Too many people get stuck before their first agent is even live.
The tooling is powerful, but the path to getting started is still too hard for most users.
We’re building Secondmate to make onboarding simpler, reduce setup friction, and help people get agents running faster.
the biggest onboarding issue with openclaw right now is that most people get stuck before they even run their first agent.
especially on discord, which is frustrating because discord is genuinely one of the best platforms for running a swarm.
and to be fair it is complicated if you have never used discord before or if you are not technical enough to get through the setup.
which creates a huge gap.. on one side you have people experimenting with every feature and literally applying everything on their swarm, on the other side you have people who cannot even get a single agent running.
been building with my mate @hsoumix a solution where you can literally install openclaw on whatever infrastructure you want and have your swarm running without fighting the setup.
starting with discord first and expanding to other platforms.. telegram, slack.. etc
and it goes way beyond just getting openclaw running.. we are talking memory, built-in features, the full experience. not just a setup wizard..
waitlist is open and we are locking in something for the early ones that will not be available later.
https://t.co/G03BHu6h6T
this is how to run claude fable 5 as your architect ( 20$ sub only ) + gpt 5.5 codex as your builder..
full system below:
the loop is : fable thinks... codex builds , the repo remembers and you judge, that simple..
the point of all this is that we are taking advantage that 5.5 is on a sub and it's fast enough, especially with /goal, and we using latest Anthropic model to be the judge/guidance..
step 1
>create the memory (one time): make docs/HANDOFF.md in your repo.
>codex updates it after every work session: what was built, what was decided + why, open disagreements, next slice. this file is why 30 min of fable is enough ..it reads state instead of asking you questions.
step 2 paste this to fable (every session)
>you are the ARCHITECT for [project]
>gpt 5.5 codex is the BUILDER
>you never write implementation code.
>your jobs:
(1) read the handoff below
(2) rule on every disagreement the builder raised: accept/reject/modify + one line why
(3) judge any results RAW against the gates in the docs and ignore the builder's narrative
(4) write the next slice spec: small enough for one PR, hard acceptance criteria, explicit out-of-scope, and force the builder to verify APIs/formats against reality before coding
(5) flag scope creep and goalpost-moving.. be blunt. disagree with me. end with a paste-ready block for the builder.
step 3 paste fable's block to codex with this /goal
/goal: execute the architect spec. rules:
PHASE 0 before any code, reply with your plan + every disagreement you have, with reasons, citing real files in the repo. silent compliance = failure. silent scope additions = failure.
PHASE 1 freeze shared contracts (schemas/interfaces) in docs/ first; after freeze they're read-only for everyone including you.
PHASE 2 spawn max 3-4 lane agents on modules that don't import each other, plus ONE reviewer agent that never writes feature code: it checks every lane against the spec + tests + frozen docs and returns APPROVE or a numbered defect list. nothing merges without approve. then: commit + push each slice, update docs/HANDOFF.md with raw results only tables and numbers, no interpretation, no 'promising'. verdicts belong to the architect and the human."
step 4 repeat codex works hours.. you spend fable minutes on judgment only: arbitration, evidence review, next specs, kill/continue calls. one fable session per work block.
the 5 rules that make it actually work
>repo docs are the memory not in HANDOFF.md = didn't happen
>the builder never grades its own work
>disagreement is mandatory
>freeze success criteria BEFORE results exist, never edit after
>spend architect time on judgment, builder time on typing
>the architect is the edge and the builder is the hands. the repo is the brain.. think of it that way..
bookmark this. you will need it.. you really wont need to pay hundreds in API tokens if you do this way
hi @premium@x posting this for a friend who just got banned, his account is @jumperz, if you can look at it would really appreciate it:
hey quick note in case someone from X sees this
I got suspended during Creator Revenue Sharing onboarding after a Stripe account mismatch
I noticed it immediately, stopped, didn’t complete onboarding, no payouts happened, and reported it to support
the issue is the onboarding flow got stuck there was no option to go back, reset, or unlink the account, so there was no way to fix the mistake from my side
it looks like that ended up triggering an authenticity flag
this seems like a misunderstanding caused by a technical onboarding issue, not misuse
would really appreciate a manual review if possible
🙏
almost a month and half of using discord as my orchestration layer and It was best decision i’ve made honestly
>health , tracked
>both businesses , tracked
>socials , finally consistent
>finances expenses, inflow all tracked
>learning, compounding
so everything just stacking..
and I think most people struggling with discord orchestration fall into 2 buckets:
>they never start (yeah discord is messy at first)
>they quit before anything compounds
no data layer, memory or even shared context..so nothing sticks.
PS : Discord got too good when you add discrawl
Discrawl + discord is seriously an insane combo..
It’s like having a compounding layer and a platform that almost made for agents..
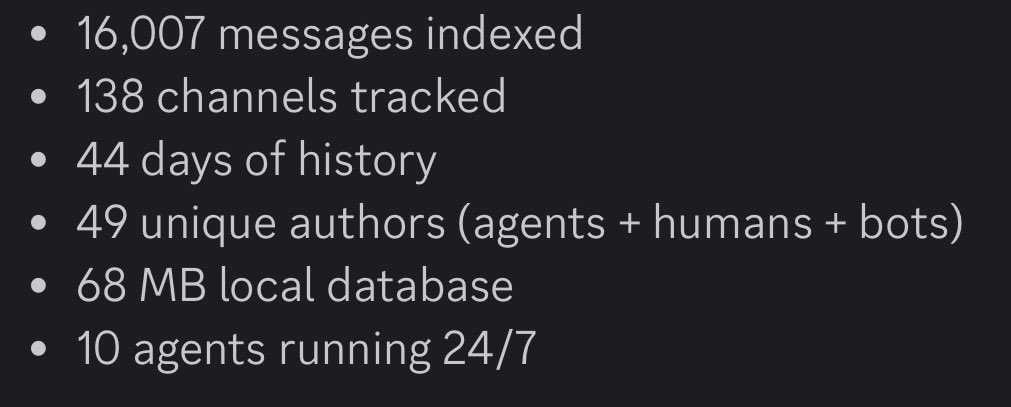
with discrawl every message, channel and thread crawled into a local sqlite database.
so basically, I have 44 days of decisions, tasks, conversations and agent outputs all queryable.
and the crazy part is whatever i plug into it .. analytics or a new agent it’s not starting from zero but it’s starting from 44 days of structured context..
now imagine how many people wouldn’t get to this point just because setting up openclaw + discord as infrastructure is frustrating at first..
the gap between someone sitting on months of compounded data about their habits, decisions, progress and someone who never even gave it a chance is only getting wider..
The number one reason people quit OpenClaw is not the tool itself.
It is the setup. 20+ steps before your first agent even runs. Non-technical people get lost immediately.
Technical people who are new to this still spend hours debugging things that should just work..
We watched it happen too many times, and we removed that wall entirely.
decide what your agents do, what they're called, how they behave then install in 1 minute.
discord now, slack and telegram next.
What you get out of the box:
>agents, ready to run
>memory, already configured
>built-in features
>everything connected
go live with a few clicks instead of broken steps, missing configs, and many errors.
First access is open.
This should make it easier to setup your Openclaw + discord agentic workflow, will give you a head start and set you on the right path while abstracting most of the complexity behind a couple of button clicks, currently the onboarding is done in less than 5 minutes.
been building something cool for anyone who couldn’t get their agents live
openclaw + discord setup… simplified and only few clicks instead of a lot of steps
basically full infra that get you started with your agents..
also, early birds will have an advantage and
you probably want to be one of them .. more coming soon!

















![jumperz's tweet photo. this is how to run claude fable 5 as your architect ( 20$ sub only ) + gpt 5.5 codex as your builder..
full system below:
the loop is : fable thinks... codex builds , the repo remembers and you judge, that simple..
the point of all this is that we are taking advantage that 5.5 is on a sub and it's fast enough, especially with /goal, and we using latest Anthropic model to be the judge/guidance..
step 1
>create the memory (one time): make docs/HANDOFF.md in your repo.
>codex updates it after every work session: what was built, what was decided + why, open disagreements, next slice. this file is why 30 min of fable is enough ..it reads state instead of asking you questions.
step 2 paste this to fable (every session)
>you are the ARCHITECT for [project]
>gpt 5.5 codex is the BUILDER
>you never write implementation code.
>your jobs:
(1) read the handoff below
(2) rule on every disagreement the builder raised: accept/reject/modify + one line why
(3) judge any results RAW against the gates in the docs and ignore the builder's narrative
(4) write the next slice spec: small enough for one PR, hard acceptance criteria, explicit out-of-scope, and force the builder to verify APIs/formats against reality before coding
(5) flag scope creep and goalpost-moving.. be blunt. disagree with me. end with a paste-ready block for the builder.
step 3 paste fable's block to codex with this /goal
/goal: execute the architect spec. rules:
PHASE 0 before any code, reply with your plan + every disagreement you have, with reasons, citing real files in the repo. silent compliance = failure. silent scope additions = failure.
PHASE 1 freeze shared contracts (schemas/interfaces) in docs/ first; after freeze they're read-only for everyone including you.
PHASE 2 spawn max 3-4 lane agents on modules that don't import each other, plus ONE reviewer agent that never writes feature code: it checks every lane against the spec + tests + frozen docs and returns APPROVE or a numbered defect list. nothing merges without approve. then: commit + push each slice, update docs/HANDOFF.md with raw results only tables and numbers, no interpretation, no 'promising'. verdicts belong to the architect and the human."
step 4 repeat codex works hours.. you spend fable minutes on judgment only: arbitration, evidence review, next specs, kill/continue calls. one fable session per work block.
the 5 rules that make it actually work
>repo docs are the memory not in HANDOFF.md = didn't happen
>the builder never grades its own work
>disagreement is mandatory
>freeze success criteria BEFORE results exist, never edit after
>spend architect time on judgment, builder time on typing
>the architect is the edge and the builder is the hands. the repo is the brain.. think of it that way..
bookmark this. you will need it.. you really wont need to pay hundreds in API tokens if you do this way](https://pbs.twimg.com/media/HKd1xT-WYAAvzZn.jpg)