Usage limits are up, effective today we're:
1) Doubling Claude Code's 5-hour limits for Pro, Max, Team and seat-based Enterprise plans
2) Removing peak hours limit reduction on Claude Code for Pro and Max plans
3) Substantially raising our API rate limits for Opus models
I visited OLA's Cell factory, saw how the cell is made and interview/converse their Factory manufacturing lead, cell R&D lead and COO with tech questions ....
the conversation was pretty interesting to say the least.
You can make your own opinion. I was impressed. Link below.
Claude now connects to the tools creative professionals already use.
With the new Blender connector, you can debug a scene, build new tools, or batch-apply changes across every object, directly from Claude.
Everyone is slowly coming to this realization, and I assure you, no one is running multitudes of agents overnight. No one that is doing anything of substance at least.
There _are_ people pretending to be scientists, or fully caught up in their drug infused AI overdose, that think their slop machines are changing the world. They're not tho, and they're just wasting a bunch of money and compute to create a lot of LoC that will just get thrown away.
The state of the art is still "can we even one shot a production quality patch that we wont regret later", and its rarer than you'd expect based on discourse.
Sometimes when you focus too much on the big picture, you start missing the small things that actually make it work.
“God is in the details” -- Ludwig Mies van der Rohe
Learned it the hard way today.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
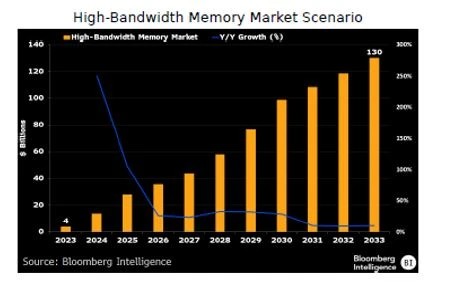
GPU prices are probably heading even higher.
As local AI models improve, more people will want to run them on their own machines.
VRAM costs are already climbing, and manufacturers seem to be reducing consumer GPU production.
Feels like we’re heading into some rough times.
@cachesaur@saltyAom It works great in wsl ,consumes very less ram and is very fast.
But the learning curve is a little moderate , sometimes I rage quit it😅