Last week, we met with HRH The Princess Anne and @OpportunityIntl at St James's Palace to discuss how more efficient financial services and education can help empower people on low incomes and give them the #opportunity that global trade brings with it...
As projects move from prototypes to production, enterprises need more than compute.
From SOC 2 Type II to granular IAM and full infrastructure visibility, our AI Cloud 3.0 “Aether” release delivers trust and performance at scale: https://t.co/4oBoU4Yvrm 🔥
#AICloud #EnterpriseAI
Last week in London, founders, investors and builders gathered to learn how open-source models are shaping the future of AI.
Our own @romanchernin joined @antonosika from @lovable, Thomas Wolf from @huggingface and @mattweigand1 from @Accel for this exclusive, invite-only fireside chat.
Thanks to everyone for a wonderful evening of networking and big ideas.
#OpenSource #Startups
Agreement between the UK and US Governments to deepen cooperation in advanced nuclear technologies and make it quicker for companies to build new nuclear power stations sets the stage for a significant step forward in the energy security and resilience of both nations. We welcome the commitment by the UK Government and @GBEgovuk to get nuclear project sites approved more quickly @energygovuk Read more: https://t.co/yLR2PBfMVV
Announcing a major new agreement with @Microsoft for AI infrastructure. This means significantly more aggressive growth of our AI cloud business in 2026.
We’ll deliver the capacity from our new data center in Vineland, NJ, starting late 2025. Read more: https://t.co/bTfWtp9Cfc
Excited to announce: we've just added GLM-4.5 and GLM-4.5 Air to Nebius AI Studio!
These SOTA open-source models from @Zai_org unify reasoning, coding, and agentic capabilities, topping benchmarks.
GML 4.5 outperforms Claude 4 Opus Thinking on @ArtificialAnlys Intelligence Index (56 vs 55). Beats Kimi K2 & Qwen3 in tool calling (90.6% success) and agentic coding.
Experience 128K context & blazing-fast inference. Perfect for complex agents!
Try now 👇
Qwen3 is recognized as the #1 open model in the Arena🏆! Ranked #3 overall and #1 in Coding, Hard Prompts, and Math – a remarkable milestone for @Alibaba_Qwen in open #AI.
#AlibabaAI
Today, we are releasing 4 hybrid reasoning models of sizes 70B, 109B MoE, 405B, 671B MoE under open license.
These are some of the strongest LLMs in the world, and serve as a proof of concept for a novel AI paradigm - iterative self-improvement (AI systems improving themselves).
The largest 671B MoE model is amongst the strongest open models in the world. It matches/exceeds the performance of the latest DeepSeek v3 and DeepSeek R1 models both, and approaches closed frontier models like o3 and Claude 4 Opus.
"My colleague wisely observed that one of the most powerful ways that the U.S. has inspired the Liberty Movement worldwide now for two-and-half centuries is that visitors have seen with their own eyes that speech here is quite free."
My latest column for @folha
Big news! Toloka has secured a strategic investment led by Bezos Expeditions, with participation from
@MParakhin who also joins as Board Chairman. This investment fuels our next stage of growth, powering the expansion of our unique human+AI solutions!
https://t.co/EF4zDXyjBR
This is brave. Just look at the scale.
@Brave Software, with over 80 million users, develops a fast, privacy-focused browser and Brave Search, an independent search engine. Its AI-powered feature, Answer with AI, provides real-time, privacy-centric summaries for user queries — with Nebius behind the scenes.
🔹 Goal:
To generate AI-driven search responses with modern infra.
🔹 Solution:
Brave harnesses low-level access to Nebius’ latest-generation compute to deliver state-of-the-art AI inference with another one of our clients, @vllm_project. The proven stack — featuring @HAProxy for load balancing and Terraform for provisioning — leverages custom model quantization and sharding, ensuring optimal throughput, low latency, and effortless scaling.
🔹 Results:
With Nebius, Brave runs large AI models with nearly 100% compute utilization, delivering real-time AI summaries for over 11 million queries daily. The scalable infra allows Brave Search to provide faster, more relevant answers while maintaining strict privacy standards.
We’ve learned from the old and new assaults on liberalism that good politics depends not so much on institutions as it does on the moral sentiments supporting the institutions.
“Add institutions and stir” is not a recipe for prosperity.
If people of malice take over a nation by coup or by vote, no structure of institutions, such as the American or Brazilian constitution, can help.
Not much.
My latest column for @folha
I've been writing code for 30 years, and there has never been a better time for software builders.
The price of intelligence keeps dropping. Fast!
At this rate, everyone will soon have access to IMMEDIATE and UNLIMITED intelligence in their pockets for FREE.
If you are building AI applications, the cost of accessing the world's best models is no longer a limitation.
Using models like DeepSeek-R1 or Llama 3.1 405B gives you some of the best results you can get:
• Best-in-class models
• Extremely cost-effective
• Fast speeds and low latencies
• Open-source
• Nobody gets access to your information
The best part:
All you need to know is how to tap into an API to get immediate access to these models. You don't need to worry about hardware, memory management, uptime, or anything else.
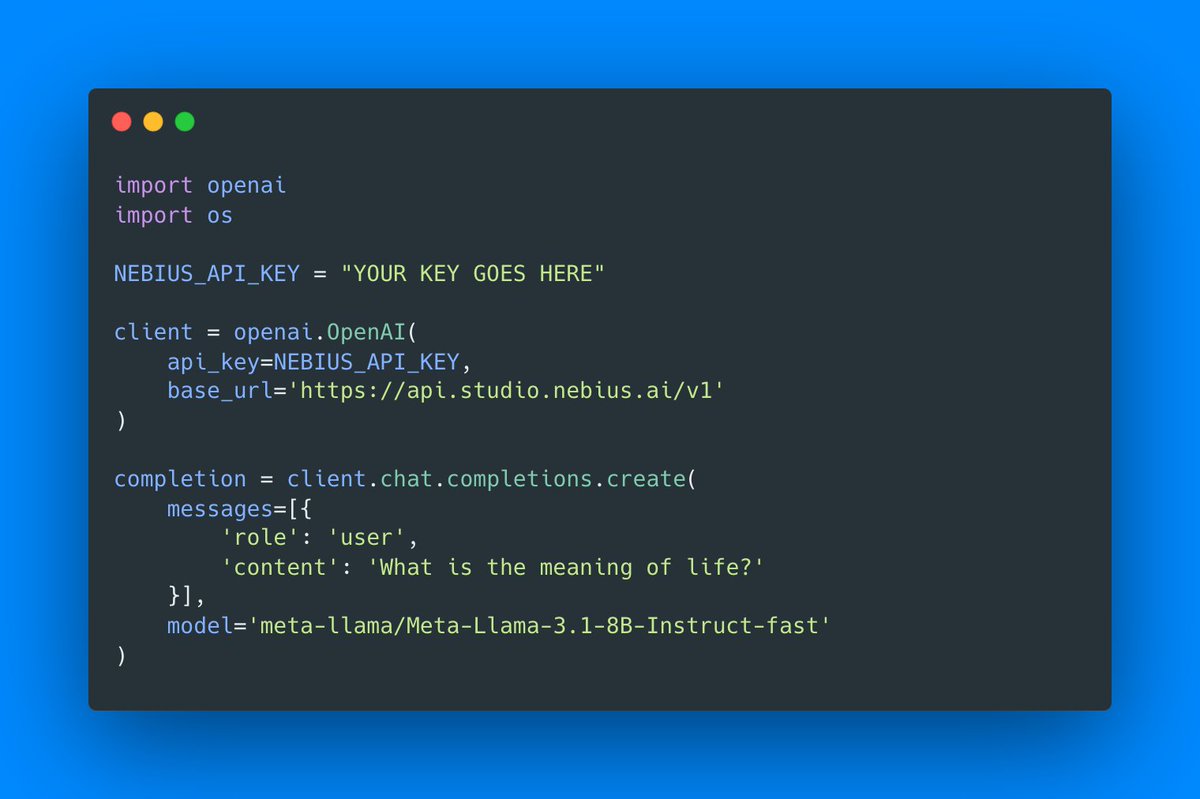
I've been using Nebius AI Studio with Llama 3.1 8B, and the price/speed combination is ridiculously good.
They host the most popular models you've heard of (including DeepSeek R1 and the Llama family of models.) But if you need a new model, they have a way for you to request it, and they'll host it.
NVIDIA Blackwell architecture redefines generative AI and accelerated computing with unmatched performance, efficiency and scale.
Nebius is adding @NVIDIA GB200 NVL72 and NVIDIA HGX™ B200 to its AI Cloud soon, clusters are being deployed in the data centers in the United States and Finland.
We have invited NVIDIA’s HPC & AI Solution Architect Laurent Duhem to discuss benefits, potential challenges and use cases of Blackwell architecture, specifically multimodal LLMs.
Register and join us for this webinar on Feb 20 — it will be insightful for technical specialists, engineers, developers and solution architects interested in high-performance computing and AI optimization:
https://t.co/lhl6lDzmC0
Nebius becomes a Reference Platform NVIDIA Cloud Partner.
Expanding our current partnership within the @NVIDIA Partner Network as a Preferred-level Cloud Partner, we are proud to announce participation in a new Reference Platform NVIDIA Cloud Partner Specialization. With a focus on validated reference architectures and enhanced collaboration with NVIDIA, we now bring:
- Differentiated, regionally impactful services for customers’ AI computing needs worldwide.
- Cloud infrastructure that is designed and optimized with full-stack innovation across accelerated systems, enterprise-grade software and AI models.
- Access to highly reliable and high-performance GPUs in the cloud through close collaboration with NVIDIA.
- Validated clusters that adhere to NVIDIA Cloud Partner Reference Architectures, ensuring alignment across all hardware and software components.
We’re thrilled to expand our close partnership with NVIDIA strengthening our collaboration model.
As you’re reading this post, Wubble sets the mood with smooth tunes generated on Nebius. 🎵
Wubble is a cutting-edge AI platform designed to empower businesses to generate high-quality, royalty-free music instantly, streamlining creative processes and unlocking limitless possibilities for marketing, advertising, podcasts, games, stores and more.
🔹 Goal:
To optimize AI operations and model deployment for scalable, efficient and low-latency music generation.
🔹 Solution:
Leveraging Nebius’ infrastructure and Kubernetes, Wubble built a scalable system for managing workloads and deployments.
🔹 Results:
The company achieved high-capacity inference, QLoRA adaptation and faster audio analysis pipelines. These advancements reduced the time to first token and ensured reliable performance, while integration with GCP enabled robust scalability and efficient resource utilization.