in* the henhouse.
What a year it’s been. Thanks to our clients, partners, and fellow AI builders for trusting us to judge, score, and improve their LLMs. Here’s to a new year of better responses—and fewer hallucinations 😉
#NewYear #2026 #Scorable#AIhallucination#LLM
Built an AI chatbot in #n8n that doesn’t just respond, it evaluates itself.
Scorable AI handles response generation and judging, with results visible in the workflow.
Real automation, not just a demo 👇
https://t.co/O821U1a1vf
🚀 Root Signals has become Scorable.
The time has come. As our platform has evolved, Scorable has become the name our users associate with highly automated, trustworthy evaluation of AI systems.
In the Scorable world, every AI application can be measured, governed, and improved automatically, driven by contextual objectives and observations.
The key to scalable AI adoption is simple:
use AI itself to oversee and validate AI.
This is the evaluation infrastructure that scales with the pace of AI — and is on track to become the fabric of KPIs and decision-making in tomorrow's organizations.
But there is still hard work ahead.
We will be sharing our latest advances in the coming weeks. Stay tuned.
How accurate is your AI? 🤖
In our latest demo, we show how Scorable evaluates AI and web content using compliance-based Judges.
🎥 Watch here: https://t.co/6dIohxEQVc
#Scorable#RootSignals#AITools#AICompliance
Want your AI app to sound smarter — automatically?
Root Signals evals help you measure and refine model responses with minimal setup.
🎯 Improve tone, clarity, and helpfulness
⚙️ Works with OpenAI, Anthropic & more
👉https://t.co/5PKdYagwvj
#AI#LLM#AIEvaluation#GenerativeAI
🎥 New video: The easiest way to start using Root Signals evals in your AI app
Learn how to make your AI app more reliable — with just a few simple steps.
👉 Watch here: https://t.co/CvdWC3FGRo
#RootSignals#AI#LLM#AItools#AIDevelopment
🌍 World Mental Health Day reminds us that even the brightest ideas need a calm, healthy mind behind them. Innovation grows best where empathy and rest are part of the routine — not the exception. Let’s make that our norm 💚 #WorldMentalHealthDay#MentalHealthAwareness
What’s the point of “state-of-the-art” AI if it ignores your company’s rules?
https://t.co/VD4KlsrzJz turns your policies & examples into custom evaluators.
Because alignment > hype 👉 https://t.co/pndOolV9FS
#AI#LLM
Are your AI automations misbehaving? 🤖
Fix them with Scorable by Root Signals — build evaluation stacks from your own policies & examples.
🎥 Watch now: https://t.co/p16ZWG8urD
#AI#Scorable#RootSignals#TrustworthyAI
Humans are the best AI evaluators — but you’ve got bigger things to do than eval 24/7. That’s where Scorable comes in: an AI evaluator that never sleeps, automating the hard parts of evals for you. 🚀
👉 https://t.co/6eFfgpGyvv
#AI#LLM#AIeval#AItrust#MachineLearning
Did you read our latest blog? 📝
Even the most advanced AI models can hallucinate or give unreliable outputs. That’s why we built Scorable — your personalized AI evaluation stack in just 1 minute.
👉 https://t.co/1jvYRqhsq1
#AI#LLM#AIeval#AItrust#MachineLearning
🚀 Exciting news!
Our CEO @AriHeljakka will be joining the stage at the #MyData2025 Conference in Espoo on Sept 25th 🎤✨
He’ll take part in a panel on Trustworthy AI within the EU AI ecosystem — alongside top experts from across Europe. 🌍🤝
🗓 Thursday 25.9
🕜 13:30–14:30