Looking for all people described in #Wikidata?
Do not even try to run a SPARQL query...
Instead, give a look to the free datasets published on our website!
Then register and run your own custom extraction!
https://t.co/wmeV1WT5L0
→ @SemanticBuild is a mirror of Wikidata, the world's largest public knowledge graph.
It provides a SPARQL endpoint with no hard limits and tools for the generation, saving, and sharing of large datasets.
It's a vital component for data platforms, semantic SEO strategies, and more.
🔴 Live on Dev Hunt → https://t.co/blMqMwstRw
Our website has a new section dedicated to free downloadable extraction samples.
The first one includes all humans in #Wikidata (including birth and death dates), a dataset often required but too large to be obtained with a single #SPARQL request.
Enjoy!
https://t.co/uAxczCrg0N
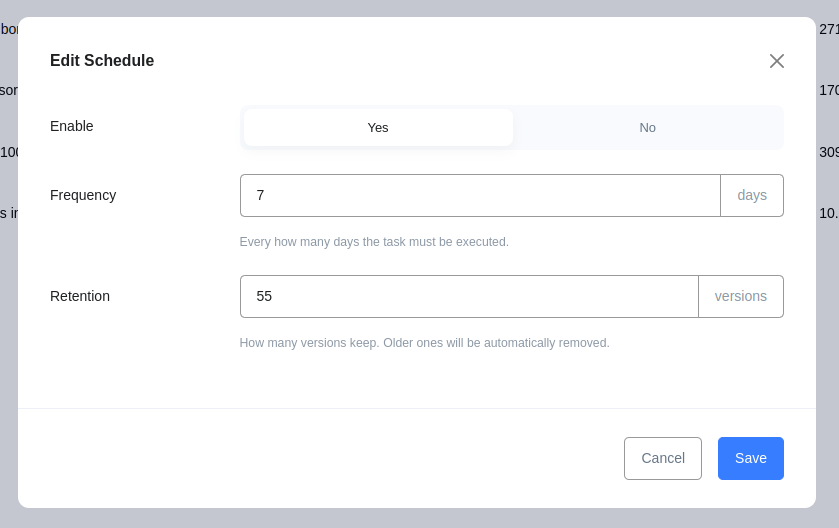
On SemanticBuilders it is now possible to schedule the execution of queries and extractions, to automatically collect data over time for further analysis, comparison, research, or keep up-to-date your data sources.
Not all requests may fit a single #SPARQL query.
It is highly recommended to parse a #Wikidata dump, or just use the Semantic Builders' Extract Tool.
https://t.co/wmeV1WTDAy
Semantic Builders' API is out! It is now possible to retrieve own saved queries and extractions with a simple GET request: check the documentation for more details.
https://t.co/Fxcs5f0tN3
Semantic Builders is still in beta! Register now to have 10€ of free credit, and discover how much you can obtain with so little!
https://t.co/pH5n2eoLmK