We’re excited to launch @Signal_65, a new company that will serve the technology industry with testing, performance validation, and data-based consulting. @ryanshrout will serve as our President and GM, with @PatrickMoorhead & @danielnewmanUV on our board. https://t.co/gotaMcJcQU
NVIDIA Is Coming to the PC. Watch Who Suddenly Becomes an Expert.
Over the next few days you are going to see a lot of people on social media "discover" the PC.
They will have strong opinions about the PC ecosystem, about AI on the PC, about the engineering tradeoffs behind a thin and light notebook, and most of them will be forming those opinions for the very first time. The reason is simple. @nvidia now has a voice in this conversation, and that voice pulls a crowd.
Now that doesn't change the fact that this is a real moment. NVIDIA is the 5 trillion pound gorilla in the room, and when a company that size leans into a market, things move. I am genuinely excited about what the N1X and the family of chips around it could bring to the PC, and about how it might push @Windows, and @Microsoft more broadly, in a new direction.
But excitement is not the same as suspending the rules.
I do not believe, as some of the more out-there posts are already claiming, that NVIDIA is about to make every laptop on the shelf irrelevant overnight. Silicon is still bound by physics. Power, heat, and thermals translate directly into performance and battery life, and there is no way around that.
If this turns out to be a GB10-based part as rumored, then there is no magic here that we have not already measured. This includes the @MediaTek CPU based on @Arm and the NVIDIA GPU itself. We at @Signal_65 put the platform through its paces in our DGX Spark work, and the numbers are the numbers.
https://t.co/d6lUdt00iJ
Silicon is also bound by the software around it. Windows 11, Windows on Arm, application compatibility, and gaming support all sit between a great chip and a great experience. That layer does not bend just because a new logo walks into the room.
So does NVIDIA have the engineering ability, and the political weight in this industry, to move things that have been stuck in the mud for years? Absolutely. That is the part I find most interesting.
Here is what that could actually look like. Windows on Arm could finally be treated as a first class citizen. Gaming on Windows on Arm could get a real leg up, because NVIDIA can compel developers to get involved in a way that few others can. And Windows itself could be pushed further into the AI era, beyond the current Copilot+ features, and grow into a leading AI development platform.
Does any of this make Intel, AMD, or Qualcomm irrelevant? Far from it. Intel is getting its legs back under it with Panther Lake. AMD keeps iterating on high performance designs like Strix Halo. And Qualcomm, along with Snapdragon, arguably benefits if NVIDIA is now pulling for Windows on Arm too. A bigger tent helps everyone building inside it.
But remember, be a little careful with that "new" crowd. A lot of the same people will also hand you confident, "informed" views on the data center. Ask yourself whether the take in front of you comes from someone who has actually done the work in this space, or from someone who only got interested because NVIDIA showed up. Those are not the same thing, and the difference matters more right now than it usually does.
This week is going to be very, very interesting. My ask is simple. Balance the excitement with the right questions and the right thinking. A new entrant in this space is going to be good for the consumer and I think it is finally time for a reset of what we mean by the term "AI PC."
See you this week.
At Computex, Qualcomm is introduced @Snapdragon C, a new entry-tier platform built for Windows laptops targeting around $300 (and up), with Acer, HP, and Lenovo signed on and the @Acer Aspire Go 15 leading as the first device.
The positioning is the obvious headline, but an interesting story sits in the architecture. Snapdragon C steps away from the custom Oryon cores that define Snapdragon X and X2 and uses a mobile-derived Kryo design instead. That is the same fundamental move Apple made by dropping an iPhone class A18 Pro into the MacBook Neo. Both companies are taking proven, high-volume phone silicon downmarket to reach a price the flagship laptop architecture was never built to hit.
Snapdragon C is the first Snapdragon PC platform that does not support Copilot+. It still carries an integrated NPU for everyday on-device AI, but I assume it sits below the 40 TOPS threshold that the X series (45 TOPS) and X2 Elite (80 TOPS) clear and its unclear if Microsoft will keep the 16GB memory requirement too. How this translates into "on-device AI" will be an interesting question this summer.
The lineup reads as a clean three-tier stack. Snapdragon C anchors the value segment, the X series covers mainstream premium now as the previous generation, and X2 Elite leads at the top. It is also worth being precise about who C actually competes with. At $300 and up, the more direct fight is less the MacBook Neo and more the Chromebook and budget x86 field, namely Intel N-series, MediaTek Kompanio, and AMD in the entry tier.
The question is price. Chipmakers do not set laptop prices, OEMs do, and the current memory and storage shortage makes a genuine $300 sticker hard to deliver right now. The strategy is sound and the segment is real, but the number that matters is where devices like the Acer Aspire Go 15 actually land on the shelf. That is what will tell us whether Snapdragon C reaches the audience it was designed for.
I've really enjoyed our time working with @Lenovo exploring their AI solutions stack and how they actively work with enterprises on deployment, not only getting to a concept state. This is a good discussion that summarizes one of our recent @Signal_65 papers. https://t.co/T0DrCIXwhl
🤝 @TheFuturumGroup has entered into a definitive agreement to acquire @ETRnews.
This announcement marks an important step in Futurum’s continued focus on decision-grade intelligence for technology leaders, investors, and enterprise decision-makers.
By bringing together Futurum’s analyst expertise, advisory, intelligence, and strategic content capabilities with ETR’s institutional-grade technology spending data, this combination is designed to strengthen the signal organ
Hear directly from @danielnewmanUV and @bmlascolea on what this means for Futurum, ETR, and the future of technology intelligence.
#TheFuturumGroup #ETR #TechResearch
The 2026 @Windows refresh story isn't a marketing claim, it's a measurable performance gap, and it's a large one.
We tested the AMD Ryzen AI 9 HX 465, Intel Core Ultra X7 358H, and Qualcomm Snapdragon X2 against a representative five-year-old laptop running Tiger Lake. In our testing, every 2026 platform delivered between 3.7x and 7.2x the multi-thread CPU performance, with comparable gains in graphics and content creation.
For the 340M PCs sold in 2021 now entering their refresh window, this is the upgrade story.
Full report: https://t.co/k9GqHUdfWT
This build isn't slowing down AT ALL. 😮📈
"...a networking supercycle...traffic without agentic AI was projected to grow roughly 2.5x over the next decade. With agentic AI, that projection jumps to ~9x...even those numbers may prove to be wildly conservative."
That claim @MichaelDell made from the @Dell Tech World keynote stage, breaking even on agentic AI versus cloud APIs in as little as three months and reducing spend by up to 87% over two years, comes from a study my team at @Signal_65 published this week.
Full analysis here: https://t.co/dlVzuL1Zqu
We modeled agentic workloads across general knowledge, sales, and software development on a five-day work week, with publicly available API pricing on one side and Dell workstation and server pricing on the other. Savings scaled with concurrency and model size, with the strongest economics coming from workhorse models in the 30B to 284B parameter range, which is where the bulk of useful agentic reasoning actually runs today.
That is the financial backdrop for one of the most important Dell announcement of the day, Dell Deskside Agentic AI. This is the first time I have seen a major OEM really drive agentic AI on the desk, in the rack, and across the data center under one consistent runtime and security model. @NVIDIA OpenShell now spans the whole Dell AI Factory with NVIDIA, from a Dell Pro Max with GB10 up through PowerEdge XE servers. That continuity is what gives enterprises a path from prototype to production without rebuilding the stack.
The strategic backdrop is the data foundation. Updates to the Dell AI Data Platform around orchestration, search, and a Starburst-powered SQL engine accelerated on NVIDIA Blackwell change how enterprise data gets fed into AI pipelines. PowerRack now brings block, file, and object storage onto one rack architecture with PowerFlex joining Exascale.
Dell is making sure that whatever infrastructure plan you have, they can address. Google Gemini 3 Flash on Distributed Cloud running on PowerEdge XE9780. OpenAI Codex connecting to the Dell AI Data Platform. Palantir Foundry coming on-prem. Reflection and SpaceXAI models landing on Dell infrastructure. Dell Enterprise Hub on Hugging Face expanding to MiniMax-M2.7, DeepSeek V4, GLM 5.1, and Kimi K2.6. Whatever model an enterprise wants to run, Dell wants the on-prem stack to be the answer.
The customer evidence is already in production. Mistral AI training on liquid-cooled PowerRack with NVIDIA GB200 NVL72. Eli Lilly feeding more than 1,000 GPUs at nearly two terabytes per second on LillyPod for drug discovery. Samsung embedding Dell infrastructure across global semiconductor fabs.
Cloud-only was going to hit an economics wall as agentic workloads scaled token consumption. The more interesting question now is how fast enterprises move, and which workloads they bring on-prem first.
At CES, @AMD pulled the cover off the Ryzen AI Halo, a first-party mini PC built on the Ryzen AI Max+ 395 processor and aimed directly at the NVIDIA DGX Spark. Now we know it is priced at $3,999 with 128GB of unified memory and a 2TB SSD, with pre-orders expected next month (June). AMD also confirmed the next generation, the @AMDRyzen AI Max PRO 400 Series, code-named Gorgon Halo, as the follow-on platform.
The market AMD is chasing, local AI development and small-scale on-device inference, is only just forming. The prize is owning the developer on-ramp, the desktop box where builders prototype, fine-tune, and run models without renting cloud capacity. When a category is this young, a second credible vendor matters.
And AMD is showing up as a real competitor, not a token entrant. Shipping a first-party platform rather than leaving it to partners is a signal of intent. So is supporting both Windows and Linux with full ROCm. In a space where every developer workflow looks a little different, meeting people where they already work is a smarter early bet than it looks.
What about performance? On paper, the Ryzen AI Halo and DGX Spark are closely matched, and the early AMD numbers against Spark look strong. But those are vendor claims on a short list of models, and they need independent validation. Winning a benchmark is the easy part. The real test is performance across a wide and constantly shifting set of models, plus staying current as new models, workflows, and inference stacks land almost every week. That ongoing support is where the @NVIDIA CUDA ecosystem has a long head start, and it is the bar AMD has to clear.
Why does any of this matter in 2026? Agents.
Autonomous agents run continuously and consume far more tokens than chat-style interactions. Recent Signal65 research (https://t.co/dlVzuL1rAW) on the economics of agentic AI found agentic workloads burn roughly 4x to 15x more tokens than standard chat, and the trend points well beyond that. When consumption scales like that, per-token cloud pricing becomes a real line item, and owning local inference capacity stops being a hobbyist choice and starts being an economic one.
That brings us to the Ryzen AI Max 400. The CPU and GPU look like a measured step over the current part, so memory is the key difference. Moving up to 192GB of unified memory is the spec that counts, because memory capacity decides which models you can actually fit and run locally. That is a significant jump over the 128GB ceiling on both the current Halo and the DGX Spark.
AMD is aiming for the third quarter of 2026 for the Ryzen AI Max PRO 400 platform, so the bigger unknown is price. The first-party Halo at $3,999 undercuts the $4,699 Spark, though not by the wide margin some expected, and Ryzen AI Max 400 pricing has not been disclosed. In the current memory market, that is a genuine variable, and hitting that third-quarter window is not a given either.
Local AI is shifting from a curiosity to a real platform decision, and AMD just made it a two-horse race. Are you planning to run inference locally in 2026, or is the cloud still the default for your team? I would like to hear how you are thinking about it.
Most enterprise AI deployments are still cloud-first. That makes sense for bursty workloads, but persistent agents could change the calculation. When inference runs continuously, infrastructure pays itself back faster than most procurement timelines assume.
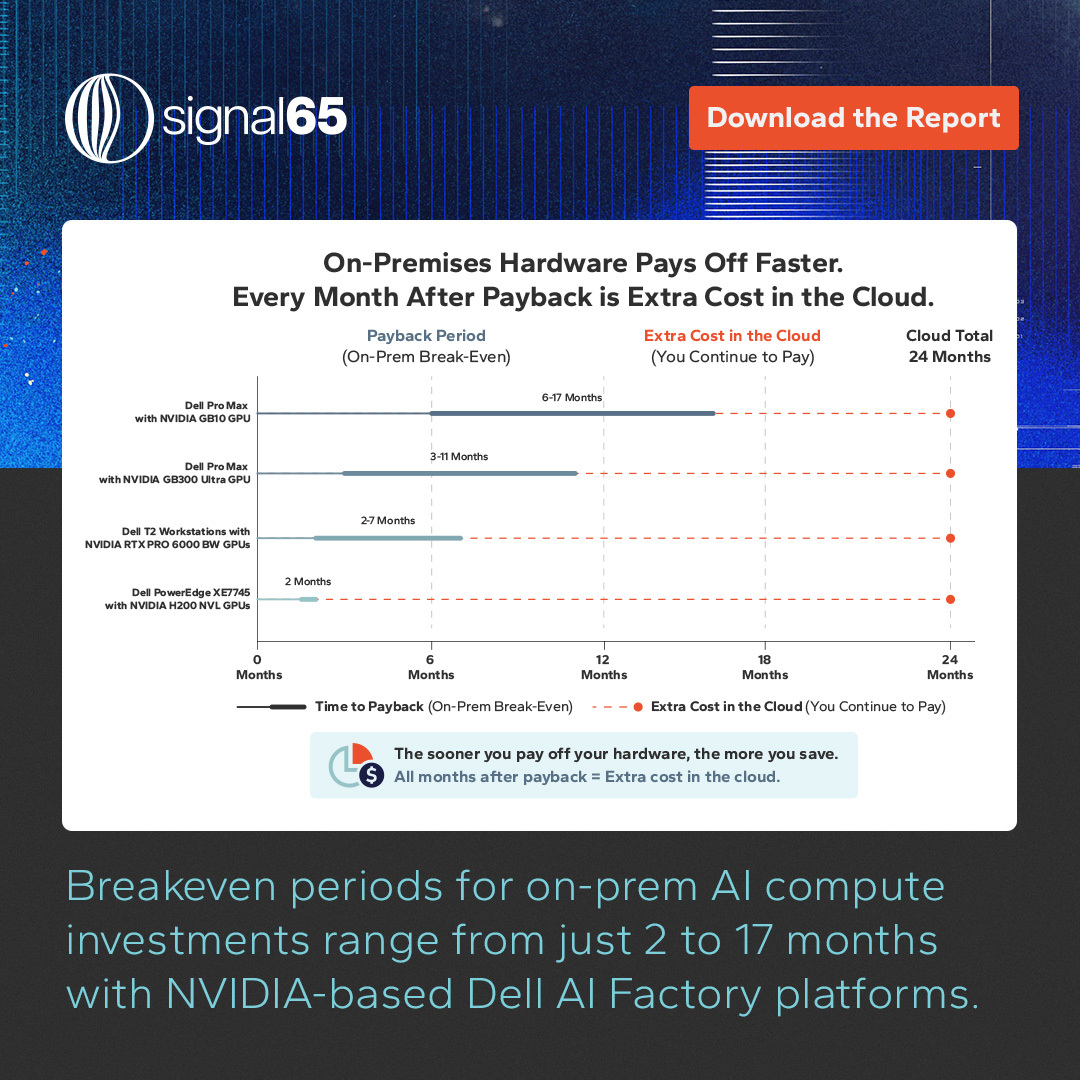
Across the @Dell AI Factory with @NVIDIA portfolio, we modeled breakeven against equivalent cloud API spend at every tier:
➡️ Dell PowerEdge XE7745 with NVIDIA H200 NVL GPUs, 2 months
➡️ Dell T2 Workstations with NVIDIA RTX PRO 6000 BW, 2 to 7 months
➡️ Dell Pro Max with NVIDIA GB300, 3 to 11 months
➡️ Dell Pro Max with NVIDIA GB10, 6 to 17 months
Every month past breakeven is cloud spend you aren't paying.
Full report: https://t.co/1qaEilIWH1
$NVDA CEO Jensen Huang to $DELL CEO Michael Dell “We have now entered the era of useful AI.”
Reiterating my endless droning on about just how early it is for AI. We have literally just hit the point where it is beginning to do useful things.
So. Damn. Early. 👏🏻🚀
The economics of persistent AI agents look different from chatbot workloads. Always-on agents consume orders of magnitude more tokens, and per-token cloud pricing isn't built for that pattern.
Our report: https://t.co/1qaEilIWH1
The most striking case in our analysis came from software development workloads. One @Dell Pro Max with @nvidia GB300 workstation delivered 87% lower cost than the equivalent cloud API spend and saved $926K over two years. That is one workstation, under a desk, doing the work of a $1.06M cloud bill.
The full report covers two more workload profiles and scales up through the Dell workstation portfolio to PowerEdge.
Persistent AI agents don't consume tokens like chatbots do. They run continuously, generate at least 4x to 15x more tokens than single-turn interactions we've gotten used to, and autonomous agents may push that closer to 1000x. It fundamentally changes the math on token production, and on-prem compute vs cloud APIs.
We modeled three persistent agent workloads on @Dell AI Factory with @nvidia infrastructure vs. cloud over a two year period. What we found:
➡️ On-prem reduced costs by 28% to 90%+ across all workloads
➡️ Dell Pro Max with NVIDIA GB300 Ultra delivered 87% lower cost for software development, $926K in two-year savings from a single workstation
➡️ Most platforms broke even in under a year, some in as few as 2 months
➡️ The portfolio scales from desktops handling 8 agents to PowerEdge systems supporting 18,000+
Full report: https://t.co/1qaEilIWH1
When infrastructure spreads out, control can thin out. @Signal_65 and HPE explore how teams can bring consistency, visibility, and security back across data centers and the edge. https://t.co/dEz2iOHO5u
Arm reported Q4 FYE26 results are strong, but the forward signal that is most interesting is in the data center business with AGI.
Revenue of $1.49B, up 20% YoY, the highest quarter @Arm has ever had. EPS of $0.60 beats consensus. Q1 FYE27 revenue guide of $1.26B goes above the street estimates.
The bigger story is the Arm AGI CPU, which now has more than $2 billion in customer demand across FY27 and FY28. That figure has more than doubled since the launch announcement just 5 weeks ago.
The royalty side is moving in lockstep with data center royalties more than doubled YoY. Arm now holds roughly 50 percent of CPU compute share among top hyperscalers (based on Arm statements). Google announced Axion hosts in the new TPU8t and TPU8i, NVIDIA unveiled Vera at GTC, and AWS reported its custom silicon business, including Graviton, at a $20 billion+ annual run rate.
Arm has crossed from IP licensor to vertical compute platform. The competition from x86 to Arm in AI infrastructure is no longer a forecast, it is the operating reality of the hyperscaler buildout.
Curious how investors are weighing the AGI CPU ramp against the platform royalty engine. Both vectors are working at the same time and that combination is rare in this market.
In our latest Lab Insights report, commissioned by Microsoft, Signal65 found that @Windows 11 PCs starting $150 below the MacBook Neo delivered more performance AND up to 56% longer battery life in Procyon Office Productivity testing.
Performance and endurance are usually framed as a tradeoff. Our testing showed Windows buyers don't have to choose, and eligible US college students can layer on a $500+ Microsoft bundle that adds even more value.
Read the full report for benchmark methodology and system configurations. https://t.co/Ufc2X8yEa2
I've been listening to the analysts and leaders at silicon companies talk about agentic AI driving more CPUs in the CPU:GPU ratio, and it's something we have seen coming for quite a while now, even in our own @Signal_65 testing. But something to keep in mind 1/4