Super interesting!
"Reassessing Central Bank Reputation: Beyond Long-Run Expectations" by Tomás E. Caravello, Alex Carrasco, and Pedro Martínez-Bruera.
"We study the implications of uncertainty about a central bank’s preference for inflation stability for monetary policy design. A hawkish reputation, defined as a reputation for placing large weight to inflation stabilization, reduces stabilization costs by dampening the pass-through of shocks to short-run inflation expectations. Because the private sector learns from the bank’s policy actions, the optimal response to cost-push shocks is more aggressive than that of a myopic policymaker: the bank internalizes the value of its reputation. Furthermore, the bank treats reputation as an asset: it invests in it when perceived as dovish, and spends it when perceived as hawkish. Using cross-sectional variation in U.S. private forecasts, we find evidence consistent with these mechanisms. Quantitatively, welfare gains from the optimal policy are larger during the Great Moderation than during the Great Inflation, and delegating policy to a conservative but myopic central banker, as in Rogoff (1985), closely approximates the optimal policy."
https://t.co/AiqU1iGCUY
Indeed, this article feeds a narrative void of content. I add that there’s tons of research by people who spend their lives thinking about how poverty, environment, health, ed, etc.
Predominantly, complaints are about lack of funds, they complain about ineffective use of funds.
I don't know what Piketty, Stiglitz, and co. are smoking. Global poverty rates have never been lower. Progress on basic global health and wellbeing measures has been amazing over the past few decades. "End of the road"?!? Come again!?!
https://t.co/b5GHT6YXrN
Leo a un Profesor de una prestigiosa universidad extranjera decir que aquí somos "imitadores criollos de Nate Silver" y que nada está dicho hasta que hable el JNE.
Es cierto que el JNE tiene la voz final.
Sin embargo, yo no veo razón para que Nate Silver empiece a imitar métodos peruanos. Mis paisanos y congéneres no tienen, inherentemente, nada por debajo de ningún extranjero.
Podemos ser también pioneros.
Esta elección, que comenzó con proyecciones a nivel departamental con excel, ahora incluye algoritmos de IA/OCR para reconocimiento de actas JEE, regresiones mesa por mesa, y (ví por ahí) imputaciones por cosine similarity.
La necesidad es la madre de la invención. Increíble 🎉.
Los modelos ya apuntan en una dirección y confío en la ciencia detrás de ellos. De concretarse el resultado, lo relevante es la estrategia de comunicación: cómo anticipar y mitigar los impactos de una probable movilización masiva.
¿Cansados de leer sobre política? 😡
Despeje su mente 😂
Mi artículo recientemente publicado "The credit-to-GDP gap revisited: A link to instability measures" estará disponible para descarga libre hasta el 25/07/2026.
Enlace: https://t.co/uRvPfWU1o1
En inglés le llaman one trick pony.
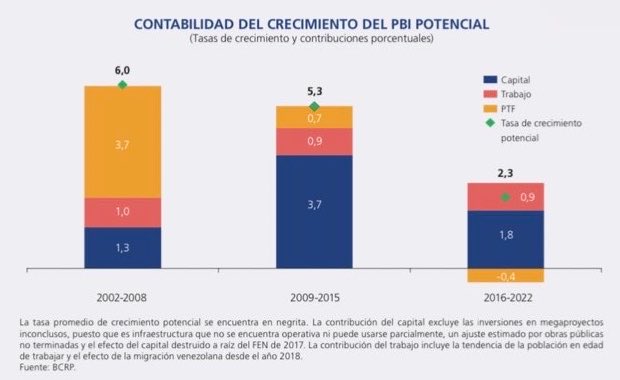
Oscar Dancourt siempre recomienda gastar más.
Ignora que la productividad pasó de sumar 3.7 puntos al crecimiento anual a restar 0.7 puntos.
1/5
This doesn't apply to Di Tella. There, the first macro course you'll face is fully microfounded, using all the tools you learned in Econ 101. Here's a sketch of the syllabus for the course I'm currently teaching, and it's not even for econ students (it's for PolSci students)
The Wold Inequality Dataset is a faulty dataset. It is not based on tax/financial sources for most countries. Instead, authors extrapolate a few datapoints from Forbes leading to absurd yearly changes.
Should not be quoted: More information is not better, if it is misleading.
No hay razón ni marco legal para que se hagan elecciones complementarias y mucho menos se repitan las elecciones generales. El impacto, producto de la ineptitud de la ONPE no mueva la aguja.
El mandato popular es elegir entre Keiko y uno de los dos que se disputan el 2do lugar.
You are an economics professor. Perhaps you should ask your students what a Central Bank should do when a government runs a fiscal deficit of 6.5% of GDP when the economy is growing and inflation is 5.5%.
🇵🇪 #Perú | La posible sucesión en el liderazgo del @bcrpoficial abre una discusión clave: cómo preservar hacia adelante la estabilidad institucional.
Lo analiza @Shin_Mkto en @elcomercio_peru en este artículo de prensa https://t.co/H36p0V7ddV 📰🗞️
Muy complacido de ver a 8 colegas del @BancoRepublica en el top 10 de autores con más descargas en el mundo de @repec_org durante marzo de 2026. Una muestra de la calidad del equipo técnico del Banrep
A point that is sometimes overlooked is that PDEs in physics and economics have a subtle but important difference.
When a physicist solves the Schrödinger equation (see my slide below), the potential is given. The coefficients of the equation are part of the problem statement. You pick your grid, refine your mesh, and the equation never changes on you. Better numerics give a better approximation to a fixed target.
In economics, this is not the case. Look at the Hamilton-Jacobi-Bellman equation for the neoclassical growth model (also slide below). The drift of capital depends on a derivative of the value function, the very object you are trying to solve for. The “coefficients” of the PDE are endogenous to the optimal choices of the agents. This is what @UncertainLars and Sargent referred to as the cross-equation restrictions implied by optimizing behavior.
This is what @MahdiKahou and I call the “equilibrium loop”: improving your approximation changes the policy, which changes the dynamics, which changes where in the state space the economy spends its time, which changes where your approximation needs to be accurate. You are not chasing a fixed target with a better net. Moving the net moves the target.
This has serious consequences for computation. You cannot just borrow neural network architectures from deep learning in the natural sciences. The loss function comes from equilibrium conditions, not from labeled data. The evaluation points are not given. Instead, they are regenerated each epoch from the current approximation. Ignoring it is why you often get solutions that look good on a training set but fall apart in simulation.
📌 We invite you to the 57th Annual Conference of our Society, which will be held on 9–11 September 2026 at @LancasterUni, UK. Please submit your paper via Conference Maker, at https://t.co/ltI5nWJvNn, by 29 May 2026, with notification by 24 June 2026.
@lorenzarossi3
1/2