Do something different this weekend.
Become a PRO in AI Model Fine-tuning.
Paste this prompt in Codex/ChatGPT/Claude/Grok.
"You are an expert AI engineer and teacher.
Your job is to teach me modern LLM engineering and fine-tuning concepts from beginner to advanced level using very simple daily-life language.
Teach me step-by-step like a real mentor. Assume I am smart but new to the topic.
Foundations:
- LLM basics
- How AI models work
- Tokens
- Tokenization
- Context windows
- Embeddings
- Transformers
- Attention mechanism
- Parameters
- Training vs inference
- Open-source vs closed-source models
Datasets & Training:
- SFT datasets
- Instruction tuning
- Preference datasets
- Synthetic datasets
- Data curation
- Dataset cleaning
- Dataset formatting
- Fine-tuning basics
- Continued pretraining
- Hallucination reduction
Fine-Tuning:
- LoRA
- QLoRA
- DPO
- RLHF
- Quantization
- Model checkpoints
- Adapter tuning
- GGUF models
Inference & Optimization:
- KV cache
- Flash Attention
- Speculative decoding
- Inference optimization
- Model serving
- Batch inference
- GPU basics
- VRAM basics
- Latency vs quality tradeoffs
Local AI Ecosystem:
- llama.cpp
- Ollama
- vLLM
- MLX
- Hugging Face
- Unsloth
- Axolotl
- PEFT
- TRL library
RAG & Memory:
- RAG
- Vector databases
- Chunking
- Retrieval pipelines
- AI memory systems
- Semantic search
Agents & Workflows:
- Prompt engineering
- System prompts
- Tool calling
- Function calling
- AI agents
- Agentic workflows
- Multi-agent systems
- Browser agents
Model Types:
- VLMs
- SLMs
- Dense models
- MoE models
- Coding models
- Reasoning models
Deployment:
- Local inference
- On-device AI
- API serving
- Cloud GPUs
- Edge AI basics
Evaluation:
- AI benchmarks
- Human evals
- Cost-per-token analysis
- Speed benchmarking
- Quality benchmarking
Real-World Skills:
- Building chatbots
- Building AI copilots
- AI automation
- AI SaaS workflows
- AI coding workflows
- AI orchestration systems
- AI product thinking
Start from the absolute basics and gradually make me advanced.
Rules:
- Use simple English only
- Avoid academic jargon unless necessary
- Explain every difficult word in plain language
- Use real-world analogies and daily-life examples
- Use small code snippets when useful
- Show practical use cases
- Compare concepts side-by-side when helpful
- Teach from fundamentals first, then advanced concepts
- At the end of each topic:
- give a short summary
- give a simple mental model
- give beginner mistakes to avoid
- give a small exercise/project
I want deep understanding, not memorization."
Thank me later.
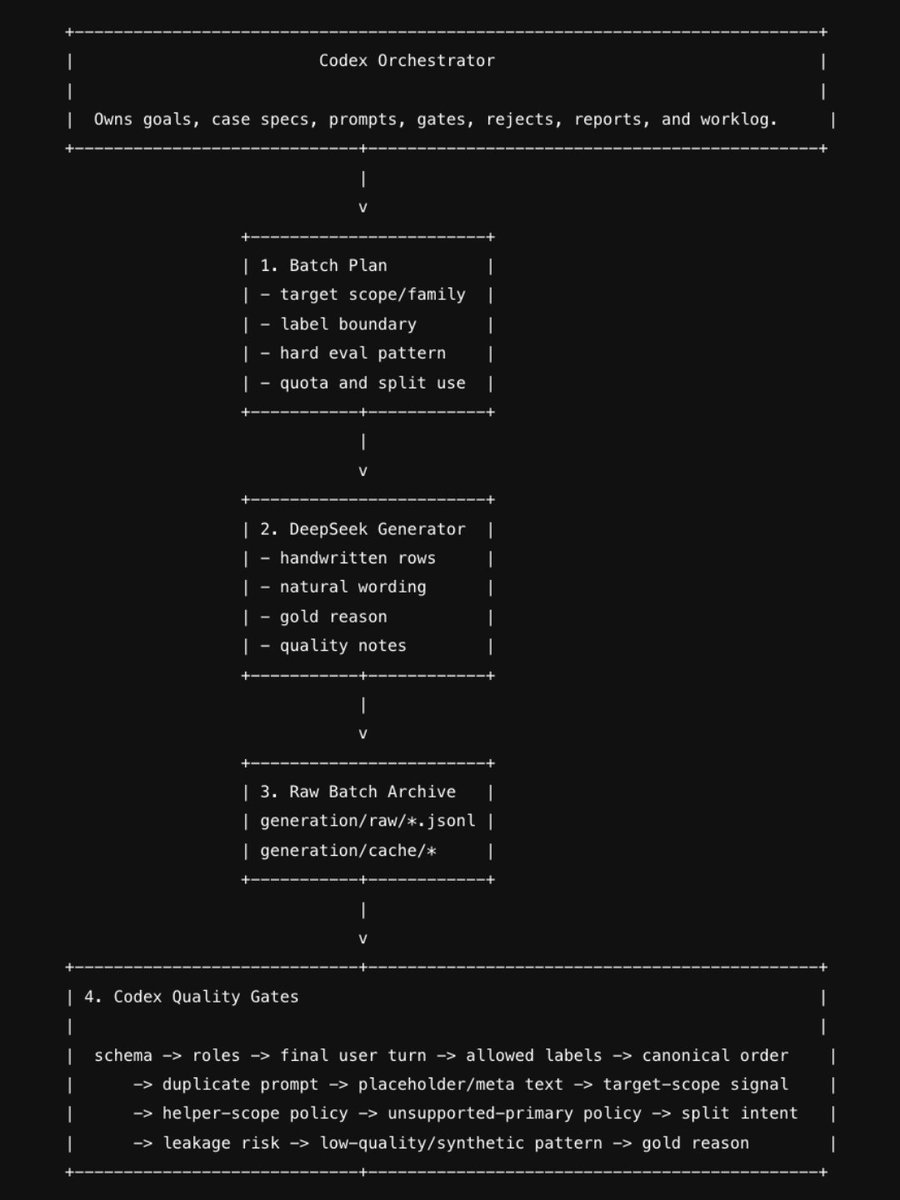
Here's my Fine-tuning Dataset Generation Pipeline:
> Codex 5.5 as an Orchestrator
> Deepseek v4 Pro as a Generator
In simple words, I use Codex as brain and Deepseek as muscle to handcraft every single dataset row.
This "handcrafting" is what brings high quality. Synthetic dataset generation (with Python scripts via paraphrasing) is not hard but it generates low quality data.
Low quality data = Low quality model performance
But with this pipeline Codex designs a complete workflow for deepseek. So deepseek doesn't use it's own thinking, but just execute each batch by following Codex's specs.
After generation, each batch goes through strong "Quality Gates" built by Codex to filter out all weak rows and only keep the high quality rows.
The best part: With each batch codex improves its generation specs for deepseek and the quality gates. This loop makes the pipeline faster, cheaper and brings better and better data.
Deepseek v4 pro is dirt cheap right now. I generated 100M+ parameter dataset for $80 and used 95% of my weekly Codex 20x pro subscription.
This pipeline is completely autonomous after I approve the Codex Workflow.
Just paste this image in Codex and ask it to make a dataset generation pipeline for your use case (explain that in depth: what model you'll be fine tuning? You have raw dataset or no? etc) and rest Codex will take care.
Let me know your experience.
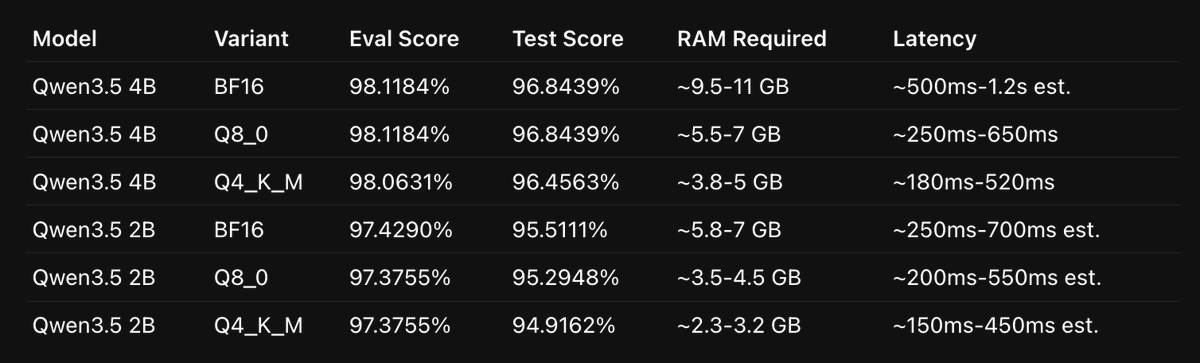
Qwen 3.5 has the best SLMs to fine-tune!
Its 4B model is really smart if you train it on a well structured dataset.
I fine-tuned the model on a 135M dataset generated by Codex 5.5 + DeepSeek v4 Pro.
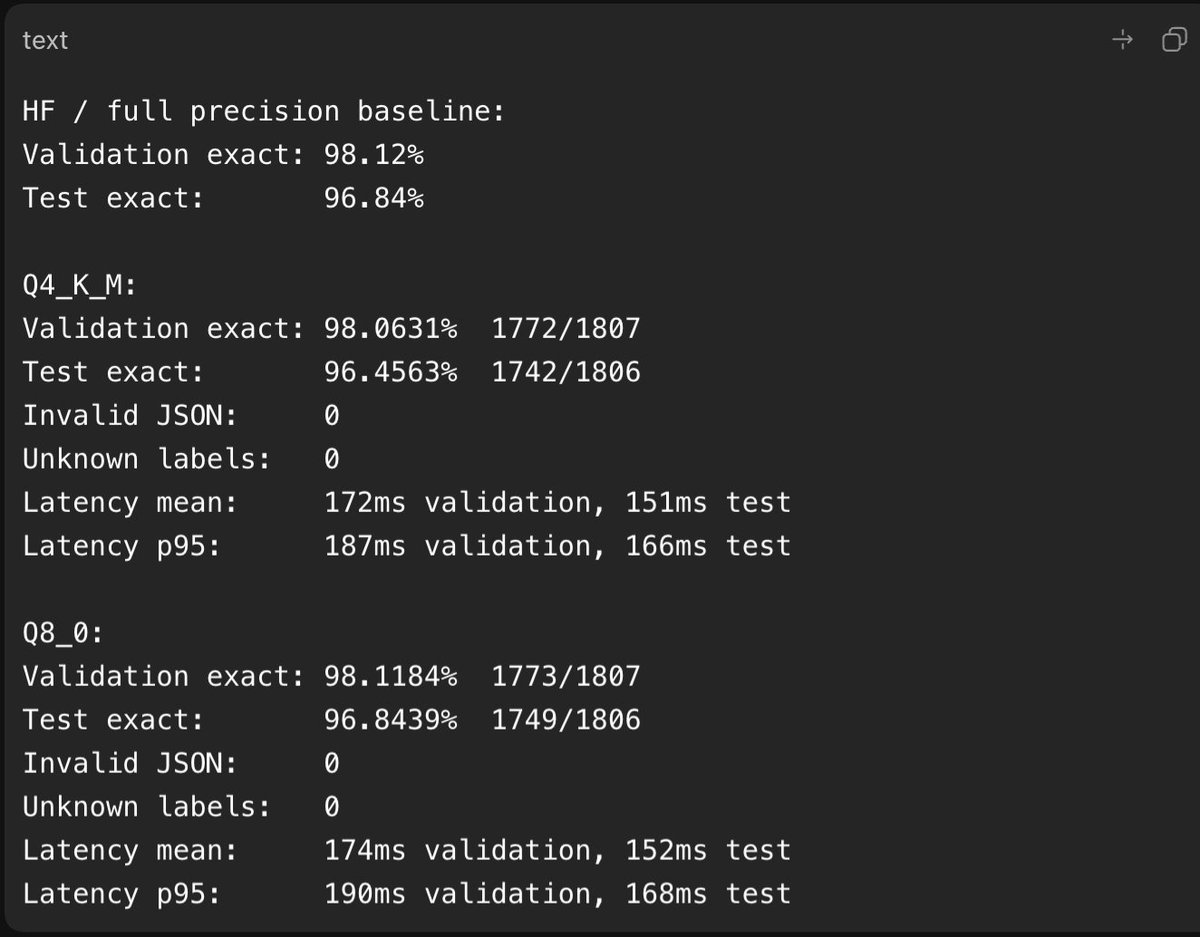
I achieved 96%+ accurate results with Qwen 3.5 4B.
And 95% on Qwen 3.5 2B (that only requires 3.5GB RAM).
For context, on the same pipeline:
> Sonnet 4.6 achieved 89%
> GPT 5.4 Mini achieved 85%
> Haiku 4.5 achieved 72%
I don't trust evals, so I ran a 7000+ row hard-boundary test, and the results of Qwen 3.5 were consistent.
A 4B fine-tuned model beating a 20x bigger model in accuracy and latency is no joke.
It cost me $173 in total to generate the dataset and cover the cloud GPU cost to fine-tune both models.
I said this before, and I'll say it again: not everything requires a 1T-parameter LLM. We need ELMs (Expert Language Models) that are specialized for one domain only.
ELMs > LLMs.
I'll be writing more about how SLM fine-tuning works. So stay tuned.
If you love fine-tuning open-source models (like me), then listen.
> Start with 1B, 2B, 4B, and 8B models. (Don't start with a 27B model or bigger at first.)
> Use WebGPU providers. I use Google Colab Pro for any model smaller than 9B. A single A100 80GB costs around $0.60/hr, which is cheap. Enough for small models.
> Don��t buy GPUs unless you fine-tune 7 to 10 models. You'll understand the nitty-gritty in the process.
> Use Codex 5.5 × DeepSeek v4 Pro to create datasets. Codex to plan, DeepSeek v4 Pro to generate rows.
> Use Unsloth's instruct models as a base from Hugging Face. Yes, there are others too, but Unsloth also provides fast fine-tuning notebooks.
> Use Unsloth's fine-tuning notebooks as a reference. Paste them into Codex, and Codex will write a custom notebook with the configs you need.
> Spend 1 day learning about:
- SFT (supervised fine-tuning)
- RL training (GRPO, DPO, PPO, etc.)
- LoRA / QLoRA training
- Quantization and types
- Local inference engines (llama.cpp)
- KV cache and prompt cache
> Just get started. Claude, Codex, and ChatGPT can design a step-by-step plan for how you can fine-tune your first AI model.
Future tech is moving toward small 5B to 15B ELMs (Expert Language Models) rather than general 1T LLMs.
So fine-tuning is an important skill that anyone can acquire today.
Tune models, test them, use them. Then fine-tune for companies and make a career out of it. (Companies pay $50k+ to fine-tune models on their data so they can get personalized AI models.)
Shoot your questions below. I'll be sharing in-depth raw findings about this topic in the coming days.
@sudoingX I'm trying the qwen 3.6 27b dense Q4 on dual RX 9060 XT, got around 16 t/s
due to hard to get a 3090 now in my country
any suggestion to increase the token speed with my setup ?
I got 50 t/s on the MoE model, but I want to use the dense model