Good alerts start as plain-language intent:
"Tell me when checkout errors stay high after a deploy."
With SigNoz MCP, your coding agent can help turn that into an alert workflow you can review before enabling.
Find the full use case doc below 👇
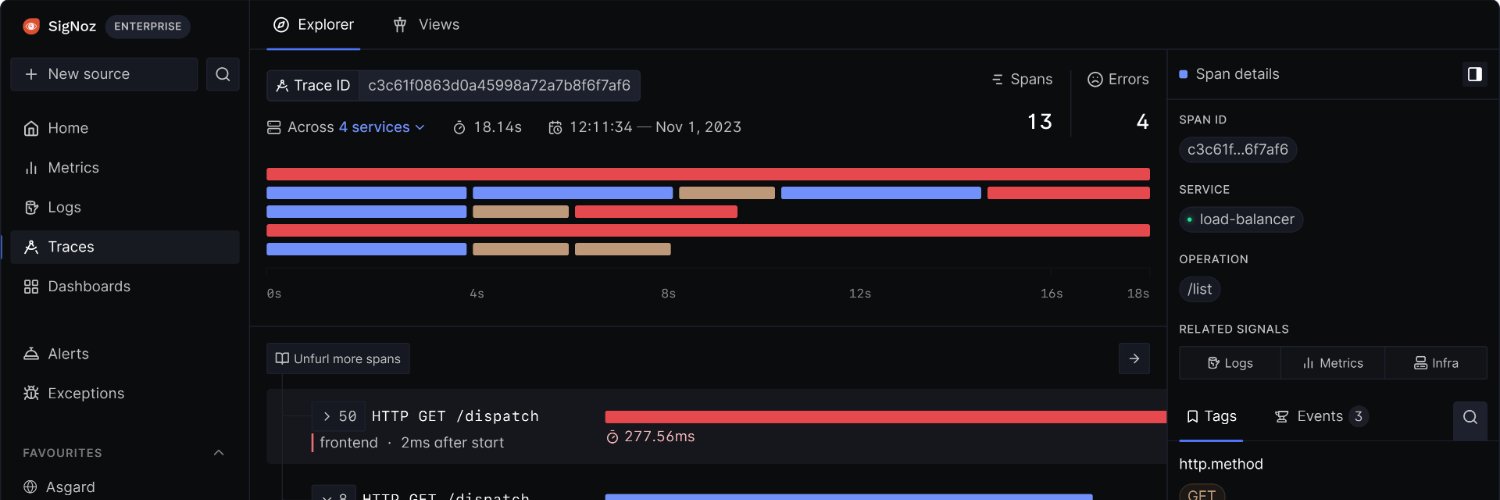
Dashboard creation should start with the question you want answered.
With SigNoz MCP, describe the dashboard in natural language and let your coding agent turn that intent into a SigNoz dashboard workflow.
Find the full use case doc below 👇
Most teams use observability after production breaks.
SigNoz MCP makes it useful earlier: while building a feature and right after deploy.
Catch slow spans before shipping. Validate errors and latency after release.
A green deploy is only half the story.
With SigNoz MCP, ask your coding agent what changed after release: error rates, latency, affected services, and signals worth checking before you call the deploy healthy.
Find the full use case doc below 👇
Edition #36 of Observability Real Talk is live!
This one's a real customer build: Leo Blondel (CTO, 3-engineer startup) wired Claude Opus into his stack via the SigNoz MCP server.
3 weeks live → 0 false positives.
Link in comments!
Performance work should not always start after users feel it.
With SigNoz MCP, your coding agent can use observability data to find slow spans, expensive paths, and likely bottlenecks while you are still in the development loop.
Find the full use case doc below 👇
"Errors are up" is a symptom, not a diagnosis.
With SigNoz MCP, your coding agent can inspect the spike, narrow it to the affected service or endpoint, and help point the team toward the likely cause.
Find the full use case doc below 👇
SigNoz Cloud is now available on AWS Marketplace.
For AWS teams, this means easier procurement and billing through your AWS account.
Same OpenTelemetry-native observability for traces, logs, metrics, dashboards, alerts, and exceptions.
On-call handoff should not mean "please reread every dashboard, alert, and trace."
With SigNoz MCP, your coding agent can turn live observability context into a focused handoff brief: what happened, what changed, and what to check next.
Find the full use case doc below 👇
Static dashboards are great for recurring questions.
Incidents create temporary questions.
With SigNoz MCP, your coding agent can help spin up an incident-specific dashboard around the affected services, endpoints, and signals.
Find the full use case doc below 👇