I believed when it was math, not marketing.
When $TIG was misunderstood, not valued.
It’s not just the backbone of AI, it’s the infrastructure of intelligence itself.
I will pin this and look back at it, not if, but when it reaches billions.
Update on my $TIG algorithm submission.
Last time I posted, c008_a001 was sitting at push pending.
It's active now.
Live in the protocol. Benchmarkers can pick it up. The energy arbitrage challenge — the one where average profit went from 22,980 to 183,194 against the baseline.
Adoption is at 0% right now. That's expected. The frontier is competitive and the serious researchers have been at this longer than me.
But it's in.
A guy with no dev background, no computer science degree, just docs, curiosity, and AI tools that anyone can access — has a live algorithm competing in an open protocol alongside professional researchers.
That's the story I keep coming back to.
$TIG doesn't care about your credentials. It cares about your output.
If you've been sitting on the sidelines thinking this is only for technical people — it's not.
The docs are there. The tools are there. The protocol is open.
c008_a001 is proof.
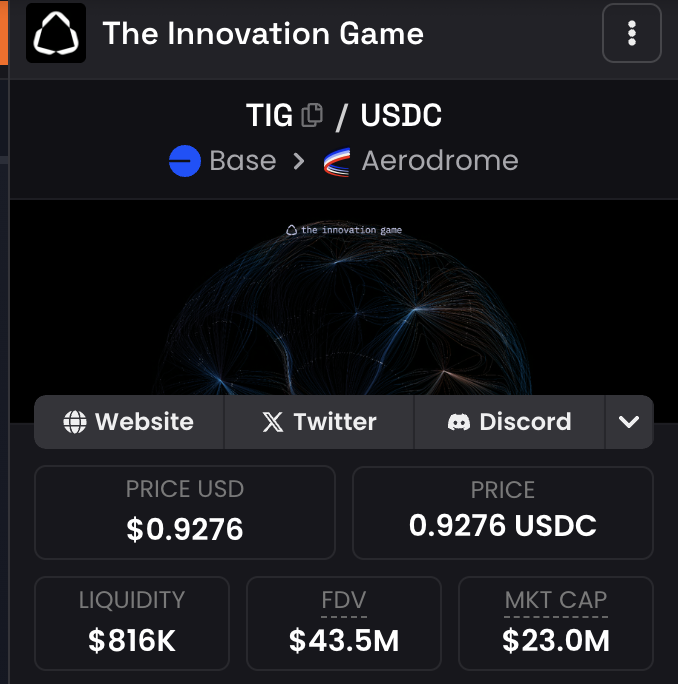
$TIG
This is amazing to see!
It proves a major shift has taken place: a non technical person can participate in an AI agent swarm to optimise an algorithm
Imagine that at global scale, pointed at thousands of problems at once!
It introduces one question though: who pays for the compute?
Donations/philanthropy can only go far.
For this to work at a global scale it has to become an industry, where people move from donating spare compute to doing it full time because they get paid for it.
And it all HAS to stay open, if each agent in a swarm can see and build off each other's work, no private lab can keep up with it!
This is how you can scale from people donating their laptop overnight to teams building entire data centers to join swarms.
And that is exactly what TIG has spent three years building.
What are the ingredients you need?
You need:
Price discovery (which TIG solves via proof of work)
AND
A mechanism to capture value (which TIG solves via its dual licence)
A deeper dive as these are often parts of TIG which are hard to grasp
How the price discovery work:
- Algorithms currently have no way of being priced, so what TIG does is let anyone "run" (benchmark) them.
- Benchmarkers choose the best ones because they get paid for valid work, and a better algorithm lets them produce more of it per unit of compute, so picking the best one directly earns them more.
- The algorithms benchmarkers actually choose to run is the price signal.
- Adoption is the market revealing which algorithm is best.
- This is the same class of fix Paul Milgrom won a Nobel prize for: using computation to make a market function where it otherwise cannot.
How the dual licence works
- TIG licences the winning algorithms.
- The algorithm is free to use if you share your data, but companies that want to keep their data closed pay to license it.
- 100% of that revenue flows back into the token and that flows back to the benchmarkers and innovators to fund more open innovation
We've posted this before - but if there is one video your're gonna watch to understand how this space plays out, make it this!
This thread from @tigfoundation is worth your full attention.
Three reasons why amateurs beat specialists at algorithm discovery — explained by @Dr_JohnFletcher on the weekly Space:
Experts over-trim their search space. Years of experience teaches them what not to try. AI doesn't know what it's not supposed to try. So it tries everything.
Experts don't want the field to change. The best people at doing the work are often the worst at predicting where it goes. They're sitting on top of it with something to lose.
Outsiders don't know the rules. The same reason a first-time poker player cleans out the table. No conditioning. No learned limits. Just pure exploration.
This is exactly what happened in the Prometheus beta.
Non-technical participants. Half the features missing. First swarm ever run.
Beat every public algorithm anyway.
John once put five years on producing a single state-of-the-art algorithm. The first arrived inside a year. Another came months after that.
His own words: "It's now a scalable process. An industrial process."
Once machines beat humans at producing algorithms the thing turns into a factory.
That factory is being built right now.
$TIG
Everyone agrees algorithms are the prize. Last week TIG showed what that looks like in practice.
A handful of people spent the previous weekend running algorithm mining via Prometheus
Almost all of them were NOT mathematicians or engineers.
It was (and still is) in early, half the features missing, and we did not expect it to beat anything.
At the end of the weekend the swarm consisting of 138 agents and 33K iterations had mined an algorithm that beats a live TIG mainnet algorithm by 5.92%.
There's a project not on VC radars yet because it's so unique and early. @tigfoundation is a factory for algorithmic IP.
Within weeks people can join into LLM swarms that will push algorithms forward which then will get licensed for commerical use.
Worth spending some time on.
$TIG will directly benefit from AI solving problems in math and science.
(reposting as I included wrong link!)
Thanks. Yes, it’s encouraging that open weights models seem to be gaining on private ones (at least the private ones they let the public use!)
My main concern is that SOTA in AI-assisted algorithm discovery (AlphaEvolve, or whatever google have now) is more elaborate than just an LLM, and Google may have a significant lead in this capability.
If this is made available over API, it could become indispensable to researchers working in this area, whereupon they expose their know-how to capture; knowhow being, in this context, strategies that researchers try when they get stuck (knowhow is largely uncodified, so not in current training data).
A “data flywheel” effect may not be out of the question. I wrote about this here if you are interested! https://t.co/8TWELsYUwv
worth reiterating this because the market still hasn't processed it.
GV, NVIDIA, AMD, Greycroft just paid $4.65 billion for one closed-source bet on AI-generated algorithms. no product. no revenue. 25 employees. one team, one country, one cap table.
that is not retail. those are the most informed allocators on the planet. they don't write checks that size on a thesis they think is wrong.
the thesis is settled. AI-generated algorithms are the path. the only open question is which structure captures the upside.
TIG runs the same thesis with three things Recursive structurally cannot have:
anyone can contribute. not 25 employees in two cities anyone with a laptop, a tacit-knowledge file, and a reason. the talent pool is the planet, not a payroll.
contributors keep their edge and get paid. tacit knowledge never leaves your machine. royalties route on-chain to whoever discovered the algorithm, every time it ships commercially, forever. that contract does not exist anywhere else on earth.
the algorithms stay open. Recursive must keep its outputs proprietary or the moat dies. TIG must keep them open or the market dies. opposite constraints, opposite outcomes. only one of those scales without a ceiling.
this is not a token bet. this is the structural alternative to one company owning the math underneath modern civilization. that question gets decided once. you either positioned for it or you didn't.
generational doesn't mean a 10x. generational means the answer to a question this size only gets priced once. and the priced once happens before the public catches on, not after.
$TIG
Another day, another (closed) startup.
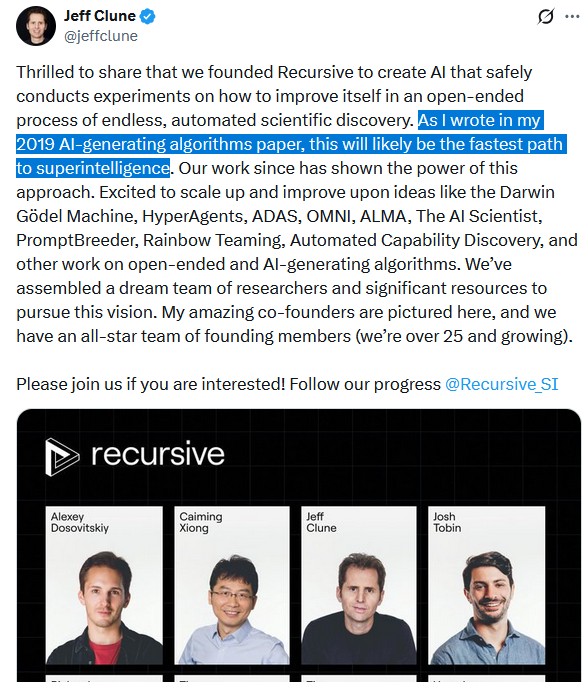
Recursive Superintelligence came out of stealth today, is valued at 4.65 billion and investors include Nvidia and Google (ofc)
Their bet: We get to superintelligence by using AI to generate algorithms.
One of their founders, Jeff Clune, published the AI Scientist paper in Nature this March.
AI that runs the whole scientific method on its own.
His announcement tweet says Recursive will "scale up" exactly that work.
Universities and labs do the foundational, citable research, get the credit, and then the for-profit scales it up into something proprietary.
Algorithms are how we get to superintelligence, and if a closed company gets there first, everyone else is locked out of the most important technology ever built.
The algorithms HAVE to stay open.
Something big just dropped in the $TIG Discord.
The Prometheus private beta just posted results — and nobody saw this coming.
Their own expectations: don't beat any leading $TIG algorithms. One maths researcher gave it "close to 0% chance."
The Energy challenge swarm generated an algorithm 6% better than the current winner.
First swarm ever run. Half the features still missing. Every participant was brand new to Prometheus.
It worked anyway.
For context on what this means:
When an algorithm is submitted to $TIG it takes four weeks to go live — two weeks private, then admitted into the game and made public. They've already tested against every public algorithm. It beats them all. Private submissions are still unknown.
How the rewards work:
The Prometheus team, as host of the swarm, will submit the algorithm. If it wins, rewards get distributed to every participant who got at least one agent running during the beta.
Next swarm date gets announced Monday. GPUs potentially incoming.
This is what decentralised algorithmic discovery actually looks like in practice.
$TIG #Algorithms