Have LLMs become supervised learners (once again)?!
In our new paper, we argue that current LLMs’ post-training methods have effectively reverted to the "pre-train then fine-tune" era, explicitly tailoring models to desired behaviors.
1/n
MFA is a beautiful visualization, but not only that.
It’s a practical tool:
competitive localization and better steering, while revealing that concepts live in regions, not just single directions.
Grateful I got to contribute to this with an awesome team!
🤔Can an LLM "unconscious" feel a lie bubbling up before it speaks?
🤔And what mysteries hide in its linear space of uncertainty?
Thrilled to share our new paper:
“Pre-trained LLMs Learn Multiple Types of Uncertainty” (@roicohen9•@OmriFahn•@GerardDeMelo)
https://t.co/XbAc6ucXmo
🚨New paper on SLM evaluation🚨
We present SALMon🍣 which is a suite of benchmarks for evaluating how much Speech Language Models model acoustic elements like sentiment or background noise.
Project: https://t.co/cjE2T0LnKz 🧵👇🏻
Which is better, running a 70B model once, or a 7B model 10 times? The answer might be surprising!
Presenting our new @COLM_conf paper: "The Larger the Better? Improved LLM Code-Generation via Budget Reallocation"
https://t.co/Zayq02RFJJ
1/n
I am excited to share my first work: "Dataset Size Recovery from LoRA Weights".
Ever wondered if you could find out how many samples was a model trained on using just its weights? Well now you can!
Project: https://t.co/YL6qs5mVfE
👇
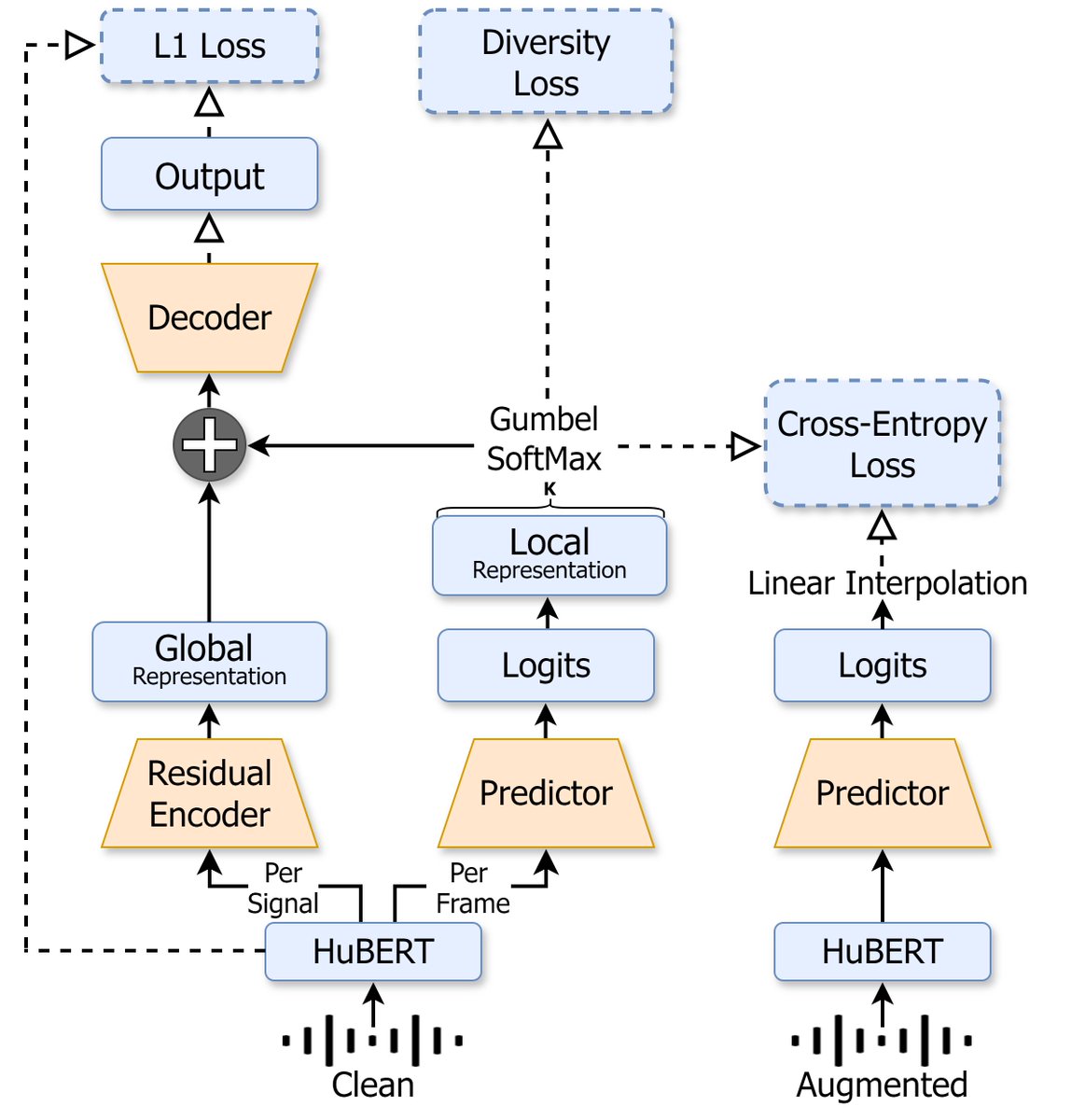
Speech tokenizers are fundamental in building speech LMs. In a recent study we show the common tokenization method (a.k.a “semantic tokens”) is not robust to different signal variations. We then present NAST! a noise aware speech tokenizer
w. @ShovalMessica
Code and models 👇
1/ Commonsense reasoning needs multimodal knowledge, yet current LLMs focus mostly on text, limiting their integration of crucial visual information.
We introduce vLMIG, a method that enhances LLMs' visual commonsense by integrating images into the decision-making process