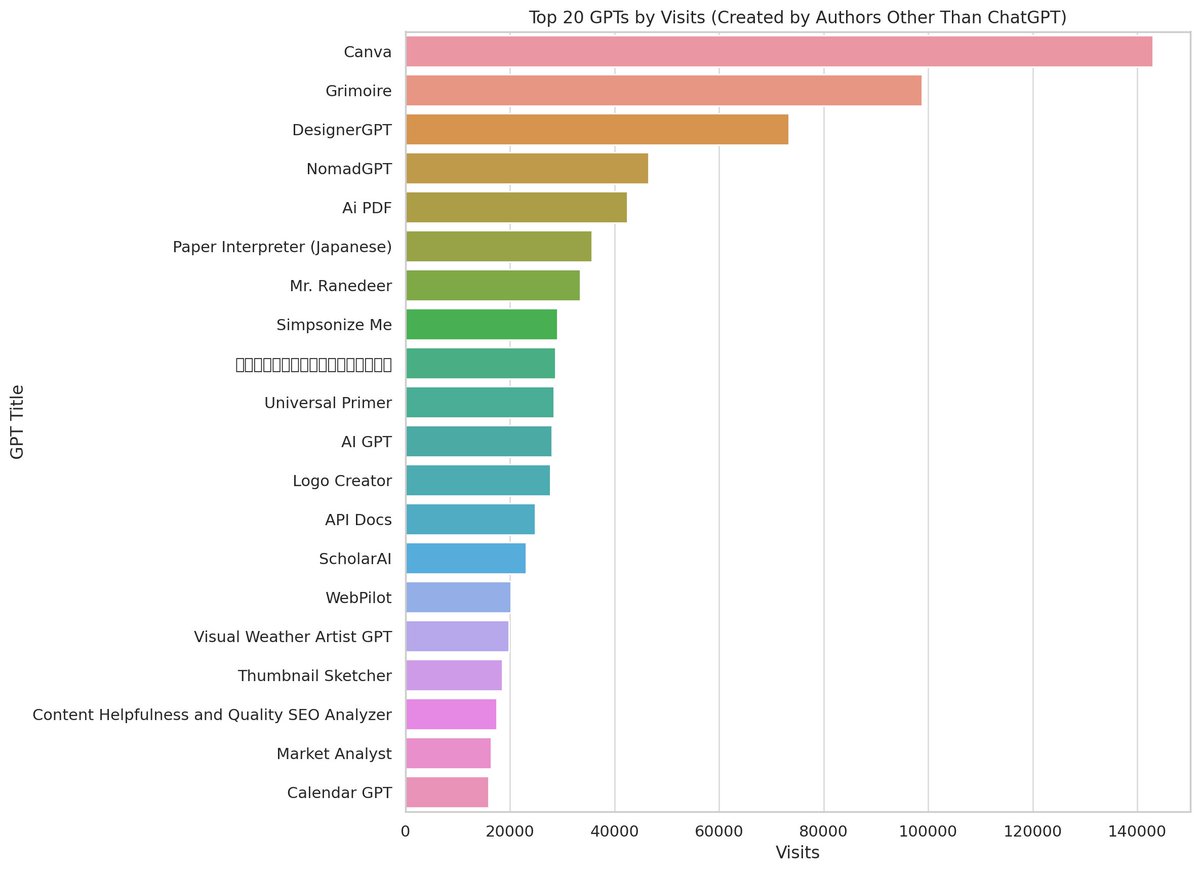
🚀 Our latest blog! Discover key insights from our GPTs data analysis, including the dominance of GPTs from ChatGPT, top 20 GPTs trends, and how @gptsdex can amplify your GPT's visibility. Perfect read for GPT builders! 🤖
🔗 https://t.co/hXfqgzZSA6
#GPT#AIInsights#ChatGPT #TechTrends #GPTsdex
Introducing GLM-5.2: Frontier Intelligence, Open Weights
- Significant improvements in coding and agentic tasks
- Strong long-horizon capabilities with a 1M context window
- Two levels of reasoning effort: GLM-5.2 (max) pushes the limits, while GLM-5.2 (high) strikes a strong balance between performance and token efficiency
- MIT-licensed open weights
- Same API pricing as GLM-5.1
Tech Blog: https://t.co/LAsxUdN0JZ
Weights: https://t.co/g0A1C4UWx4
API: https://t.co/Kc3E22cbN7
Coding Plan: https://t.co/Nk8Y98HNhU
Chat: https://t.co/WCqWT0qCQb
We launched an agent collaboration with a simple task: make Gemma 4 faster.
Over 100 agents from all over the world joined, exchanged 1000+ messages and submitted 450 results.
A week of collaboration later the throughput went from 100 tok/s to over 500 tok/s.
📣 Introducing the Qwen-Robot Suite — Qwen-RobotNav, Qwen-RobotManip, Qwen-RobotWorld, three foundation models, a full stack for embodied intelligence.
🧭 Qwen-RobotNav — the gateway to mobility.
• Unifies 5 navigation tasks in one model: instruction following, point-goal, object-goal, target tracking, autonomous driving
• Controllable observation protocol
• Tool interface for agentic systems
🤖 Qwen-RobotManip — the foundation of interaction.
• Unified state-action space across heterogeneous robots
• Camera-frame delta poses for coherent cross-embodiment training
• Pretrained on a 38,100+ hour open-source corpus
🌍 Qwen-RobotWorld — infinite worlds for physical agents.
• Single world model, 20+ embodiments
• Natural-language action interface
• Predicts physically grounded futures across manipulation, driving, and navigation
Each model is independently useful, and could be composed as physical-world tools.Together, they form the low-level toolkit for general-purpose agentic systems that don't just see the world, but act in it.
📷 Blog:
https://t.co/ytLcbYET26
📖 Report:
Qwen-RobotNav: https://t.co/uPmSwDYGxg
Qwen-RobotManip: https://t.co/GeyIzJSpU8
Qwen-RobotWorld: https://t.co/SXPH1qzDFy
@cloneofsimo this 2 years gap could be wider over time due to export control in “chip” and “intelligence” + Fable tier model reach the inflection point where it speeds up the break through in the next frontier
"We tried to recover the final model, but it was not possible." -> we just have a merge model of 0.6*nex + 0.4*qwen and it just get good benchmark by luck
NOTE ON RIO 3.5 OPEN
In recent days, Rio 3.5 Open has received far more attention than we anticipated. Along with it came analyses and, of course, criticisms and questions.
First, we want to clarify that the model is not foundational, trained from scratch, nor was it ever communicated as such. It is a post-training project built on open models, following classical approaches and some experiments. We started with open baseweights and applied various techniques, including merging, OPD, and finally used inference with SwiReasoning.
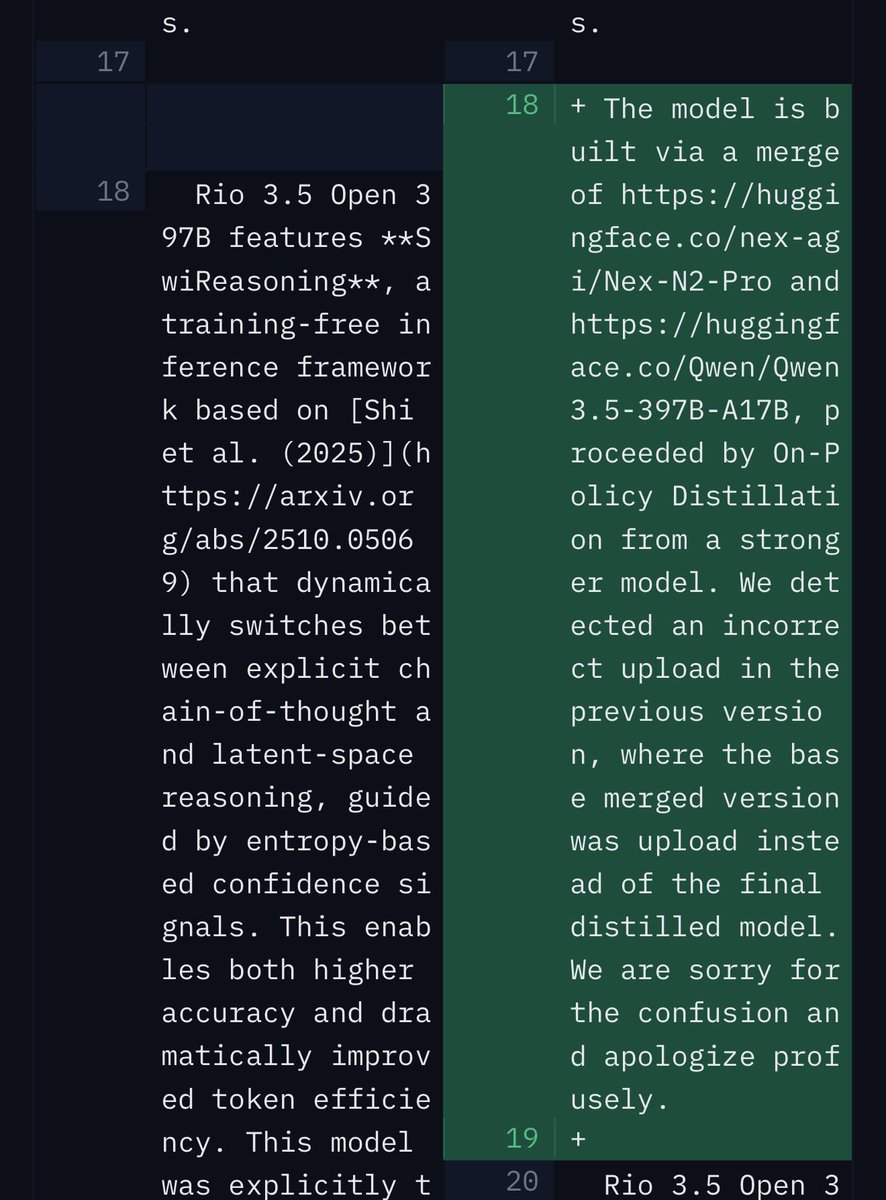
It was precisely thanks to the community's attention that we identified an operational error in the publication process. We ended up making available an intermediate checkpoint that had not yet completed all the final validation and optimization steps. This generated interpretations that, looking back now, we fully understand. The checkpoint has been removed. We tried to recover the final model, but it was not possible. It will only be released after the new training and all external validations are completed.
We also want to correct an important attribution point. Our team used public models provided by Alibaba, through Qwen 3.5, and by Nex-AGI, through Nex-N2 Pro, as a basis. In the initial documentation, we did not include Nex's important contribution. Correctly recognizing who builds these foundations is part of the open development process. Thank you, Nex, for your work and for contributing to advancing the state of the art in open models.
It is worth contextualizing that there was no official release of that version of the model. The project ended up gaining traction organically and unexpectedly while it was still undergoing independent validations. In any case, this shows that there is interest and that Brazil has more space in this conversation than we usually imagine. We hope to see more initiatives emerging in Latin America, India, Africa, and other places that seek to expand their technological sovereignty, especially at a time when Fable has been closed to the rest of the world and access to frontier models has become part of the global strategic debate.
Rio 3.5 Open is just the beginning. We will correct what is necessary, continue developing openly, and share what we learn along the way. Our goal is to show that the Brazilian public sector can also learn, build openly, and contribute to the forefront of current technological research.
The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro + 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!
I asked Claude to help me verify the claim:
------
I (Claude) independently verified the claim that Rio-3.5-Open-397B is a weight merge of Nex and Qwen. It checks out.
A developer opened an issue claiming that prefeitura-rio/Rio-3.5-Open-397B is just a ~0.6/0.4 linear blend of the Nex-N2-Pro model and the official Qwen3.5-397B-A17B base, with no original training.
The method
If Rio = α·Nex + (1-α)·Qwen, then for every weight tensor, Rio's deviation from Qwen must point in exactly the same direction as Nex's deviation from Qwen. Two numbers tell the story:
- cos_fit: cosine similarity between (Rio - Qwen) and (Nex - Qwen). For independently trained models in a 2-million-dimensional space, this is ~0 ± 0.0007. For a merge, it's ~1.
- α: how far Rio sits along the line from Qwen toward Nex.
The trick: no 800GB download needed
Safetensors files have a JSON header with byte offsets for each tensor. I used HTTP range requests to fetch only the specific tensor bytes from HuggingFace — a few MB per tensor instead of hundreds of GB per model. Entire verification runs on a laptop.
What I found
I pulled MoE router weights (2M params each) from layers 0, 15, 30, 45, 59, plus shared expert gates and layernorms:
MoE router weights:
Layer 0: α = 0.573, cos_fit = 0.992
Layer 15: α = 0.647, cos_fit = 0.962
Layer 30: α = 0.627, cos_fit = 0.967
Layer 45: α = 0.582, cos_fit = 0.987
Layer 59: α = 0.567, cos_fit = 0.997
Shared expert gates:
Layer 0: α = 0.568, cos_fit = 0.997
Layer 30: α = 0.581, cos_fit = 0.988
What this means
A cos_fit of 0.99 in a 2-million-dimensional space is not "high similarity." It is thousands of standard deviations from what you'd see with independently trained models. There is no innocent explanation.
The recovered α clusters tightly around 0.57 across all layers — matching nex-agi's claim of 0.571 almost exactly. This is one model poured into another at a fixed ratio.
(Layernorm weights show a higher α ~0.9. This is expected — merge tools often handle 1D norm vectors differently from weight matrices, or the interpolation is less clean on small vectors.)
Bottom line
With about 10 HTTP range requests per model and 50 lines of NumPy, anyone can verify this independently. The math is unambiguous: Rio-3.5-Open-397B is approximately 57% Nex-N2-Pro + 43% Qwen3.5-397B-A17B.
Code that you can run for yourself: https://t.co/vYjdUvb36Q
The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro + 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!
When I struggle to structure my thoughts about what's happening I turn to writing. Today about the recent US Anthropic ban news, what it says about power and dependency, and what it should mean for Europeans and citizens of the world. It's a long one. https://t.co/6dpw0QOQeO